Serverless streaming & Eno's proactive-intelligent insights
How the power of the cloud makes Eno insights a reality.

Intelligent assistants are changing how financial companies like Capital One do business, helping customers find real-time answers to their banking needs via convenient digital channels when and where they need it—all without calling into phone trees or standing in bank branch queues or working within banking business hours. Capital One’s intelligent assistant is called Eno—you may have heard of it. Eno launched in 2017 and provides features that aim to transform customers' experience with their money. Whether it’s a potential double charge, an abnormally large tip or a recurring charge that is suddenly more than usual, Eno pores over the data and proactively reaches out to let you know and, if necessary, help you take corrective action.
Eno’s proactive insights help customers keep their money safe in real-time, often coming days or weeks before the issues would appear on a monthly statement. Engaging with our customers when it is contextually relevant—because, say, a $30 tip was left on a $40 sushi order—means more irregularities and errors are caught, and caught faster, than they would be without the proactive insights.
Providing this kind of customer experience requires an application architecture that can handle high-volume customers transactions to provide real-time insights. While a real-time event-driven architecture can be built in a data center, building it with cloud native services truly simplifies the build - making it resilient for spikes in volume and reducing development and operation costs - something my team implemented while building the insights system for Eno.
Insights driven by serverless technologies and Capital One’s data center exit
I am a Director of Software Engineering leading the team who built the insights feature for Eno. We are an agile team of five full stack engineers, a tech lead, a product owner and a scrum master working together to bring personalized, real-time, and relevant insights to Eno for about two years now. Powered, in part, by my background in developing solutions on AWS cloud, we have worked to build out Eno’s insights with a real-time, event-driven serverless architecture. Deployed in the cloud from day one, our insights architecture is made possible by the fact that Capital One is the first U.S. bank, and among the select few Fortune 150 companies such as Netflix, to report having exited their legacy data centers and gone all-in on the cloud. This means we can instantly provision architecture, manage large scale data, and respond to events in real-time—all necessary for delivering our insights capabilities.
How the serverless architecture behind Eno’s insight capabilities works
Eno’s insights were built in the cloud, meaning that they have never lived in Capital One’s now-closed data centers. However, two years ago we re-architected the insights system to take full advantage of the cloud, modernizing the architecture to run on cloud native services.
Previously, the Spark framework was Capital One’s technology of choice for high-volume real-time streaming and batch needs. And Spark is indeed one of the fastest open source engines to handle high volume batch and streaming data. However, high operation and maintenance costs became a barrier to using Spark for Eno’s insights. In particular, when we have to make Spark clusters resilient for availability zone and region failures, as a highly resilient architecture typically requires spreading instances over at least three availability zones and a minimum of two regions. This quickly increased the number of Spark master and worker node requirements, and brought down the server utilization rate. This led us to pursue a serverless streaming solution that better fit our requirements for scaling, throttling, fault tolerance, reusability, resiliency and monitoring.
To achieve this we built a serverless streaming architecture modeled after an event-driven microservice architecture where AWS Lambda based microservices are connected to one another using Amazon Kinesis as message bus.
We divided the overall architecture into three layers - Source, Sink, and Processing.
- Source: In this layer, AWS Lambda is only responsible for pulling the data from the sources and is the entry point of the event into the application.
- Processing: In this layer, we process the event from the source layer using application specific logic.
- Sink: In the last layer the application takes the final action on the event.
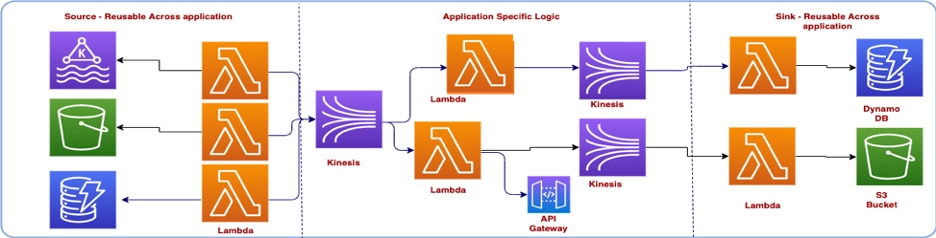
We then built our internal SDK to abstract the repetitive tasks shown above via the following features:
- Read and write from message bus: Writing and Reading the events from the Amazon Kinesis message bus.
- Exception handling and retries: Our two main retry categories are blocking and non-blocking. We use the blocking errors retry when the backend application is failing until it is back. We use non-blocking retries when we only want to retry a specific event that doesn’t have any impact on our other events.
- Secret management: Prevents storing credentials on our serverless function.
- Monitoring: We created our customized message envelope which has the metadata used to track every message. The SDK can take that overhead from the developer and can insert/remove the envelope on entry/exit of each Lambda.
- Logging: We built a logging pattern in the SDK to achieve a uniform experience across all the Lambdas.
- Message deduplication: Abstracted out duplicate message filtering as part of the library to implement message deduplication with sub milliseconds latency.
Benefits to this architecture
And as we discussed earlier, any serverless streaming solution would need to address scaling, throttling, reusability, fault tolerance, and monitoring. This architecture handles them like so:
Scaling: This architectural pattern uses AWS Lambdas to implement microservices that are connected via Amazon Kinesis. We only need to scale Lambdas that have high TPS, and as the messages get filtered out adjust the scale configuration accordingly as serverless functions are auto scalable by design.
Throttling: The fundamental function of throttling is based on needing to hold your request if your input request rate is much higher than what your downstreams can support. The persistent nature of the Amazon Kinesis message bus can help here since you can specify the number of messages which you can handle at one time and hold others.
Reusability: By building the source and sink AWS Lambda microservices in such a way that they do not have any business functionality and are configuration driven then multiple teams can use them to consume events, helping us achieve code level reusability. In addition, the flow itself is reusable because our Amazon Kinesis message bus is a pub-sub based bus that permits multiple subscribers to the same events.
Fault Tolerance: Again, the Amazon Kinesis message bus can help here; for instance if there are errors from the backend services, it can hold all/failed messages and retry until the backend calls start succeeding.
Monitoring: Logging metadata payload as part of the SDK helps achieve uniform logs across different functions. These logs can then be fed to monitoring applications to get real-time notifications to the team if something is off.
We could have achieved much of the customer experience in a data center with the help of Spark or other distributed technologies. However, this would have come at a higher cost from an enrichment point of view, a developer resource point of view, a monitoring point of view, and even a reusability point of view.
To deploy on Spark, we would have had to put the logic for each insight on one or two different jobs, making our ability to reuse components more difficult. By using Amazon Kinesis and AWS Lambda in a serverless event-based architecture we can build insights in a very modular fashion, reusing these modules across the different insights, thereby bringing down development time and attendant costs. Additionally, by going with a serverless implementation, we cut down the majority of production monitoring because we are no longer responsible for server management under this model. We also reduced costs from the traditional server-based model because these events have predictable peaks, meaning when traffic is low we are paying only for the small amount of server space that Amazon Kinesis and AWS Lambda are using at the time. Best part is, the stack automatically gets an upgrade every time the thousands of AWS engineers release new features for these core services.
Eno insights in-action—Generous Tip
One example of an Eno insights in-action is Generous Tip. Let’s lay out a relatable example to show this architecture in action. You go to a restaurant and have a nice lunch, at the end of the meal you get a check and you give the server your credit card. They bring it back for you to sign, you add in some amount for the tip—say 18%—and you go on about your day. Your thought process might be that you paid in full, but really you have only paid the original check amount, not the tip. So the merchant, that would be the restaurant, will need to file the actual amount, including the tip, back to the bank to receive payment in full.
Sounds simple, right? Well, a lot of things can happen while doing this:
- Maybe the handwriting was not legible. You think that you paid around 18% in tip but the merchant thought you wrote 38%.
- Maybe the person keying in the tip percentage made a mistake and entered the wrong numbers, entering in an 81% tip instead of an 18% tip.
- While rare, maybe someone purposefully entered in a higher tip, or maybe the customer did not put in a tip or tipped in cash and someone falsely entered one in on their behalf.
User flow for Generous Tip
Let’s look at how our Generous Tip insight handles this user flow. By looking at the transaction amount, Generous Tip calculates what the tip amount was. This tip amount is compared against the historical tip data, which tells us the usual tip percentage people leave based on several dimensions (type/category of restaurant, time of meal, city, etc). If the historical data says that this customer pays around 15-20% tip, then clearly an 80% tip is anomalous and something worth confirming with the customer via insights.
Maybe this generous tip was an accurate amount—the customer really wanted to pay a higher amount to thank an essential employee working during Covid-19—in which case they can either acknowledge the insight or do nothing. If the amount was incorrect, we provide the merchant’s contact information within the insight to help customers fix the tip amount.

How our insights architecture underpins this user flow
For us to look after customer transactions as they’re happening, we need to listen to all the transactions in real time. Each card transaction is a unique event, and because these events are happening at such a high pace, we needed an event-driven architecture that could also operate at a very high pace as well. Amazon Kinesis and AWS Lambda play well together, and because of this integration they were chosen as the microservice and message bus. In this approach, multiple Kinesis message hubs are connected together through a series of transformations done via Lambda microservices. The microservices were used to implement the specific business logic required for the particular insights, with that logic implemented in a very modular fashion so that reusability could be achieved across the board. Because of this, for a given insight, say Generous Tip, there is no one component that will apply all the business rules, instead it will go through a series of filters and transformations via the microservices to get to a point where we can apply a very specific business logic to it.
The asynchronous nature of credit card transactions is perfect for event-driven architectures. For example, when a customer swipes their credit card they are not waiting for us to send an insight to them, we’re doing so via an asynchronous system and a design pattern called “file and forget.” In this scenario a customer swipes, they move on, but now the event-driven architecture is listening to those events as and when they’re happening, applying a series of transformations and enhancements to get to a specific result.
And in terms of building serverless capabilities into this architecture, in a serverless scenario the cloud provider manages the server itself - everything from the patching to the security to maintenance to the scalability - and ensures that it is always available whether there is low or high traffic load with the client only paying for what they use. Given that insights like Generous Tip have periods of peak activity punctuated by stretches of low traffic, going serverless makes sense from a cost and utilization standpoint.
The Real World Customer Impact of Our Serverless Architecture
To use an example, I would say that a server-based model is like buying and owning a car and the serverless model is like taking an Uber or Lyft from point A to point B. We want our customers to feel supported, to let them know that Capital One is looking out for them and keeping track of their transaction activity so they do not have to. And we want this to happen in a way that is well optimized and utilizes cutting edge technology to its maximum benefit. By using cloud native services such as Amazon Kinesis and AWS Lambda, we are able to make the most of an event-driven streaming serverless architecture, providing real-time insights and real-time help to our Eno customers.
To learn more about Eno click here.
Eno is learning all the time and may not be able to answer all questions or perform all tasks. Eno service outages may occur. Capital One customers are responsible for regularly checking their account statements. Web access is needed to use mobile banking. Check with your service provider for details on specific fees and charges. Texting with Eno means you agree to chat about your account over SMS and receive recurring messages. Message and data rates may apply. Mobile phone carrier fees for text messages may apply.
Some or all Eno features may not be available to all Capital One customers, depending on the types of accounts held. For example, certain bank accounts are not eligible to text with Eno, and Eno email notifications, app notifications and virtual card numbers from Eno may not be available for certain credit cards.



