The 3 R’s of SREs: resiliency, recovery & reliability
Using the 3 R’s as a lens to architect reliable applications
Defining resiliency, recovery, and reliability
- Resiliency is the ability to avoid or mitigate impact from an adverse event by quickly responding to, and fully recovering after, a failure. A focus on resiliency typically amounts to an emphasis on high availability. This allows for increased uptime.
- Recovery is the ability to restore service when failure occurs. As mentioned above, recovery is essential to strong resilience. Recovery directly impacts Recovery Time Objective (RTO), the time duration for an application to return to normal service levels after a failure, and Recovery Point Objective (RPO), the tolerance to data loss in terms of time duration. A focus on recovery typically leads to a well founded understanding of both design time and runtime dependencies due to the need to determine recovery methods for all possible failure points. This allows for the elimination of single points of failure and protection against potential failures and data loss.
- Reliability is the ability for a service to provide its expected functions. As laid out by Google for SRE, there are a number of concepts that go into reliability, ranging from technical execution to process and culture. A focus on reliability typically results in stability aligned to customer expectations. Note, stability in this context also includes security. A reliable system is one that is performant, secure, and meets service level objectives (SLOs), thereby instilling trust.
In my work as an architect for resiliency and site reliability engineering (SRE) at Capital One, the concepts of resiliency, recovery, and reliability are fundamental to architecting proven applications. Each concept builds on the other to provide a framework of architectural considerations through different lenses that together enable a more reliable product.
But first, let’s level our understanding on the 3 R’s and their definitions.
Using the 3 R’s to design a system
Next, let’s take a look at how to apply the 3 R’s to designing a system. Let’s assume it is a very simple AWS application like so, where the compute layer is a web tier servicing customer transactions, and the database stores transactional information:
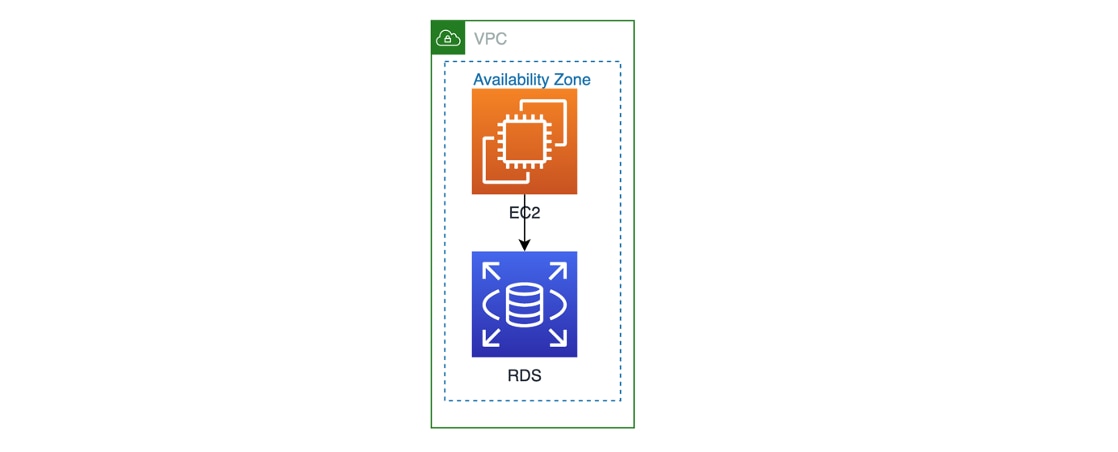
The resiliency lens
Applying the resiliency lens allows us to examine this architecture to consider the following:
- Can this application scale horizontally up or down in response to changes?
- Is there enough capacity in the services used to allow for scale? For example, do the subnets have enough free IP space? Are the AWS API rate limits well off from being hit?
Such considerations could lead to the following:

Our simple application has now been extended to be ‘highly available’:
- Elasticity - Our single EC2 is now part of an Auto-Scale group that allows it to scale horizontally up or down, and uses a load balancer as an ingress point for the application’s traffic. The load balancer can distribute traffic across the compute layer. Note, our VPC’s subnets are assumed to be sized appropriately and are not shown.
- Highly available data layer - Our single RDS instance is now multi-AZ capable, which allows for distributed reads as well as a recovery process via promotion of a read replica to the master in the event that the original master fails.
The recovery lens
Applying the recovery lens allows us to examine this architecture for additional considerations:
- What are the possible failure points and how will we know about them?
- Which failure points are critical and which are not?
- What can be done to recover automatically vs. gracefully degrade and perhaps require human intervention?
- What are the stages of recovery such that critical functionality is restored as quickly as possible, with full restoration afterwards?
- What is the failover strategy?
- What are the standard recovery procedures and have they been tested?
Such considerations could lead to the following:
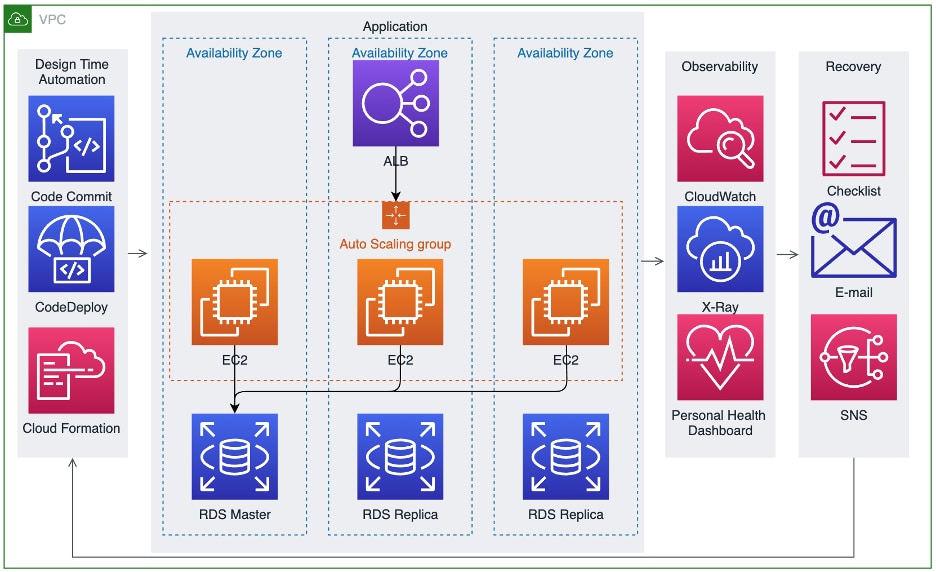
Our highly available, resilient application is now augmented by an ecosystem of tools and services to support recovery activity:
- Design time - Automation intended to support updates (patches, restore) to application code as well as infrastructure as code. For instance, Code Commit can store version controlled source code that can then be deployed as application updates via CodeDeploy onto infrastructure that was provisioned by CloudFormation.
- Observability - Enables the telemetry (logs, metrics, traces) needed to support insights for troubleshooting, debugging, and restoration activities. For example, CloudWatch can be used for metrics, logs and alerts, X-Ray for traces, and Personal Health Dashboard can help monitor AWS service issues.
- Recovery - Standard operating procedures and mechanisms to notify humans or trigger self healing actions. For example, checklists that are kept up to date as living documents can help guide procedures, email can escalate notifications to humans, and SNS can be used to trigger self healing actions. Note, self healing actions (e.g. automated scripts) are not shown.
The reliability lens
Applying the reliability lens allows us to examine this architecture for additional considerations:
- Is this the right level of investment for the expected customer need? In other words, what are the SLOs for the critical transactions? Does that require more redundancy? Is one region sufficient?
- What are the security implications and how can greater security be achieved?
- Based on the customer expectations, what are the performance requirements? Are the resources sized appropriately? Has performance testing occurred?
- Based on the customer expectations, is the architecture cost conscious? Have the resources been selected to maximize cost efficiency?
Such considerations could lead to the following:
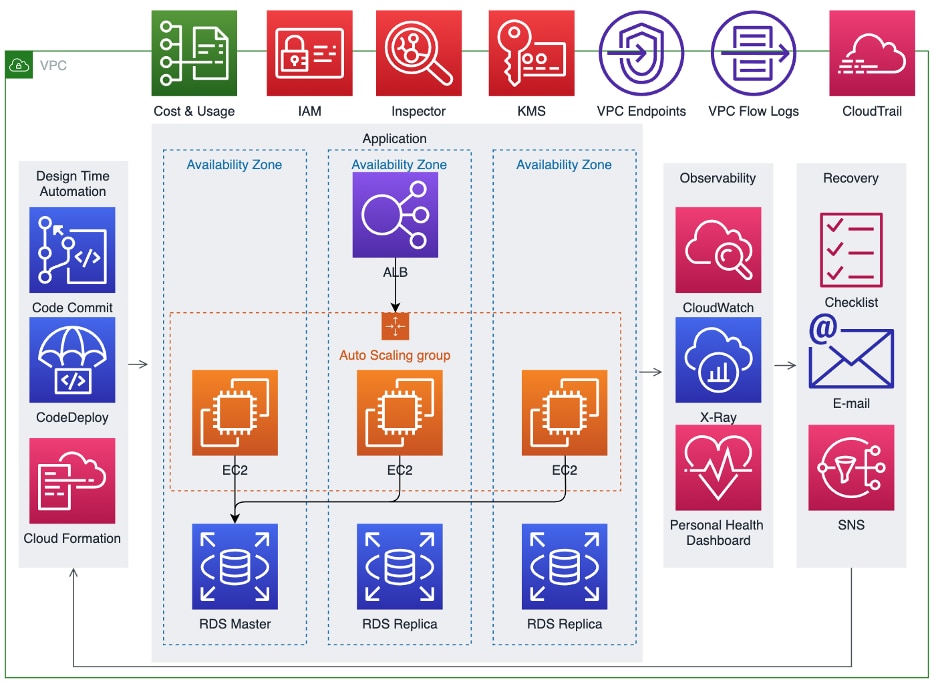
Our recoverable, resilient system is now augmented by an ecosystem of tools and services designed to improve reliability:
- Cost optimization - Enables ability to track cost usage over time to enable corrective actions for resource management.
- Security - Enables ability to secure infrastructure and provide guardrails. For example, IAM allows for identity and access management for least privileged access, Inspector allows for vulnerability detection and management, KMS allows for encryption at rest, and VPC Endpoints allow for traffic to AWS APIs to stay within the AWS backbone, and VPC Flow Logs and Cloud Trail enable review and detection of anomalies.
The 3 R’s in your applications
A thorough understanding of resiliency, recovery and reliability is essential to architecting reliable applications. Reviewing an architecture through each of these lenses allows for thinking through considerations to make comprehensive architecture decisions that affect high availability, restoration, and stability. Note that each decision has a tradeoff with cost and complexity. Thus, understanding and defining the actual customer expectations for reliability must be the starting point of any architecture striving to be resilient, recoverable and reliable.
For example, if the customer only expects one transaction to be highly available and reliable, then the investment in resiliency, recovery, and reliability should be on the components that support that one transaction, not all the components that comprise the application.
I encourage you to use the three lenses of resiliency, recovery, and reliability for all of your applications going forward.


