Federated Model Aggregation: A new open source solution
Making federated learning more accessible to ML professionals, an open source project from Capital One.
In the field of machine learning (ML), there are a handful of specific challenges many ML professionals face:
- Needing high quality data to train our models
- Handling cases of systems and statistical heterogeneity as much as possible
- Minimizing costs
- Protecting data privacy
Federated learning (FL) can help alleviate some of these challenges. FL is an approach to generating ML models which decentralizes the training to edge-devices or distributed, private environments such as AWS accounts. As a result, data no longer needs to be centrally stored and can remain within the original environments from which the data originated.
FL has the potential to both improve model accuracy by having access to more data and better protect data due to the data being stationary and federated. That is why, at Capital One, we’re proud to launch Federated Model Aggregation (FMA) — an open source project from Capital One that helps easily deploy an existing ML workflow in a federated setting.
Introducing Federated Model Aggregation (FMA): An open source project from Capital One
To address some of ML’s biggest challenges, the machine learning team that created Data Profiler developed FMA. It’s an open source project that is built using agnostic design practices to the federated learning (FL) model training paradigm for the purpose of re-usability, so that users can deploy or enhance any component of the service. FMA is a lightweight, serverless solution that easily allows a developer to port an existing ML workflow and deploy it in a federated setting.
More plainly, FMA helps make FL more accessible to model developers so that more ML professionals can improve their models while keeping user data more secure by leaving it on the source device.

What exactly is FMA?
The FMA is a collection of installable Python components that comprise the generic workflow/infrastructure needed for federated learning. The primary objective is to convert a distributed model training workflow into a federated learning paradigm with very few changes to the training code. Each component can be used by changing a few settings within the components and deploying with a terraform-based deployment script.
The FMA is designed to abstract the complexities of deploying FL infrastructure allowing the model developer to focus on model development. Therefore, model developers can more quickly bridge the gap between research and production.
We focus on driving towards a serverless FL solution which is deployable across multiple production environments. While the initial solution focuses on AWS, the system is engineered so that the connections and interactions with its core capabilities are agnostic to the services powering which makes it more easily deployable within another's tech stack.
How FMA works
Federated Model Aggregation allows models from multiple sources to be combined into a single, global model. This can be done manually or through automation and allows training data to be distributed among many devices, speeding up training time and improving accuracy.
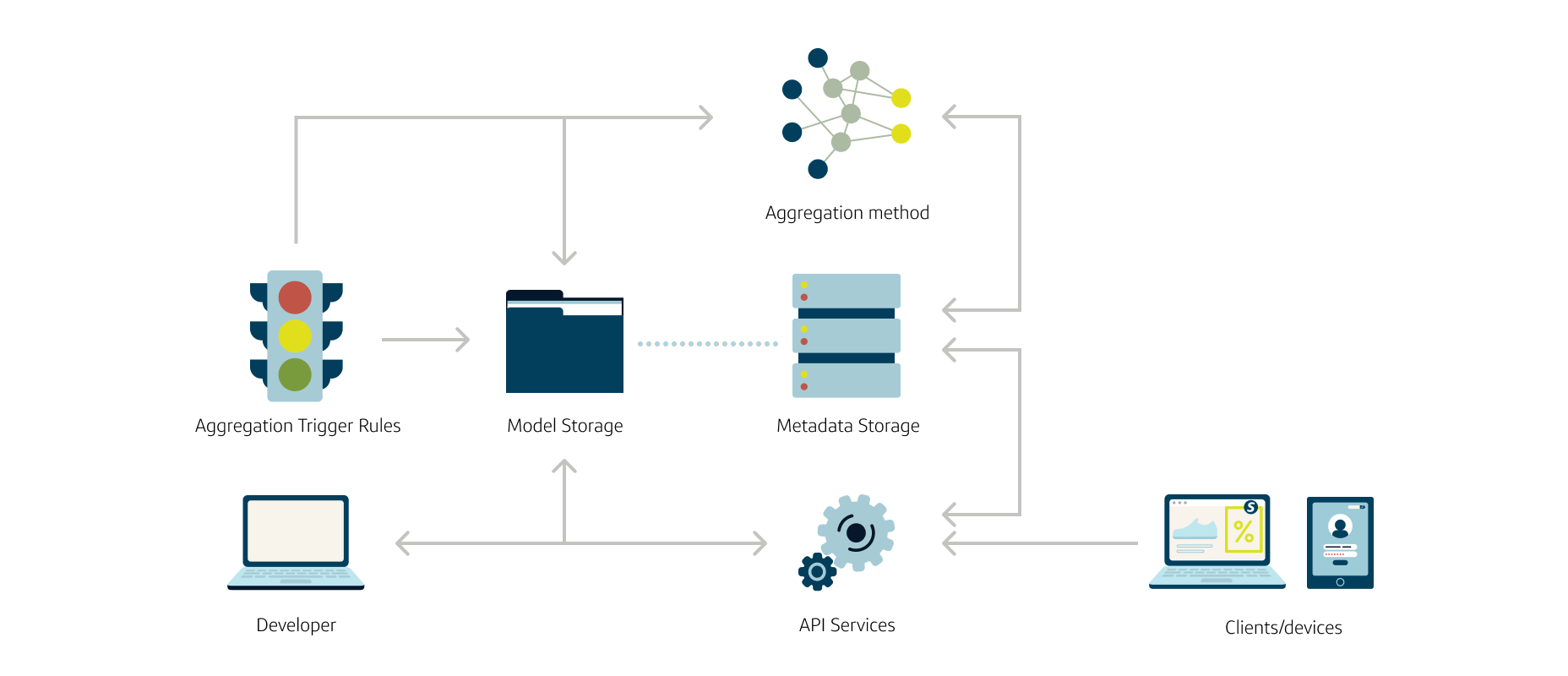
To train a model using Federated Model Aggregation, each device first trains a local model using its data. The local models are then aggregated to form a global model. The global model is then sent back to the devices and the cycle continues. Once the global model meets desired performance, it can then be deployed to production environments to make predictions.
The FMA library has 4 major focuses:
- Workflow and algorithms. Core components which contain both workflow orchestration to conduct model aggregation or service interaction and algorithmic techniques related to the aggregation process
- Connectors. The glue between the core library and infrastructure holding the model data and FMA metadata
- WebClients. Allow for the interaction between edge devices and the FMA
- Deployment. The deployment of both the serverless aggregation and the serverless API, currently utilizing AWS Lambda
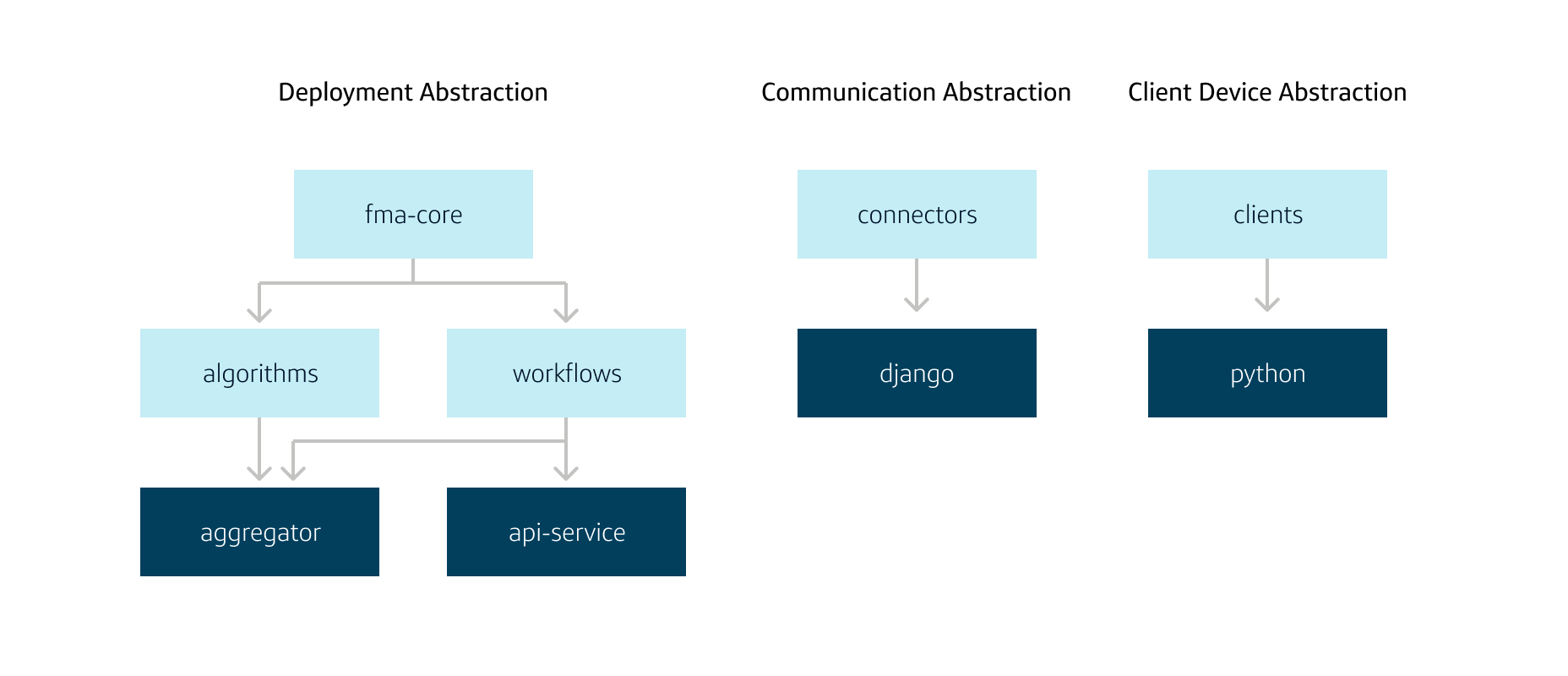
FMA code design (the current state of abstraction)
Examples of how FMA works
We have two examples of how FMA works on Github, listed below. These examples provide a more in-depth look at how to use the FMA library in an end-end client-server training workflow, via a local deployment.
Contributing and collaboration
Contribution and collaboration are important parts of sustaining an open source community. With FMA, we can make FL more accessible to the model development community. This will improve security practices for training new models with the potential to improve model performance.
If you would like to contribute or provide feedback on the FMA or our other open source projects, we look forward to hearing from you!
Thank you for the contributions from my colleagues on the Applied Research team: Taylor Turner (Lead Machine Learning Engineer), Tyler Farnan (Machine Learning Engineer), Jeremy Goodsitt (Machine Learning Engineer), and Michael Davis (Software Engineer).



