Reproducible, distributed machine learning on Kubernetes
By Evan Curtin, Sr Associate Data Science, Card ML; Glen Pine, Sr Manager Data Science, Card ML; and Nick Groszewski, Sr Data Engineer, ML and Data Enablement

As data scientists and engineers, we all want a clean, reproducible, and distributed way to periodically refit our machine learning models. But sometimes we face obstacles in every direction. Perhaps your entire data lifecycle feels strung together, with team members each knowing only a piece of the puzzle, or with each teammate having their own custom workflow components. Maybe you’re wasting computing power and bumping into resource limits.
If any of the above sounds familiar, we can relate. We’re a platform data engineer, a platform data scientist, and an application data scientist who have encountered these problems. Here we offer some insights gathered while overcoming them through a distributed model refit workflow on Kubernetes. Our process involves transforming a large amount of data via Spark’s distributed computation engine, model training with H2O and tying everything together in an Argo workflow. The result is a pipeline that combines many disparate steps in a unified approach that can scale out to meet demand and down to nothing when not in use.
Benefits of this approach
To contextualize the benefits of the approach we’ll be outlining below, let’s start with a problematic machine learning workflow based on some common enterprise machine learning setups that we’ve seen. Suppose the workflow has roughly five steps:
- Grab, join, transform - In this step features are grabbed from a data store. Access is granted through tokens, users, roles, and so forth — i.e. its access is unstandardized. Once the data has been fetched, joins and transformations are run with Spark.
- SSH into EMR - Tribal knowledge dictates how to configure EMR.
- Train - The team conducts training in an extremely manual way (e.g. as in #2 above, by SSH-ing into EMR) using H20, Spark, or other frameworks.
- Save and analyze - Models get saved to S3, where their lineage remains unclear.
- Move to prod - Transform the saved object, compiling it into a jar, for example.
A team using a development pattern like the one above is likely experiencing a variety of problems, such as:
Non-reproducible machine learning pipelines
For starters, rather than being reproducible, the ML pipeline entails multiple, isolated steps, with knowledge distributed among the team or isolated in a single point of failure. The pipeline may not be understood in its entirety by most team members. Comparing experiments will be at best challenging, and at worst impossible.
Insufficient/wasted computing resources
Next, you may be facing a problem of having both too much and too little computing power. One big node may still be insufficient to train and tune a machine learning model; or, it may be much more than you need. (Generating matplotlib plots on a massive EMR cluster can be wasteful). This approach fails to take advantage of horizontal scaling and the power of distributed compute.
Highly manual processes
Finally, the process suffers from being highly manual. The team wastes time and effort as it carefully moves from one step to the next. If the work switches from one team member to another, or if a new person joins, significant ramp-up effort is involved. Even worse, each run through the workflow presents myriad opportunities for error.
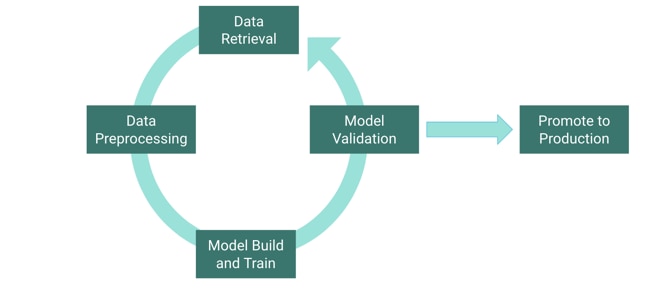
What we’re really trying to solve for is combining many disparate steps in the modeling lifecycle into reproducible pipelines. Leveraging a workflow engine and the power of distributed compute allows us to isolate each specific stage in the modeling lifecycle into its own discrete task and orchestrate them at a higher level.
Let’s dive into each of the components that allow us to build reproducible workflows on Kubernetes.
Leveraging distributed compute
As the volume of data grows, single instance computations become inefficient or entirely impossible. Distributed computing tools such as Spark, Dask, and Rapids can be leveraged to circumvent the limits of costly vertical scaling. While all of these tools can run on Kubernetes (see Dask Kubernetes, Dask Helm, RAPIDS K8s), we focused on Spark since it is widely used in the data processing space and we can deploy to Kubernetes without requiring developers to rewrite any of their source code.
Take, for example, the following PySpark code to train a gradient-boosted tree classifier:

Code sample taken from the Spark documentation at - https://spark.apache.org/docs/latest/ml-classification-regression.html#gradient-boosted-tree-classifier
This code can trivially be containerized and deployed to Kubernetes using the Spark Operator, as the following section will explore in more detail.
But Kubernetes has been available as an official backend scheduler since Spark 2.3, and there are examples of running Spark jobs directly on Kubernetes. The Spark Operator extends this native support, allowing for declarative application specification to make “running Spark applications as easy and idiomatic as running other workloads on Kubernetes.”
The Kubernetes Operator pattern “aims to capture the key aim of a human operator who is managing a service or set of services.” Given the overhead of managing a distributed compute engine, automating away as much of the maintenance as possible was crucial, especially when devising a pattern for analysts and data scientists who may not be as familiar with Infrastructure as Code or Spark cluster management on Kubernetes.
Spark Operator architecture

Image taken from the Spark documentation at - https://spark.apache.org/docs/latest/running-on-kubernetes.html#how-it-works
The image above shows the architecture of the native Kubernetes Spark scheduler. Clients interact with the Kubernetes’ API server through the use of spark-submit, passing the configuration and code for the Spark job to run. A Spark Driver Pod is spun up by the API server, which launches the requested amount of executors to run the full Spark job. An example of a spark-submit submission can be found below:


Image taken from Google Cloud Platform GitHub https://github.com/GoogleCloudPlatform/spark-on-k8s-operator/blob/master/docs/architecture-diagram.png
The Spark Operator builds from these foundations, adding Custom Resource Definitions (CRDs) as an extension to the native Kubernetes API specification. A user can specify a SparkApplication or ScheduledSparkApplication manifest and submit it like any other Kubernetes manifest, such as a Pod or Service. The Spark Operator Controller listens for create, update, and delete events on these objects and acts accordingly. The submission runner handles the spark-submit call to the Kubernetes API server on behalf of the user. The Spark Pod Monitor watches the running Driver and Executor Pods and sends updates to the Controller. Lastly, the Mutating Admission Webhook handles configuration for Driver and Executor Pods such as mounting external volumes and any other configuration not natively handled by the Spark Kubernetes backend.
If we look back to the gradient-boosted tree classifier code above, we can trivially containerize it and execute it as a SparkApplication, as seen below:

The Spark Operator natively handles things such as application restart and failure handling, as well as cleanup of resources.
Orchestrating the workflow with Argo Workflows
While it’s great that we have a solution for large-scale distributed compute jobs on Kubernetes, not every task requires that amount of compute. Especially when talking about the full modeling lifecycle, it is imperative to use the right tool for every job.
Enter Argo Workflows.
Argo Workflows are “An open source container-native workflow engine for orchestrating parallel jobs on Kubernetes.” Argo Workflows define each node in the underlying workflow with a container. Multi-step and dependent tasks can be combined together as a DAG (Directed Acyclic Graph). This project is implemented as a Custom Resource Definition, making it Kubernetes-native and giving it the inherent horizontal scalability of Kubernetes at its core.
One of the largest advantages to using Argo Workflows over other workflow management solutions is the ability to use the right tool for the task at each step. Using containers at each node allows for each step to have its own isolated dependencies from the rest of the workflow. In this way, we can begin to combine the normally disparate technologies across the entire modeling lifecycle into a single, reproducible, scalable workflow.
Utilizing Argo Workflow’s flexibility
One of the reasons for the difficulty in translating a research model into a production ready model is the heterogeneity of the toolchains used between data science researchers and production operations teams. In our case, we had a production Java codebase that would be used to serve the model to customers, but all of the data science code was written in Python. In order to bridge the gap, we’ve used the H2O library’s capability to export a model trained in Python to Java code. Any modifications to this process would require a data scientist to modify code in an unfamiliar programming language and environment. Argo Workflows enable us to package this step into a single component, and isolate the configuration for this step from all other parts of the workflow:
Argo Workflow template for converting an H2O MOJO to a Java library

Instead of downloading both Maven and Java and figuring out the correct versions of everything to run, a data scientist only needs to pass in a trained model artifact to this Argo Workflow step. As part of the package’s test suite, we pass in a bunch of example predictions to verify that the model is producing the same results in the packaged code as it did at model training time. We’ve effectively converted the manual process of configuring and packaging a model into a function. Since we’re using Argo Workflows for everything, we can run this step after the model training has finished and we automatically get a packaged model library every time we train a new model. This allows us to use our packaged function to analyze our model, so we can be confident that our analysis is not invalidated by some translation error.
As this functionality has been pulled out into an Argo WorkflowTemplate, we can reuse this across multiple different Argo Workflows easily.

Leveraging Kubernetes scaling in Argo Workflows
One other huge advantage to using Argo Workflows is its built-in capability to manage Kubernetes resources from within the workflow itself. Using this functionality allows us to include SparkApplications defined above within the larger context of an Argo Workflow, giving the benefit of distributed compute where needed. This inherent parallelism of Argo Workflows also allows us to run multiple trials at once, either within a single workflow or across multiple parameterized workflows.

But Wait, what about Kubeflow?
It’s clear that we’re not the only people who have had to solve this problem. Those more familiar with the Kubernetes machine learning ecosystem might wonder how these tools differ from Kubeflow. Fortunately, they’re not different at all! “The Kubeflow project is dedicated to making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable. Our goal is not to recreate other services, but to provide a straightforward way to deploy best-of-breed open-source systems for ML to diverse infrastructures.”
Under the hood of Kubeflow Pipelines, Argo is used to orchestrate Kubernetes resources. Also, some of the training components are actually just operators, meant to be used in the same way as the Spark Operator. A few of these are the PyTorch, TensorFlow, and MXNet training operators. Kubeflow very nicely combines all of these different tools together into a coherent platform for end users to interact with.
Conclusion
The world of cloud computing with containerized applications has given rise to a variety of new data lifecycle challenges for model creation and refit. However, this same paradigm has created new patterns for overcoming these challenges. Here we’ve offered our solution for distributed compute and reproducibility, involving the Spark Operator and Argo. Although those tools may work for you as well, ours is just one of many possible solutions. Rather than advocating for specific tools, our aim here has been to use an example to illuminate a generalized approach to distributed machine learning on Kubernetes.
Resources
- Argo Workflows: https://argoproj.github.io/argo
- Spark Operator: https://github.com/GoogleCloudPlatform/spark-on-k8s-operator
- Kubernetes Operator Pattern: https://kubernetes.io/docs/concepts/extend-kubernetes/operator/
- KubeFlow: https://www.kubeflow.org/docs/
- KubeFlow Pipelines: https://www.kubeflow.org/docs/pipelines/overview/pipelines-overview/
- PyTorch Operator: https://www.kubeflow.org/docs/components/training/pytorch/
- TensorFlow Operator: https://www.kubeflow.org/docs/components/training/tftraining/
- MXNet Operator: https://www.kubeflow.org/docs/components/training/mxnet/