Conquering statefulness on Kubernetes
Containerization has revolutionized the way we think of application development.
Containerization has revolutionized the way we think of application development as a whole. There are many benefits: consistent environments between development and production, isolation from other containers using shared resources, portability between cloud environments, rapid deployments. The list goes on and on. However, you can’t expect to have all of these benefits without certain tradeoffs. The inherently ephemeral nature of containers is at the core of what makes containerization great; immutable, identical containers that can be quickly spun up in a flash. But there is also a downside to the ephemeral nature of containers; lack of persistent storage.
Enter Kubernetes.
Persistent state is normally large and difficult to move; much like having to rack additional storage to SAN devices in data centers. This concept is vastly different than the idea of containers being fast and lightweight and easy to deploy anywhere needed at a moments notice. It’s for this reason that persistent state was purposefully left out of container specs, which opted instead for storage plugins; shifting the responsibility of managing persistent state to another party.
Kubernetes, the open source container orchestration framework, has stepped up and offered a solution to this problem.In this post I will walk you through the components of Kubernetes that help solve the problem of persisting state in a containerized environment.
The stateful problem
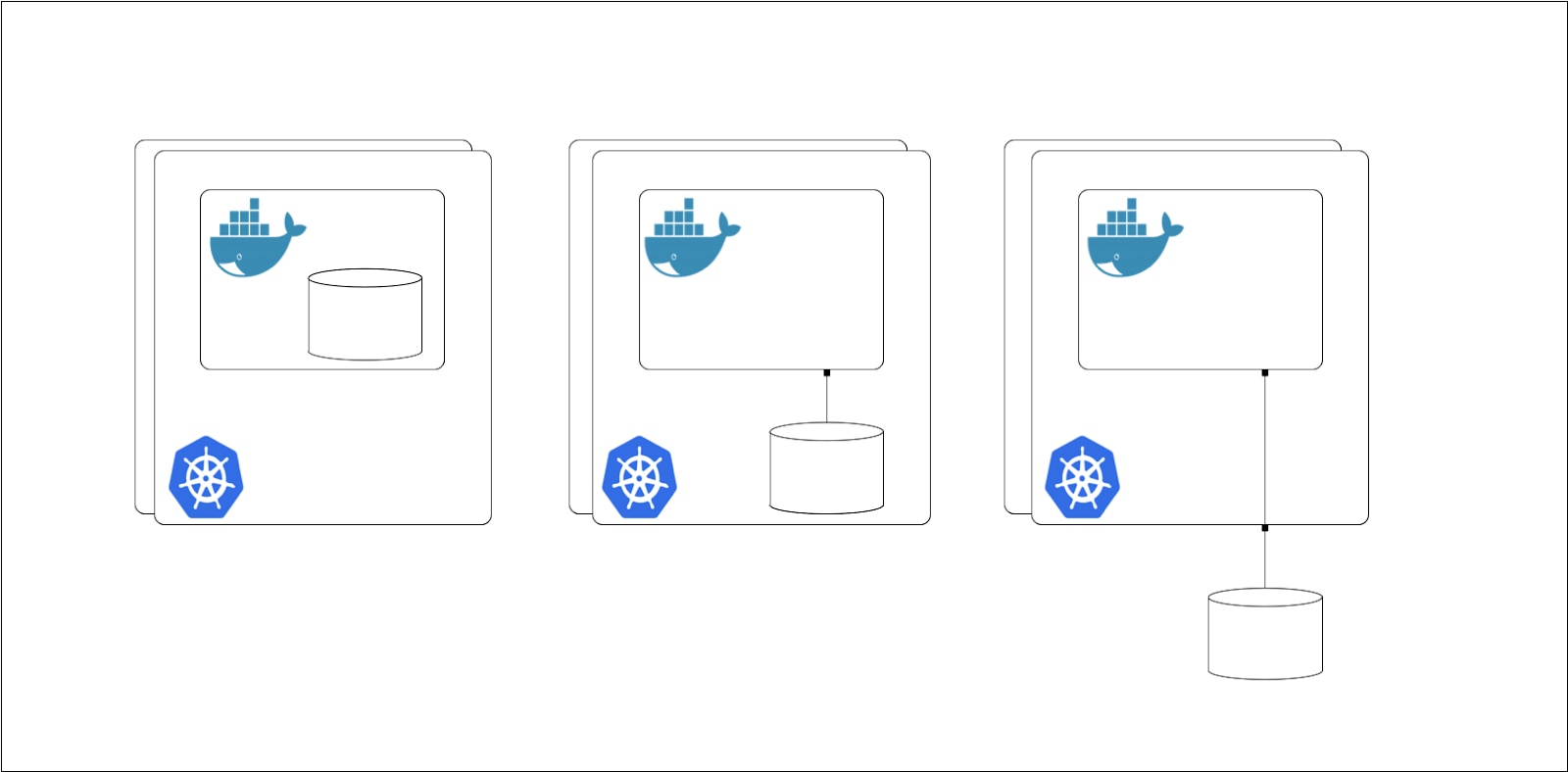
The biggest problem with managing persistent state is deciding where it should reside. There are three options available when deciding on where your persistent storage should live, and each has its own merits:
- Your persistent storage lives inside of the container. This can be useful if the data is replicable and non-critical, but you will lose data whenever a container restarts.
- Your persistent storage lives on the host node. This bypasses the ephemeral container problem, but you run into a similar problem since your host node is vulnerable to failure.
- Your persistent storage lives in a remote storage option. This removes the unreliability of storage on the container and host, but requires some careful thought and consideration into how you provision and manage remote storage.
When to think about state?
There are two key features of an application that require persistent state: the need to persist data beyond application outages and restarts, and the need to manage application state across the same outages and restarts. Examples of this type of application could be a database and its replicas, some sort of logging application, or a distributed application requiring a remote store.
But even these types of applications do not require the same level of persistence, as there are obviously varying levels of criticality for different applications. For that reason, I have come up with a short list of questions to ask myself when designing a stateful application:
- How much data are we trying to manage?
- Is starting from the latest snapshot enough, or do we need the absolute most recent data available?
- Does a restart from snapshot take too long, or will it suffice for this application?
- How easily can the data be replicated?
- How mission critical is this data? Can we survive a container or host termination, or do we need remote storage?
- Are different Pods in this application interchangeable?
Storage solutions
Many applications require data to persist across both container and host restarts, leading to the necessity of remote storage options. Luckily, Kubernetes has realized this need and provided a way for Pods to interact with remote storage: Volumes.
Kubernetes Volumes
Kubernetes Volumes provides a way to interact with remote (or local) storage options. These Volumes can be viewed as mounted storage that persists for the lifetime of the enclosing Pod. Volumes will outlive any containers that spin up/down within that Pod, giving us a nice workaround to the ephemeral nature of containers. An example of a Pod definition that leverages a Volume can be seen below.
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
— name: test-container
image: nginx
volumeMounts:
— mountPath: /data
name: testvolume
volumes:
— name: testvolume
# This AWS EBS Volume must already exist.
awsElasticBlockStore:
volumeID:
fsType: ext4 As we can see from the Pod definition above,the.spec.volumes section specifies the name of the Volume and the ID of the already created storage (an EBS Volume in this case). To use this Volume, the container definition must specify the Volume to mount in the .spec.container.volumeMounts field.
Some key points to remember when leveraging Volumes:
- Kubernetes provides many types of Volumes and a Pod can use any number of them simultaneously.
- Volumes only last as long as the enclosing Pod. When the Pod ceases to exist, so will the Volume.
- Persistent storage provisioning is not handled by the Volume or Pod themselves. The persistent storage behind the Volume will need to be provisioned in some other manner.
While Volumes solve a huge problem for containerized applications, certain applications require the lifetime of the attached Volume to exceed the lifetime of a Pod. For this use case, Persistent Volumes and Persistent Volume Claims will be useful.
Kubernetes Persistent Volumes and Persistent Volume Claims — Kubernetes Persistent Volumes and Persistent Volume Claims provide a way to abstract the details of how storage is provisioned from how it is consumed. Persistent Volumes (PVs) are available persistent storage in a cluster provisioned by an administrator. These PVs exist as cluster resources, just like Nodes, and their lifecycle is independent of any individual Pod. Persistent Volume Claims (PVCs) are requests for storage (PVs) by a user. Similar to how Pods consume Node resources such as memory and CPU, PVCs consume PV resources such as storage.
The lifecycle of PVs is comprised of four stages: provisioning, binding, using, and reclaiming.
Provisioning — Provisioning of PVs can be done in two ways: statically or dynamically.
- Static configuration requires a cluster administrator to manually create a number of PVs to be consumed.
- Dynamic provisioning can occur at the moment the PVC requests a PV without any manual intervention from the cluster administrator.
- Dynamic provisioning requires some up front configuration in the form of Storage Classes (which we will touch on in just a moment).
Binding — When it’s created, a PVC has a specific amount of storage and certain access modes associated with it. When a matching PV is available, it will be exclusively bound to the requesting PVC for however long that PVC requires. If a matching PV does not exist, the PVC will remain unbound indefinitely. In the case of dynamically provisioned PVs, the control loop will always bind the PV to the requesting PVC. Otherwise, the PVC will get at least what they asked for in terms of storage, but the volume may be in excess of what was requested.
Using — Once the PVC has claimed the PV, it will be available for use in the enclosing Pod as a mounted Volume. Users can specify a specific mode for the attached Volume (e.g. ReadWriteOnce, ReadOnlymany, etc.) as well as other mounted storage options. The mounted PV will be available to the user for as long as they need it.
Reclaiming — Once a user is done utilizing the storage, they need to decide what to do with the PV that is being released. There are three options when deciding on a reclamations policy: retain, delete, and recycle.
- Retaining a PV will simply release the PV without modifying or deleting any of the contained data, and allow the same PVC to manually reclaim this PV at a later time.
- Deleting a PV will completely remove the PV as well as deleting the underlying storage resource.
- Recycling a PV will scrub the data from the storage resource and make the PV available for any other PVC to claim.
An example of a Persistent Volume (utilizing static provisioning) and accompanying Persistent Volume Claim definition can be seen below.
apiVersion: v1
kind: PersistentVolume
metadata:
name: mypv
spec:
storageClassName: mysc
capacity:
storage: 8Gi
accessModes:
— ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
awsElasticBlockStore:
volumeID: # This AWS EBS Volume must already exist. Persistent volume
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mypvc
spec:
storageClassName: mysc
accessModes:
— ReadWriteOnce
resources:
requests:
storage: 8GiPersistent volume claim
The Persistent Volume definition specifies the capacity of the storage resource, as well as some other Volume specific attributes such as the reclaim policy and access modes. The .spec.storageClassName can be used to classify the PV as a certain class of storage, which can be leveraged by PVCs to specify a specific class of storage to claim. The Persistent Volume Claim definition above specifies the attributes for the Persistent Volume that it is attempting to claim; some of these being storage capacity and access modes. A PVC can request a specific PV by specifying the .spec.storageClassName field. A PV of a particular class can only bind to PVCs requesting that class; a PV with no class specified can only bind to PVCs that request no particular class. Selectors can also be used to specify a specific type of PV to claim; more documentation on this can be found here.
An example Pod definition that leverages Persistent Volume Claims for requesting storage can be seen below:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
— name: test-container
image: nginx
volumeMounts:
— mountPath: /data
name: myvolume
volumes:
— name: myvolume
persistentVolumeClaim:
claimName: mypvcWhen comparing this Pod definition with the earlier one utilizing Volumes, we can see that they are nearly identical. Instead of directly interacting with the storage resource, the Persistent Volume Claim is used to abstract away storage details from the Pod.
Some key takeaways about Persistent Volumes and Persistent Volume Claims:
* The lifecycle of Persistent Volumes is independent of the lifecycle of a Pod.
* Persistent Volume Claims abstract away the details of storage provisioning from storage consumption for Pods.
* Similarly to Volumes, Persistent Volumes and Persistent Volume Claims do not directly handle the provisioning of storage resources.
Kubernetes Storage Classes and Persistent Volume Claims
Kubernetes Storage Classes and Persistent Volume Claims provide a way to dynamically provision storage resources at the time of request, removing the necessity for a cluster administrator to overprovision/manually provision storage resources to meet demands. Storage Classes allow for cluster administrators to describe the “classes” of storage that they offer and leverage these “classes” as a template when dynamically creating storage resources and Persistent Volumes. Different Storage Classes can be defined according to a specific application requirements such as quality-of-service level needed and backup policies.
Storage Class definitions revolve around three specific areas:
- Reclaim policies
- Provisioners
- Parameters
Reclaim Policies — If the Persistent Volume is created by a Storage Class, only Retain or Delete are available as the reclaim policy, whereas manually created Persistent Volumes managed by a Storage class will retain whatever their assigned reclaim policy was at creation.
Provisioners — The Storage Class provisioner is in charge of deciding which volume plugin needs to be used when provisioning PVs (e.g. AWSElasticBlockStore for AWS EBS or PortworxVolume for Portworx Volume). The provisioner field isn’t constrained to just the list of internally available provisioner types; any independent external provisioner that follows the clearly defined specification can be leveraged to create a new Persistent Volume type.
Parameters — The last, and arguably the most important part, of defining a Storage Class is the parameters section. Different parameters are available to different provisioners and these parameters are used to describe the specifications for the particular “class” of storage.
Below you will find both a Persistent Volume Claim and Storage Class definition.
apiVersion: v1
kind: StorageClass
metadata:
name: myscz
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: “10”
fsType: ext4Persistent Volume Claim
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mypvc
spec:
storageClassName: mysc
accessModes:
— ReadWriteOnce
resources:
requests:
storage: 8GiStorage class
If we compare the PVC definition to the one above used in the statically provisioned use case, we’ll see that they are identical.
This is due to the clear separation between storage provisioning and storage consumption. When comparing the consumption of Persistent Volumes when created with a Storage class versus when created statically, we see some huge advantages. One of the biggest advantages is the ability to manipulate storage resource values that are only available at resource creation time. This means that we can provision exactly the amount of storage that the user requests without any manual intervention from the cluster administrator. Since Storage Classes need to be defined ahead of time by cluster administrators, they still maintain control over which types of storage are available to their end-users while also abstracting away all provisioning logic.
Key takeaways for Storage Classes and Persistent Volume Claims:
* Storage Classes and Persistent Volume Claims enable dynamic provisioning of storage resources to be utilized by end users, removing any manual intervention needed from a cluster administrator.
* Storage Classes abstract away the details of storage provisioning, instead relying on the provisioner specified to handle provisioning logic.
Application state
Persistent Storage is crucial when we think about state; where does my data live and how does it persist when my application fails? However, certain applications themselves require state management beyond just persisting data. This is seen most easily in applications that leverage multiple pods that are not interchangeable (e.g. a primary database Pod and its replicas of certain distributed applications such as Zookeeper or Elasticsearch). Applications such as these require the ability to assign unique identifiers to each Pod hat persist across any rescheduling. Kubernetes has offered this functionality through the use of StatefulSets.
Kubernetes StatefulSets
Kubernetes StatefulSets offer functionality similar to ReplicaSets and Deployments, but with stable rescheduling. This difference is important for applications that require stable identifiers and ordered deployment, scaling, and deletion. There are a few different qualities of StatefulSets that help to provide these necessary functionalities.
Unique Network Identifiers — Each Pod in a StatefulSet derives its hostname from the name of the Statefulset and the ordinal of the Pod. The identity of this Pod is sticky, regardless of what Node this Pod is scheduled to, or how many times it is rescheduled. This functionality is especially useful for applications that form logical “groups” of non-interchangeable Pods. Examples of these applications are database replicas and brokers in a distributed system. The ability to identify individual Pods is central to the advantages of StatefulSets.
Ordered Deployments, Scaling, and Deletion — Pod identifiers in StatefulSets are not only unique, but also ordered. Pods within StatefulSets are created sequentially, waiting for the previous Pod to be in a healthy state before moving on to the next Pod. This behavior extends to both scaling and deletion of Pods as well. No updates or scaling can happen to any Pod until all of its predecessors are in a healthy state. Similarly, before a Pod is terminated, all of its successors must already be shut down. These functionalities allow for stable, predictable changes to the StatefulSet.
An example StatefulSet definition can be found below.
apiVersion: v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx # has to match .spec.template.metadata.labels
replicas: 3
template:
metadata:
labels:
app: nginx # has to match .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
— name: nginx
image: nginx
ports:
— containerPort: 80
name: web
volumeMounts:
— name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
— metadata:
name: www
spec:
storageClassName: mysc
resources:
requests:
storage: 1GiAs seen above, the name of the StatefulSet is specified in .metadata.name which will be used when creating the enclosed Pods. This StatefulSet definition will produce threePods with names web-0, web-1, and web-2.
This particular StatefulSet is leveraging PVCs through the .spec.volumeClaimTemplates field in order to attach Persistent Volumes to each Pod.
Key takeaways for StatefulSets:
- StatefulSets name their enclosed Pods uniquely, allowing for applications that need non-interchangeable Pods to exist
- Deployments, scaling, and deletion of StatefulSets is handled in an ordered manner
While StatefulSets offer the ability to deploy and manage non-interchangeable Pods, there is still a problem: how do I find and use them. This is where Headless Services shine.
Kubernetes Headless Services
Sometimes our applications do not want or need load balancing or a single service IP. Applications such as these (primary and replica databases, brokers in a distributed application, etc.) need a way to route traffic to individual Pods backing a Service. Headless Services and Pods with unique network identifiers (such as those created with StatefulSets) can be leveraged together for this use case. Being able to directly route to a single Pod puts a lot of power back in the hands of the developer; from handling service discovery to routing directly to primary database Pods.
An example Headless Service can be found below.
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
spec:
clusterIP: None
selector:
app: nginx
ports:
— name: http
protocol: TCP
port: 80
targetPort: 30001
— name: https
protocol: TCP
port: 443
targetPort: 30002The attribute that makes this specification truly “headless” is setting .spec.clusterIP to None. This particular example uses the .spec.selectors field to specify how DNS should be configured. In this example, all Pods matching the selector of app: nginx will have an A record created to point directly to the Pod backing the Service. More information on how DNS can be automatically configured for Headless Services can be found here. This particular specification will create endpoints nginx-svc-0, nginx-svc-1, nginx-svc-2, which will route directly to the web-0, web-1, and web-2 Pods, respectively.
Key takeaways for Headless Services:
- Headless Services allow for direct routing to specific Pods
- Enables application developers to handle service discovery however they see fit
Conclusion
Kubernetes has made stateful application development a reality in a containerized world; particularly when it comes to managing application state and persistent data. Persistent Volumes and Persistent Volume Claims have built off of Volumes to enable persistent data storage, enabling data persistence in a mostly ephemeral environment. Storage Classes extended this idea further, allowing for on-demand provisioning of storage resources. StatefulSets offer Pod uniqueness and sticky identities, providing a stateful identity to each Pod that persists across Pod outages and restarts. Headless Services can be leveraged alongside StatefulSets to provide application developers the ability to utilize the uniqueness of Pods for their application’s needs.
This post has walked through the fundamental elements necessary in a stateful application in Kubernetes. As Kubernetes continues to evolve, functionality around stateful applications will continue to emerge. Knowledge of these fundamental elements will prove invaluable to stateful application developers and cluster administrators alike.
Related:

Critical Stack enables enterprises to run efficient and cost-effective containerized infrastructure while reducing risk. Click here to learn more about Critical Stack.


