Using NATS for cloud native messaging systems

When building applications for the cloud, we often devote a lot of effort to breaking down our monoliths and building applications as small, containerized workloads that follow the 12 (or 15) factors for cloud native apps. With our focus narrowed on the internals of our codebase, we often leave discussions and designs about messaging in the backlog.
Messaging is the central nervous system of any large-scale distributed system. Whether we’re doing event sourcing or more simple work dispatch models, messaging is the glue that makes it all work. Without it, our wonderful distributed systems grind to a halt.
So how do we choose a message broker or messaging architecture for our application? It can feel pretty overwhelming, with a large number of options already available and new ones popping up every day.
At the far end of complexity and size, we’ve got Kafka. Kafka is often referred to as a distributed log store. It’s assumed that the messages published to topics in Kafka will persist for some time, and the concept of consumer groups allows messages to be distributed evenly among multiple instances of the same service. It is extremely powerful, but with that power comes great responsibility. Kafka is difficult to maintain, and has a steep learning curve for any team looking to skill up on the technology.
Another pretty common choice is RabbitMQ (or any AMQP-compliant broker, really). Rabbit is significantly lighter weight, but instead of using the concept of unique consumer groups, Rabbit takes the simpler approach of having clients consume queues. If a client doesn’t acknowledge a message, it’ll go back in the queue to be processed by another. Subtleties arise from this architecture, like allowing small time windows where it’s possible for two workers to receive the same dispatch, etc.
Even applications like Redis that don’t bill themselves as message brokers support pub/sub messaging. As you can see, the list of products and services around message brokering is vast and overwhelming.
Each of these products have their sweet-spots, places where they shine. Kafka shows some of its real muscle in large-scale message streaming and aggregation scenarios with persistent message logs. Rabbit thrives in environments that need simpler pub/sub functionality and enforced idempotency of work outside the confines of the message broker. Redis might even be a good fit if all your messaging clients are also talking to Redis for caching, and you don’t need to persist messages.
What if I want to really embrace the “central nervous system” idea, but I don’t want all the overhead of some of the other solutions? What if I want to be able to do traditional pub/sub, but also request/reply and maybe even scatter-gather, all while keeping things nimble and light? This is where NATS might be a better fit.
NATS is an incredibly fast, open source messaging system built on a simple, yet powerful, core. The server uses a text-based protocol, so while there are a number of language-specific client libraries, you can literally telnet into a NATS server and send and receive messages. NATS is designed to be always-on, connected and ready to accept commands. If you are old enough to know what a “dial-tone” is, then it’s worth mentioning that the NATS documentation likes to use that analogy for this design.
To get a feel for what it’s like to build applications on NATS, let’s walk through a couple common use cases.
Publish and Subscribe

Publish/Subscribe Pattern
In the simplest pub/sub model, we have a publisher that emits messages to a subject (although you may be familiar with the term topic instead). Any party interested in the messages on that subject subscribes to it. NATS will then guarantee at most once delivery. This means that messages sent from a single publisher are guaranteed to arrive in order, but order is not preserved across multiple publishers. I will save the “global message ordering” rabbit hole discussion for a future blog post as that debate can go on for days.
Suppose we are building a video analysis system that does facial recognition. As the analyzer makes progress on a large piece of media, we want to publish that progress to anyone who might be interested.
Since NATS is a text protocol, you can just issue a command that looks like:
PUB analysis.progress 55
{"hash": "abc56fghe", id: 12, progress: 32, faces: 78}
+OKWe tell NATS the subject (`analysis.progress`) and the content length (55 bytes). Then, a newline precedes and follows the actual data. If everything went well, NATS gives us back a `+OK` response. This is in stark contrast to some of the complex and even proprietary binary protocols used by some message brokers. That feeling we get when we can easily debug a RESTful service with the POSTman add-on is similar to how I feel when I can just telnet to my NATS server.
To subscribe, we create a subscription with a unique subject identifier (the subject ID is private to my connection):
SUB analysis.progress 50This means subject ID 50 represents the subscription to `analysis.progress`. Every subscriber will then get a message that looks like this:
MSG analysis.progress 50 55
{"hash": "abc56fghe", id: 12, progress: 32, faces: 78}As with the publication, the payload is separated from the metadata with just a simple newline/carriage-return combo. Each MSG protocol message contains the subject ID and the content length of the raw message.
To compare to some other brokers, in some cases we have to write administrative scripts to create topics ahead of time before our services can even start. Kafka requires explicitly created topics, as does Rabbit, whereas Redis and NATS let you create channels and subjects (their respective terms) on the fly.
This ability to create subjects on-demand turns out to be key to enabling request-reply semantics.
Request-Reply

Request — Reply Pattern
When we make RESTful service calls where we issue an HTTP request to a service and then get a reply, we’re using a traditional synchronous request-response pattern.
With many messaging systems, the request-reply pattern is often difficult or requires some very awkward and debt-heavy compromises. With NATS, request-reply is a fairly simple operation that involves supplying a “reply-to” subject when publishing a message.
Here is a breakdown of what happens in a NATS-based request-reply scenario where we want to ask for a list of videos in which a particular person appears. One important thing to keep in mind here is that we don’t know who or what we are asking for this information. All we’re doing is publishing our desire for an answer, and it is up to the system to satisfy our request. This loose coupling is incredibly empowering and gives us tremendous flexibility to upgrade and enhance the system over time without requiring “stop the world” releases.
- The publisher subscribes to a subject, e.g. `vididentify.reply`
- Publisher then sends a message on a subject like `vididentify.inquiry` and includes the name of the “reply-to” subject: `vididentify.reply`
- Publisher then waits some amount of time to receive a single response
- Publisher unsubscribes their interest in the vididentify.reply subject
- Publisher handles the response accordingly
To keep multiple concurrent requests of the same type from stepping on each other, and to ensure that whatever code handles the request replies to only the single request publisher responsible for that message, the “reply-to” subject is unique per request, often with a GUID suffix. For example, we might publish a video identification inquiry request as follows:
PUB vididentify.inquiry vididentify.reply.1b807ae3-bc12-42ab-b667-ccbd6c677745 25
{ "person_id": 4237249 }
+OKThis complexity is almost always dealt with under the hood by the language-specific client. For example, the Go client hides the creation of the reply-to subject entirely:
nc, err := nats.Connect(*urls)
if err != nil {
log.Fatalf("Can't connect: %v\n", err)
}
defer nc.Close()
// get payload...
msg, err := nc.Request("vididentify.inquiry",
[]byte(payload), 100*time.Millisecond)This publishes a request and waits 100 milliseconds for a reply. The Go library is hiding the reply-to subject detail from the developer. It is also hiding the subscription to and un-subscription from the reply-to subject. If the library you’re using doesn’t implement this for you, it’s pretty easy to create a wrapper that does.
Scatter-Gather
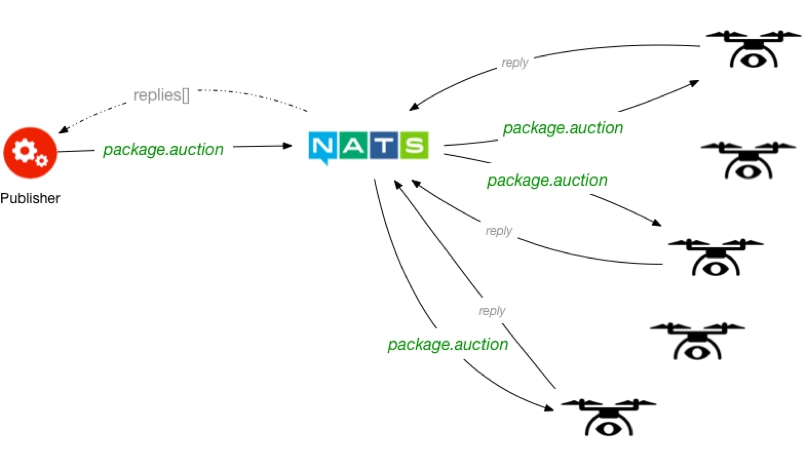
Scatter — Gather Pattern
In the scatter-gather pattern, a single publisher publishes a message on a topic to an unknown number of subscribers concurrently. It’s assumed that all of the listeners will then start working. The publisher then awaits replies from some or all of the subscribers and then aggregates the results somehow.
Let’s say I’ve got a few thousand drones that make up my fleet of package delivery devices. A request has come in to deliver a package and I’d like to pick which drone I want to use. Doing things “the old way”, I could iterate through the known list of all drones, interrogate each one individually over slow and potentially unreliable networks, and then when I am done with this loop I can finally make a decision based on remaining battery, weight capacity, and current location. This is slow, error-prone, and horribly inefficient.
To get around this problem, we can use scatter-gather instead. I will publish a message on the `package.auction` topic as follows:
PUB package.auction auction.d5e979a1-bf54-4baf-abdc-c91d451898c5.replies (content-length)
{ "pkg_weight": 12.5, "dest_address": {...}, "priority": "A"}
+OKNote that we’re still using a unique reply topic. This allows all of the listening drones in the fleet to reply to this specific auction request and not interfere with any other auction requests being handled at the same time.
Those that didn’t receive the message are obviously not good pick-up candidates, neither are those that don’t reply within our expected timeout period. Messages might come back looking like this:
MSG auction.d5e979a1-bf54-4baf-abdc-c91d451898c5.replies 50 (content-length)
{"drone_id":12345,"est_batt_remaining":12.34,"capacity":30, ...}We can then collect all the results we receive within a timeout period and decide from among the replies based on drone battery life, location, capacity, and how much battery it might have remaining at the end of the drop-off.
Summary
It isn’t its complexity that makes NATS so powerful, it is its simplicity. I have a particular fondness for the elegance of simplicity (the Japanese have a word for this, kotan) and NATS embodies this quite well. By keeping the underlying protocol simple, by focusing on performance and cloud native reliability, we can build up all kinds of really powerful messaging patterns without having to shoehorn in awkward functionality or carry the burden of tons of unused functionality in a larger product.
Hopefully this post has inspired you to not just take a look at NATS, but to evaluate the level of complexity your message broker needs with a critical eye. If you want to experiment with NATS, you can go grab the gnatsd docker image and start playing around with it.



