DevOps & the cloud: 4 steps to resilience

Wouldn’t it be great to never have to respond to a 3 a.m. on call alert again? Wouldn’t it be nice to trust that your system will always be available to your end users? If so, you’re not alone! By using Cloud services and DevOps principles, attaining this nirvana should be possible. I’ve been an avid DevOps technologist for many years, most recently architecting cloud-based systems for Capital One, and my experiences in the field have lead me to create a simple four-step framework to help enable resilience.
First, what is resilience?
Resilience is an outcome of a highly automated, well architected and well tested system, predicated on the following common characteristics:
- Adaptive—the ability to adapt to changing conditions.
- Self Healing—the ability to recover from failures autonomously.
- Predictable—the ability to consistently define responses to failures. This is a prerequisite to support the automation necessary to be adaptive and self healing.
To achieve these characteristics, resilient systems require the following:
- Investment—With respect to the labor and cost that is required to develop, test and deploy the resources and processes necessary for a resilient architecture. Infrastructure cost increases proportionally to the level of redundancy and data backup required.
- Automation—This is essential for both development and software defined operations.
- Monitoring—Monitoring in a continuous fashion is critical to enabling automated response and reliability.
- Simplicity—In general, simpler architectures have less ways in which they can fail.
Cloud resiliency
Cloud service providers such as Amazon Web Services (AWS) intrinsically enable various aspects of resiliency.
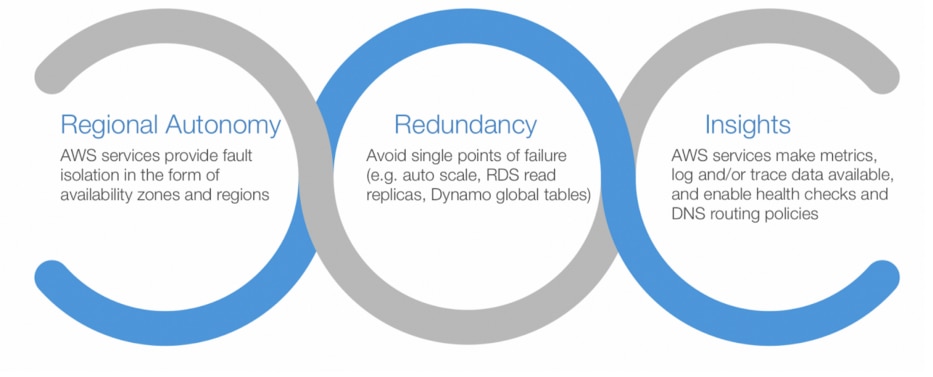
- Regional Autonomy allows systems to operate freely in a region without dependencies on other regions. Some cloud services are global, such as S3, yet regional autonomy still applies. For instance, S3 provides regional endpoints.
- Redundancy refers to the typically configurable capabilities of a service to enable differing levels of redundancy and data backups into durable storage.
- Insights are the ability to provide the data necessary to make automated decisions.
DevOps resiliency
In addition, DevOps principles enable aspects of resiliency:

- Resiliency testing refers to testing disciplines such as chaos engineering to inject faults and failures to define predictability. These tests are conducted like science experiments, in which you first make a hypothesis, and then run the test to see results. This also includes the testing of the monitoring and incident response solutions and processes.
- Monitoring in a continuous fashion of the full application stack, to include infrastructure, allows for holistic insights.
- Incident response relying on software defined operations allows for self healing.
Introducing the 4 steps of the resiliency framework
Together, Cloud technologies and DevOps provide the foundation of the following simple resiliency framework:
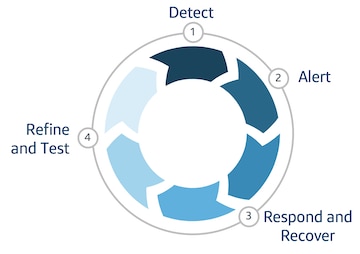
Step #1: Detect, DevOps Style
Let’s start at the top of the diagram. To detect causes of failures, it is first necessary to understand your dependencies. The dependencies that are often overlooked are the ones that we take for granted. DevOps emphasizes breaking silos; with this in mind, breaking silos between cloud infrastructure and applications can help define a well understood dependency chain.
Run Time Dependencies—Dependency analysis often focuses on the dependencies used during the run time of the application. Looking across both the infrastructure and application spectrum allows you to define a full set of dependencies, such as:
- Operations—Are there any dependencies to operate the application?
- Systems—Are there any dependencies on internal or external systems? How about libraries?
- Infrastructure—Are there any network dependencies? How about DNS?
- Region—From a regional autonomy perspective, are there any in-region dependencies? How about cross-region dependencies?
Build Time Dependencies—Sometimes this is overlooked. However, to auto-scale an application, or to failover an application in an active-passive or active-standby model, build-time dependencies often come into the picture. For example:
- Auto Scale—What are the auto-scale dependencies? Need an Amazon Machine Image (AMI)? Container image? Registry? Package repository?
- Bootstrap—Do you rely on bootstrap scripts? What are the dependencies in the scripts?
- Pipeline—Do you need an operational pipeline in order to deploy your application to your disaster recovery site? What does it depend on to operate?
Not all dependencies are equal with respect to the probability that a failure can occur and the impact that that failure can cause. Determine hard versus soft dependencies to identify your recovery approach. For which failures can you accept degraded experience? For which ones should you employ a circuit breaker mechanism? For which ones should you failover? What if there are cascading failures?
Once your dependency chains are identified, detect possible failures and limits to prevent or mitigate them. Failures can come in various forms:
- Man-Made—Such as deployment errors or misconfiguration. Deployment strategies such as canary deployment help ameliorate impact but it is important to define and quickly detect failures through monitoring. Rigorous non-brittle automated testing can help prevent issues through quality control.
- Cloud Services—While tending to be highly available, cloud services can sometimes incur outages or hit service limits. Soft limits can be raised, but hard limits such as the IP space available in a pre-sized subnet are harder to overcome unless planned for. Capacity needs to be thought about in a failover scenario; are enough instance sizes and IP space available in the DR region? Are cold start delays acceptable? Depending on the service, data replication times may vary.
- Security—Failures cover a wide spectrum, from certificate expiry to denial of service attacks. Attack vectors should be identified so that mitigation measures can be taken. Delivery teams should reserve development capacity for addressing security related issues, such as vulnerability mitigation.
- Stress—This includes unexpected load and can be tested and planned for in advance, with performance tuning conducted for an optimal experience. Applications respond to stress differently, depending on whether they are CPU, memory or I/O bound. This application characteristic also influences the types of monitors and alerts that are set.
- Chaos—Can reign despite our best efforts, whether a failure is due to a natural disaster or a random chance. Chaos engineering and testing can help mitigate this risk. Chaos at the infrastructure level versus the application level should be a consideration.
Step #2 Alert with a Cloud and DevOps mindset
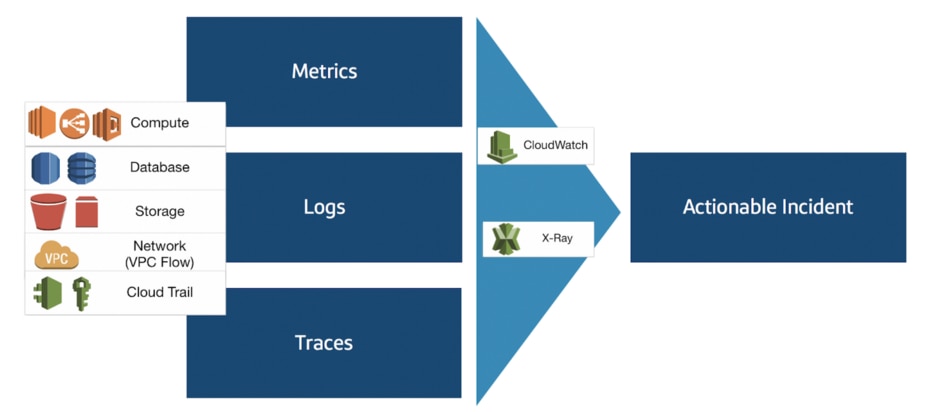
Moving clockwise on our framework diagram, our next step is Alert. Despite best efforts, failures will happen. To allow systems to be resilient, it is essential to employ a continuous monitoring strategy that also includes a data strategy: data collection, data ingestion, data analysis, data visualization and finally, meaningful alerts that can result in actionable incidents. From an AWS cloud perspective, monitoring data is provided across services throughout the application and infrastructure stack in the form of metrics, logs and traces. This can result in an overwhelming amount of data. Alerts responding to data need to be fine tuned or else noise will negate the fact that the system was monitored at all. It is critical that the DevOps team knows what actions to take based on an alert (and ideally, can automate those actions).
Step #3: Respond & recover using automation and the appropriate failover strategy
Continuing on to the next step in the framework, responding to a failure means determining the corrective course of action. Recovery is then executing that corrective course. Self healing is a result of automated response and recover, and relies on software-defined operations. Software-defined operations is an element of DevOps in which everything, including runbooks, is defined as code and treated as code through the application lifecycle management. Cloud enables this automation via presenting robust APIs.
The responses and recoveries for each system need to be defined based on that system’s requirements (e.g. SLOs/SLAs, RTOs/RPOs):

Failover strategies are generally active/active, active/passive, and active/standby, either within a region and multi-AZ or across multiple regions. Failover, graceful degradation, and availability need to be considered for the depth of automation and investment. In addition, session and state management need to be addressed. In general, stateless applications are preferable over stateful applications to reduce failure impact and to enable easier dynamic scaling.
Failover strategy will inform architectural considerations.

Step #4: Refine & test, achieving incremental improvements
Last but not least, we’ll cover the last step in the framework. The only way to have trust and confidence in your system is to continuously improve, in true DevOps spirit, your system and processes. This can be achieved by continuously refining your approaches based on testing as part of your regular application development lifecycle.
There are a number of DevOps best practices that can be applied to resiliency:

- Source Code Management—As stated above, software defined operations should be treated as code and follow application code best practices. In addition, feature toggles enable switching new functionality on and off to mitigate application code related errors.
- Continuous Integration / Testing—As stated above, resiliency and performance testing is paramount to enabling system predictability and fine tuning monitoring and alerting. Similarly, comprehensive testing across the test pyramid is essential to ensuring code quality. In addition, ethical hacking can identify opportunities to improve security.
- Continuous Deployment / Delivery (CD)—Dependencies are common in a CD process and as stated above, need to be considered for failure planning. Deployment strategies should be chosen based on the system requirements.
- Orchestration / Pipelines—As stated above, a data strategy enables intelligent alerting and efficient monitoring. Monitoring can be integrated into the pipeline and orchestration processes.
There are also a number of Cloud best practices that can be applied to resiliency:

- Autonomy—As stated above, cloud best practice is to be as autonomous as possible within a region. Take care to avoid cross-region dependencies if employing a cross-region DR strategy.
- Stateless—Stateless applications are easiest to scale, and there are many best practices around managing state with respect to failover strategies.
- Reliability—Cloud services themselves provide reliability SLAs but also enable your application to support reliability based on availability, redundancy, and backup and recovery options.
- Observability—As stated above, cloud services, although managed, provide insights such as metrics, logs and traces that can be utilized for continuous monitoring.
Achieving pragmatic resiliency
Resiliency will not happen overnight. The ability for cloud-based systems to recover and adapt from failure autonomously is possible but requires investment and continuous refinement. Many of you may already be using cloud technologies and DevOps principles to accelerate your release cycles. My hope is that you can now also apply them to resiliency.
This four-step resiliency framework is something you can use straight away to promote the right level of resilience in your system, based on your system’s requirements. Be sure to detect all of your dependencies, taking care to think through the ones you assume will always work. Then, alert intelligently based on efficient continuous monitoring. Next, identify the appropriate response to a failure condition. Then, define and automate recovery to normal operations. Expect to continuously refine and expand these approaches through comprehensive testing.



