Emerging vector databases: A comprehensive introduction
Solve search challenges for unstructured data with Capital One’s Tech interns—Part 1.

This blog was authored by Brennan Gallamoza, Andrew Lin, Sonu Chopra-Khullar, members of the Retail Bank Machine Learning Architecture team
What are vector databases?
Problems with searching for unstructured data
How would you search for complex data types, such as images, audio files, or even passages of text? In a relational database, you are normally working with primitive data types that can be easily filtered to answer simple questions, such as “How many people in this table are at least 1.8 meters?” Even when you are working with objects like strings, you are often performing substring or regular expression matching to return results.
What if your business questions change from “How many text strings match a given substring?” to “How many text strings have similar meaning to my given string?” Suddenly, a simple boolean check no longer works, as your string has changed from a simple array of characters to an object that has meaning. This is true for images and other complex data types too. You often search for similar objects in your database rather than exact matches.
| Simple data examples | Complex data examples |
| Numbers (int, float, etc.) | Images |
| Booleans | Audio |
| Character/strings | Text (with semantic meaning) |
Figure 1. Simple vs. complex data types
Similarity search and kNN with vector databases
A vector database, an emerging type of database, enables similarity search through vectors. Think of vectors as arrays of floats that represent coordinates in a vector space. A simple example is some 2D vector (e.g., [0, 1]) representing an X and Y coordinate on a graph. By placing several points on a graph, we can decide that two points are “similar” when they are close to each other in that 2D vector space.
Now, what if those points were actually meaningful pieces of complex data? This is the heart of vector databases; by associating objects with a vector (also known as a vector embedding), similar objects can be found by some distance metric between points in a vector space.

Figure 2. Vector space representation of vector database documents
To actually compare vector embeddings, we use specific distance metrics between vectors. A commonly used distance metric is Euclidean distance, which is the distance of a line segment between two points. For example, if I had the following two vectors p and q, we can calculate the Euclidean distance with the following formula:

Figure 3. Euclidean distance formula
Then, our Euclidean distance calculations in Python would be:
from math import sqrt
p = [ 1, 3 ]
q = [ 2, 1 ]
total = sum([ ( q[i] - p[i] )**2 for i in range(len(q)) ])
d = sqrt(total)
print(d)
>>> 2.23606797749979Using distance metrics like Euclidean distance or cosine similarity enables us to do k-nearest-neighbor (kNN) search to find k vectors that are most similar to a given vector (for example, Figure 2 uses k = 2). Using kNN search, many useful features become available to your database, such as:
- Implementing recommendation systems
- Finding duplicates/near-duplicate records
- Finding outliers in the dataset
- Validating data (does this record have labels similar to other records nearby?, etc.)
Getting vectors from neural networks
Now that we understand the general logic of vector databases, we would naturally want to know how we obtain vector embeddings in the first place! Vector embeddings are vector outputs extracted from machine learning models by using complex data (images, text, etc) as input, thereby making vector embeddings a “vector representation” of the data fed into the model.
Because vector embeddings originate from a model, the float “coordinates” of the vector actually represent some piece of information related to the data. For any given vector database, all the data stored was first passed through a model to obtain consistent vector embeddings that can be correctly compared for similarity search.
To visualize vector embedding extraction, we’ll use a convolutional neural network (CNN) model that can perform binary classification (i.e.,, our model predicts if a given input is a “positive” or “negative” class). CNNs are composed of several layers that take in some input vector and deliver some output vector.
Our true purpose is to get the output vectors from an intermediate layer of the model to serve as our vector embeddings. If you are unfamiliar with how CNNs are structured using layers, you can read up more on it at A Comprehensive Guide to Convolutional Neural Networks—the ELI5 way | by Sumit Saha | Towards Data Science.
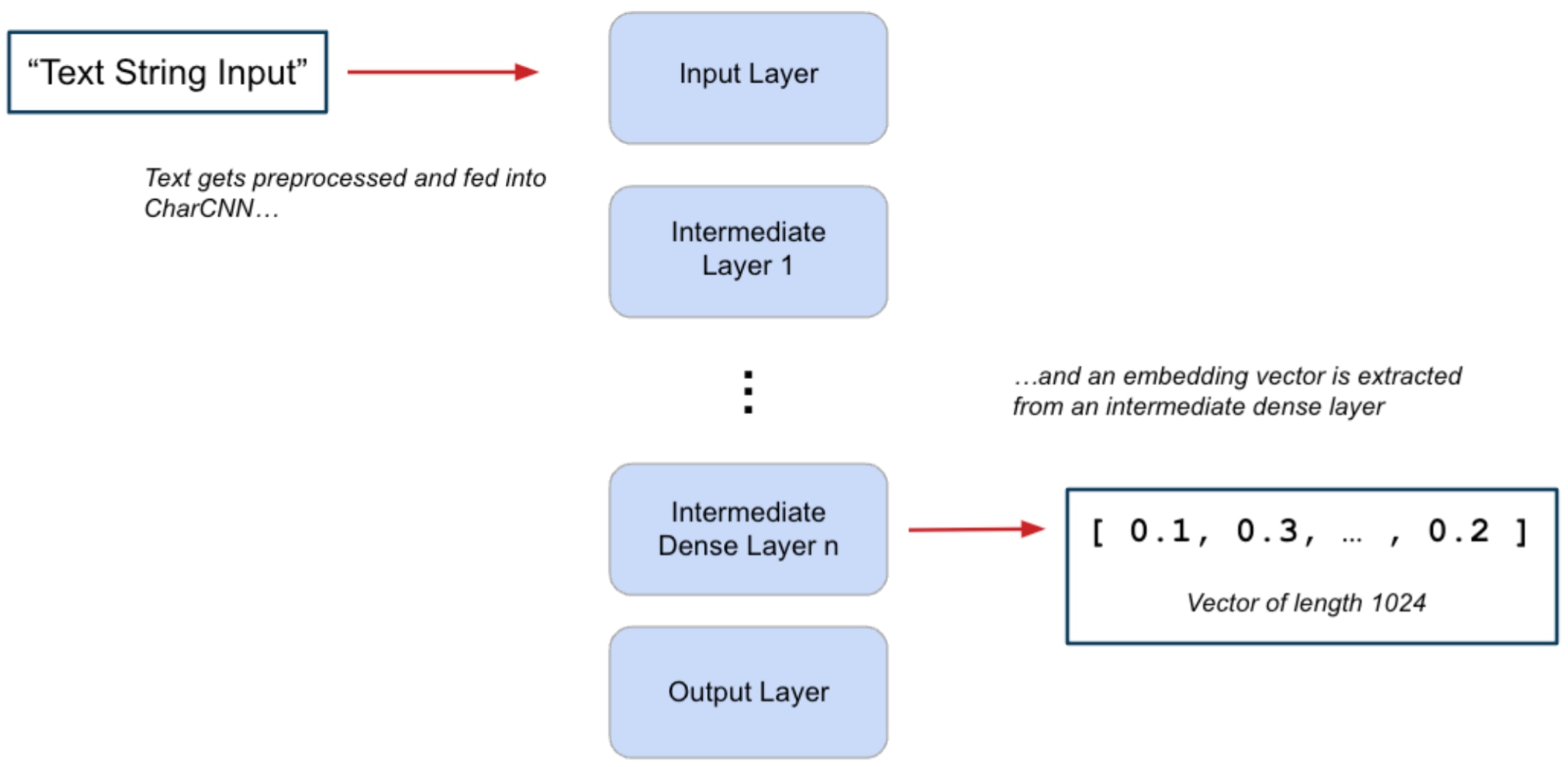
Figure 4. Graphic depicting the extraction of embedding vectors from a CharCNN model
In the graphic above, we specified a fully connected layer that outputs a vector of dimension 1024. This 1024 length vector is the vector embedding we want. These extracted vectors will be used to represent our text data in the database.
Benefits of using vector databases over traditional databases
Every concept we've looked at has been discussed in the context of vector databases, but why are vector databases necessary? As we mentioned before, traditional relational databases tend to handle unstructured data poorly, but Amazon’s DynamoDB and other NoSQL databases are actually well-suited for storing unstructured data!
If you extract vector embeddings from a model, you can certainly store those vectors alongside relevant complex data in a NoSQL database. The key trait of vector databases is that they are designed around vector indexing, In particular, vector indexing can be used to:
- Perform rapid and accurate approximate nearest neighbor search (ANN)
- Combining vector indexing with metadata indexing for rapidly filtering out specific data points
It is important to note that relational and NoSQL databases can still use external tools like the FAISS library to create vector indexes and perform similarity search. Still, these external indexes must be updated separately from the database itself and require further reading from the original database to obtain relevant metadata. The main draw of vector databases is that they are built around optimizing automated vector indexing, with the added benefit of having easy metadata filtering mechanisms as well.
Creating a Vespa vector database
Now that we have discussed the basics of vector databases, we can set up a local vector database with sample data. In our demonstration, we will be using Vespa, an open source platform for storing, indexing, and querying vector data.
Structuring a local Vespa database
-
Clone this repo, which has the necessary file structure for deploying a Vespa database. We will assume we are in the root directory of the repo from this point onwards. Next, follow the README to set up your environment for working with Vespa. There are a few important configuration files that need to be specified when spinning up a local Vespa database:
Schema files
-
Found in `app/schemas/` directory, schema files are similar to tables in a relational database; the structure of documents (equivalent to records in a relational database) are defined by the fields specified in its matching schema file. For our example, we will be storing hotel reviews that are classified as 1-5 stars. Our `hotel_reviews` documents will be defined as having 5 fields (4 metadata fields, 1 field to hold vector embeddings):
| Field | Description |
| ID | Unique integer identifier for that hotel review |
| Text | Actual text of the movie review |
| Label | Binary integer field; 0 for a negative review, 1 for a positive review |
| Embedding | Vector embedding obtained by preprocessing the hotel review text and passing it into a character convolution neural network (CharCNN). Vectors are specifically of dimension 1024. |
Schema definitions
- Lastly, our schema defines something called a “rank-profile” (named “similarity”) that describes our distance metric and which fields to use for calculation. In our case, we use Euclidean distance and state that the `embedding` field should be used. This is extremely important for enabling similarity search in our database!
Vespa applications
The `app/services.xml` file is used to configure the clusters that make up your Vespa application. Briefly put, a Vespa application is comprised of three types of clusters:
| Cluster type | Description |
| Admin/Config cluster | Sets up and manages the other clusters in the Vespa application using configurations in the application package |
| Stateless Java container cluster | Processes incoming queries and their responses. Also handles incoming data. Works as a middleman between the user and the data |
| Content cluster | Stores data and executes queries |
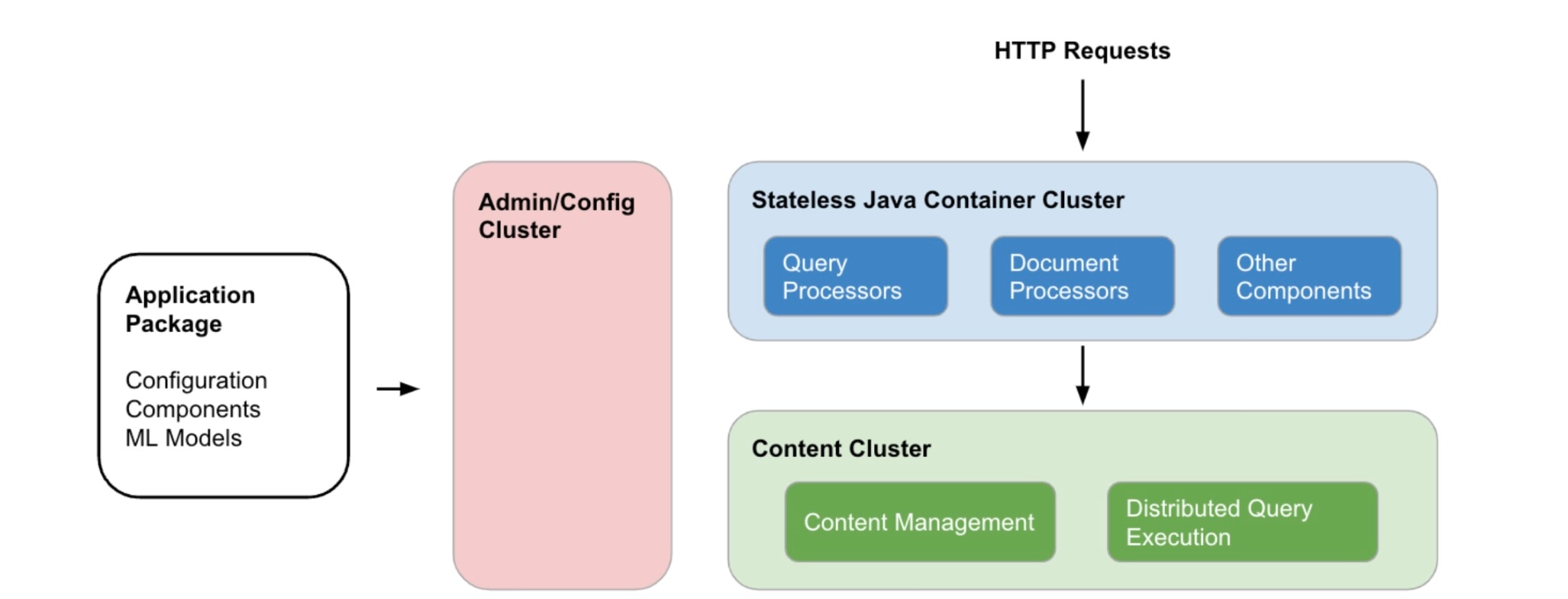
Figure 5. Cluster organization of a Vespa application
Query profiles and query types
As mentioned earlier, the `rank-profile` in our schema files is vital for configuring similarity search, but it is not the only necessary file. If we navigate to `app/search/query-profiles/default.xml`, we find a file that contains:
< query-profile id="default" type="root" />The type “root” references `app/search/query-profiles/types/root.xml`, which contains:
< query-profile-type id="root" inherits="native">
These files coordinate to specify that when we perform a vector similarity search, we should expect a vector (tensor) of size 1024, which is identical to our `embedding` field defined in `schema.sd`. This is a very brief description of how query profiles and query profile types work, and can be further understood in the Vespa documentation.
Interacting with our database
Local deployment
If Docker Desktop and the Vespa CLI have been successfully installed, we can finally deploy our database! Run the following command in your terminal to deploy Vespa:
vespa deploy —-wait 300 appOnce the Vespa application successfully deploys, you can move onto feeding data to the application!
Feeding data to Vespa
The best way to feed data to a Vespa application is to use the `vespa-feed-client`, which should have been downloaded after following the README. To use this, data must be stored in a specially formatted JSON document and fed to the Vespa application’s endpoint. Then, to feed the data, run the following command in your terminal:
./vespa-feed-client-cli/vespa-feed-client \
--verbose --file ./data/reviews.json --endpoint http://localhost:8080Now, we can start querying the database!
Querying the vector database
Now that our vector database contains data, we can finally query the database! In the terminal, we can query for all the fed documents using the following terminal command:
vespa query -v 'yql=select id, label from hotel_reviews where true'As you can see, all of our documents and their relevant metadata were returned. Unlike our previous query, approximate nearest neighbor queries can be relatively complex. For our convenience, the script `user_search.py` will build a proper ANN query and communicate with the Vespa database for us.
In this case, our script is going to get the vector embedding of the ID we specify, then use that embedding to find the top 3 closest existing vectors in the vector database. We can run this with the following terminal command:
python user_search.py 2 3If you see an output of 3 documents, then congratulations! You successfully set up a vector database and performed similarity searches on text! Our `user_search.py` script was used to find the 3 approximate nearest neighbor vectors to the embedding vector of document ID = 2.
Further reading
Everything we have discussed so far is just a brief overview and demonstration of how a vector database works. There are many other alternatives to Vespa, such as Milvus and Pinecone, that work similarly but have their own setup procedures and internal differences.
Additionally, there are much more detailed explanations of what vector databases do under the hood, such as the complexity of how vector indexing algorithms work. The vector database is an evolving technology that can be very useful to answer the right business questions.
Check out Part 2 of this blog series: Powerful resource management with Snowflake, Dask, & PyTorch.
---
This blog was authored by Brennan Gallamoza, Andrew Lin, Sonu Chopra-Khullar, members of the Retail Bank Machine Learning Architecture team.
Brennan was part of Capital One’s Technology Intern Program (TIP), focusing on machine learning. At the time of his internship, Brennan was a computer science major with a bioinformatics minor at the University of Delaware. Sonu is a Director of Machine Learning at Capital One. Andrew is a software engineer within Retail Bank Tech who focused on Machine Learning for Sensitive Data Detection.

