Machine learning in finance: A comprehensive guide
Exploring similarity search and graph embedding for finance.
This blog was authored by Dan Barcklow and Pranav Dulepet, Machine Learning Manager and Tech Incubator Intern on Capital One's Applied Research team
Our team worked on a service that provides enterprise graph building, graph querying, graph representation and similarity search on graph representation outputs (i.e., graph embeddings). This tool is helpful for detecting fraudulent activity and solving other business problems. This article provides a brief overview of the similarity search methods explored.
Data modeling and financial transactions

Machine learning and deep learning influence nearly every industry, a prime example being the financial domain. Data science and machine learning enable detailed analysis and modeling of complex financial systems, with some key examples being fraud detection, risk assessment and algorithmic trading. On a high level, machine learning can be used in all of these cases as it helps us derive relationships and extract patterns from data.
My Capital One Tech Incubator intern experience
The Capital One Tech Incubator, created in 2018, provides students with machine learning and data science experience. Throughout the program, interns apply what they learn in the classroom and more to real-world Capital One applications in data science and machine learning. Interns, grouped by interest into teams, are paired with a Capital One technology associate to guide their projects. I worked as an intern on the Enterprise Graph Services Team, learning about how Capital One integrates graph embeddings into their workflow. As a financial institution, Capital One deals with graphs and vectors from credit card transactions to other business and customer use cases.
This article walks through many of the ML tools used I learned about during my internship with Capital One, including: Graph embeddings, node embeddings, similarity search and NMSLIB.
Graph embeddings explained
Graph Embeddings are d-dimensional learned features that represent the different components and aspects of a graph. The overarching goal for graph representation methods is to distill the relevant graph information down to lower dimensional representations. For example, certain methods may be used to embed nodes and edges from a graph while others embed the entire graph. This article will focus on node embeddings.
Node embeddings explained
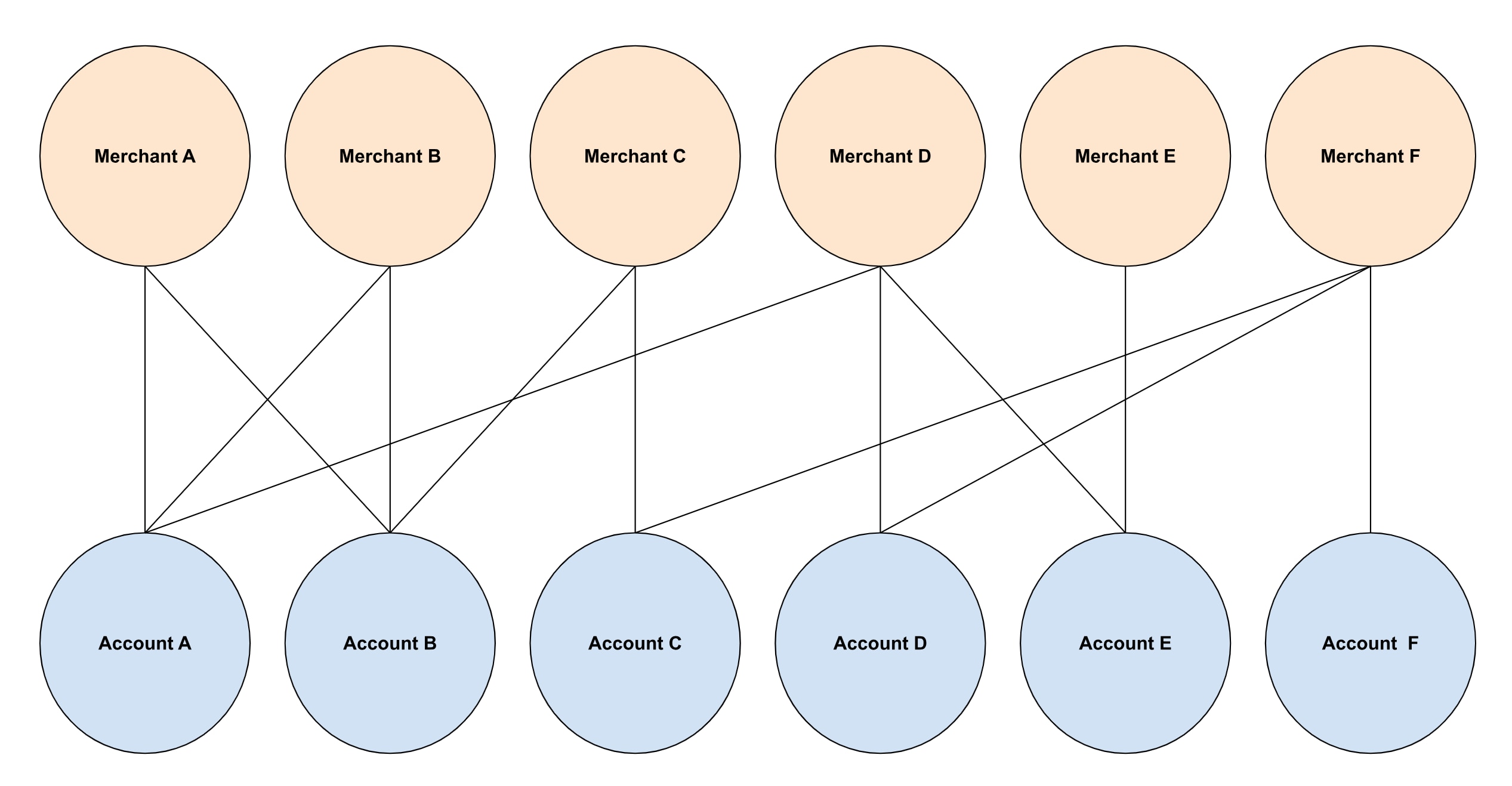
Node embeddings encode the structural (e.g., node connectivity) and semantic (e.g., node features) information, which enables the application of traditional machine learning techniques. In a simple transaction graph, each node represents an entity, such as an account or a merchant. Node embeddings allow each node to be mapped to a continuous vector space where the distance between nodes reflects their similarity. At a high level, account nodes collocated in the embedding space share spend patterns with a mutual set of merchants.
Similarity search explained
Similarity search is an example of a common analysis workflow to extract meaning from a set of points in a d-dimensional space through distance comparisons with a specified distance metric. Standard k-Nearest Neighbors (kNN) is the most common technique for similarity search, but the simplest implementation requires an exhaustive search against many (i.e., 106 or more) points and becomes computationally expensive and slow without additional algorithmic considerations. To perform kNN on many high-dimensional embeddings, I specifically explored the NMSLIB library, a popular toolkit for implementing similarity searches at scale.
NMSLIB (non-metric space library) explained
NMSLIB is an open-source library that provides a framework for performing approximate nearest-neighbor (ANN) searches. NMSLIB stands for non-metric space library and is designed to be a fast and flexible tool for navigating large high-dimensional spaces. The library provides several algorithms for ANN, including hierarchical navigable small-world graphs (HNSW). In HNSW, edges connect index vectors near each other to form a graph.
Then when searching, the resulting graph is partially traversed to find the approximate nearest neighbors to the provided query vector. This algorithm always visits the closest candidate to the query vector to inch toward the query's nearest neighbors. To select the vector from which the algorithm can start the traversal, it builds a hierarchy of graphs where the bottom layer contains all the vectors and a random subset of vectors from the layer immediately below is added to each of the layers.
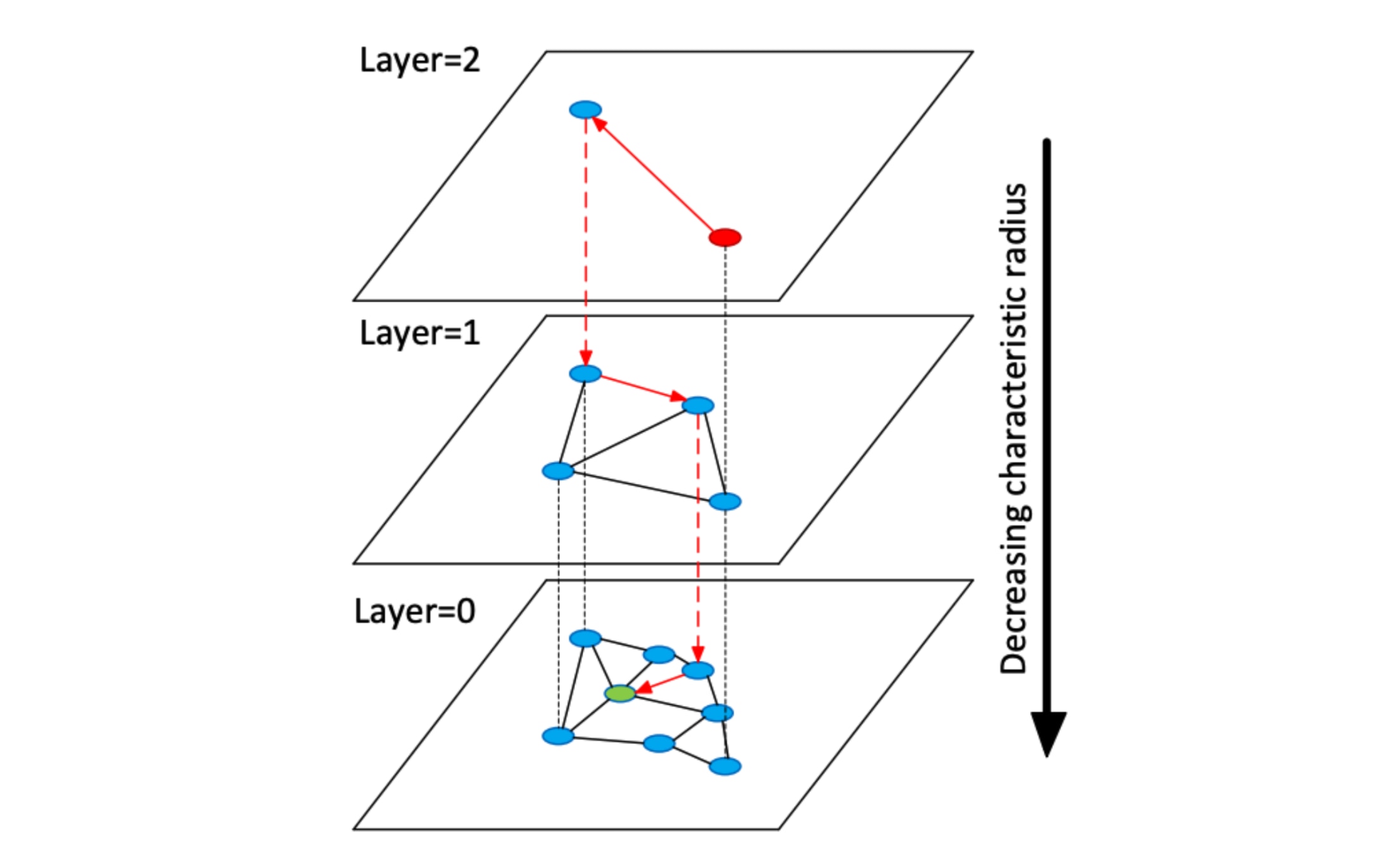
Illustration of HNSW. A red circle represents where the search starts at the top layer. Red arrows show the direction of the greedy algorithm from the entry point to the query. The query is represented as a green circle. (Reference: Y. Malkov and D. Yashunin, https://arxiv.org/pdf/1603.09320.pdf)
During the search, we start from a random vector in the topmost layer, partially traverse to find the nearest vector to the query vector in that layer and use that as the new starting point in the subsequent layers. Once we get to the bottom-most layer, we still perform a traversal, but instead, we keep track of the k-nearest neighbors visited along the way.
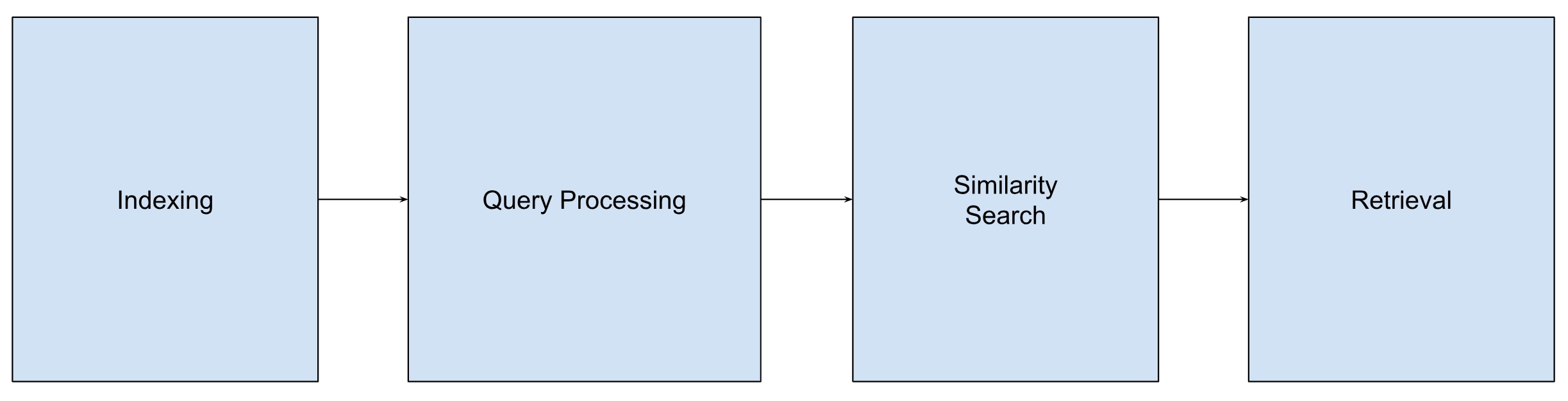
Here is an overview of how NMSLIB fits into the similarity search process:
-
In the indexing phase, we build a structure that efficiently retrieves similar items. Some examples of indexing methods are HNSW, sw-graphs and k-d trees.
-
In the query processing phase, NMSLIB receives a query vector and returns a set of vectors from the dataset most similar to the query.
-
In the similarity search stage, the approximate nearest neighbor search uses the indexing structure to prune the search space and only examine a subset of vectors likely to be similar to the query vector.
-
Finally, the retrieval stage returns the set of vectors most similar to the query. The HNSW indexing method uses recall to evaluate the result, which measures the proportion of relevant vectors retrieved among the k-nearest neighbors returned.
Similarity search and graph embeddings: Transforming financial insights
This article has provided a glimpse into the fascinating realm of machine learning in finance, specifically focusing on graph embeddings and similarity search methods. As demonstrated, the application of machine learning and deep learning techniques has become paramount in revolutionizing the financial industry, enabling comprehensive analysis and modeling of intricate financial systems.
The intersection of machine learning and finance continues to evolve, opening up new avenues for innovation and problem-solving. As demonstrated through the author's internship experience and exploration of graph embeddings and similarity search, these technologies are becoming indispensable tools for financial institutions in areas such as fraud detection, risk assessment and algorithmic trading. As the field of machine learning advances further, it promises to reshape the financial landscape, offering enhanced insights and decision-making capabilities for the benefit of both financial institutions and their customers.
---
This blog was authored by Dan Barcklow and Pranav Dulepet
Dan is a Machine Learning Engineering Manager within the Applied Research team at Capital One and sponsored this work as part of Capital One’s Enterprise Graph Services.
Pranav is an undergraduate Computer Science student at the University of Maryland - College Park, interning on the Applied Research team. He is passionate about machine learning and software development which led him to complete an internship with Capital One during the Spring 2022 semester where he worked in the Technology Incubator.


