End-to-end models for complex AI tasks
Deep neural networks trained end-to-end can outperform classical pipeline-based systems, but they pose some challenges.

by Erik Mueller, Sr Distinguished Machine Learning Engineer, and Alison Chi, Data Engineer
Until recently, the most common way of solving complex AI tasks such as natural language dialogue has been to build component-based systems, or systems consisting of a set of components, where each component is designed to perform a part of the task. To reduce complexity of interactions among components, the components are typically organized as a pipeline, where each component feeds its output to the input of the next component. The IBM Watson system for question answering was such a component-based system organized as a pipeline. Some components in Watson were rule-based, others were machine learning models, and others were hybrids of rule-based systems and machine learning models.
The main advantage of machine learning over traditional software engineering is that it allows one to build a component that performs a task by training a model from data, which removes the need for a human to specify exactly how to perform the task. The following question arises: Why not take this idea to the limit and use machine learning to perform entire complex AI tasks, rather than just parts of those tasks? End-to-end models seek to do exactly this, as shown in Figure 1.

Figure 1 End-to-End Models
It was originally believed that natural language processing tasks were too hard to be performed by end-to-end models. For example, in 2008, Punyakanok, Roth, and Yih argued for the importance of a separate syntactic parsing step in the larger task of semantic role labeling. But then a series of end-to-end models based on deep neural networks performed better than expected. In 2011, Collobert and associates showed that the performance of an end-to-end model could approach that of component-based systems on several natural language processing tasks: part-of-speech tagging, chunking, named entity recognition, and semantic role labeling. In 2015, Zhou and Xu introduced an end-to-end model for semantic role labeling that outperformed all previous systems, without using syntactic parsing. In 2016, Google’s end-to-end Neural Machine Translation system achieved results that approached or surpassed all previous systems on the machine translation task. And, in 2017, Lee, He, Lewis, and Zettlemoyer introduced an end-to-end model for coreference resolution that outperformed all previous systems.
As shown in Table 1 below, the number of papers on end-to-end models is increasing.
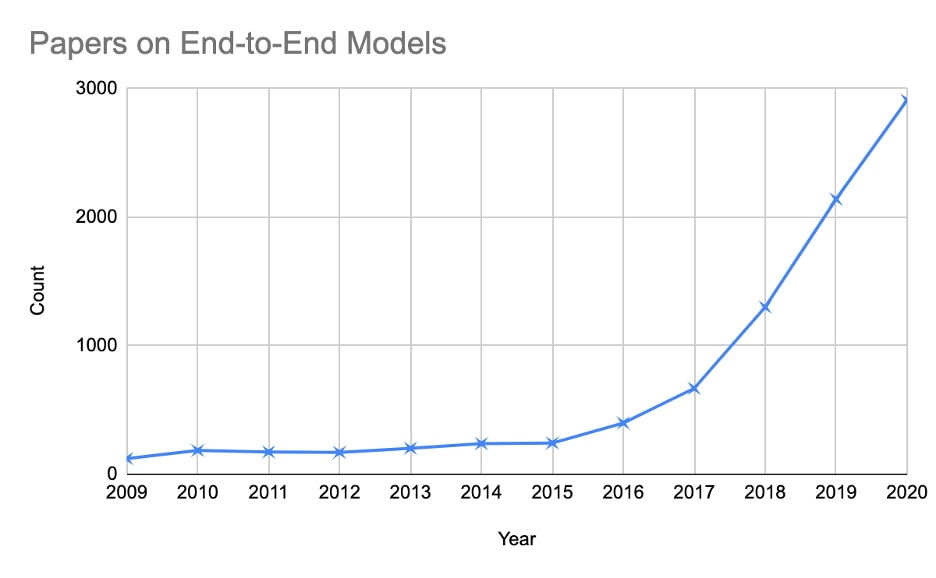
Table 1 Papers on End-to-End Models Source: Google Scholar (https://scholar.google.com/) with search string “end-to-end model” (accessed on 3/15/2021)
Benefits and challenges of end-to-end models
End-to-end models have a number of advantages relative to component-based systems, but they also have some disadvantages.
Advantages of end-to-end models
- Better metrics: Currently, the systems with the best performance according to metrics such as precision and recall tend to be end-to-end models.
- Simplicity: End-to-end models avoid the sometimes thorny problem of determining which components are needed to perform a task and how those components interact. In component-based systems, if the output format of one component is changed, the input format of other components may need to be revised.
- Reduced effort: End-to-end models arguably require less work to create than component-based systems. Component-based systems require a larger number of design choices.
- Applicability to new tasks: End-to-end models can potentially work for a new task simply by retraining using new data. Component-based systems may require significant re-engineering for new tasks.
- Ability to leverage naturally-occurring data: End-to-end models can be trained on existing data, such as translations of works from one language to another, or logs of customer service agent chats and actions. Component-based systems may require creation of new labeled data to train each component.
- Optimization: End-to-end models are optimized for the entire task. Optimization of a component-based system is difficult. Errors accumulate across components, with a mistake in one component affecting downstream components. Information from downstream components can’t inform upstream components.
- Lower degree of dependency on subject matter experts: End-to-end models can be trained on naturally-occurring data, which reduces the need for specialized linguistic and domain knowledge. But expertise in deep neural networks is often required.
- Ability to fully leverage machine learning: End-to-end models take the idea of machine learning to the limit.
Outstanding challenges for end-to-end models
- Lack of explainability: It may be difficult to understand why an end-to-end model produces a given result (although this is also the case to a lesser degree for component-based systems).
- Lack of predictability: It may be difficult to predict how an end-to-end model will behave in a variety of situations (although this is also the case to a lesser degree for component-based systems).
- Lack of diagnosability: In a component-based system, it may be possible to identify which component is responsible for a failure, which may (or may not) allow one to modify the component to avoid similar failures, while maintaining the system’s performance in other cases. In an end-to-end system, it may not be as easy to locate the source of a failure. Addressing failures in end-to-end systems typically involves modifying the model parameters, model architecture, or training data.
- Data intensity: End-to-end models require a significant amount of data for training.
- Expensive training and inference: Training and applying end-to-end models may consume a great deal of computer power or even be intractable.
- Unknown limits: Because end-to-end models are relatively new, their limits are not well-understood, and more research on them is needed. Some applications may be ill-suited for end-to-end models and may require the creation of component-based systems.
Three potential risks of end-to-end models
End-to-end models present several potential risks:
- Producing incorrect output
- Producing offensive output
- Producing biased output
These risks arise primarily from training data quality and quantity, and they are difficult to avoid without significant effort. Let’s discuss them in more detail.
Risk #1: Producing incorrect output
All machine learning models carry the risk of producing incorrect results. Standard metrics such as precision and recall are designed to measure the correctness of results produced by these models. However, natural language dialogue systems present additional risks because information is conveyed through language.
There is an element of trust with a conversational agent that may make its output more believable and therefore riskier than if the erroneous results were presented in a different form. Consider a conversational driving assistant that tells the driver to turn right onto a one-way street going the wrong direction. If the driver trusts the assistant, and can’t or doesn’t verify the information before acting on it, the driver may end up listening and acting on the incorrect information.
Risk #2: Producing offensive output
The risk of producing inappropriate or offensive output comes primarily from training data. One of the most prominent examples of this is Microsoft’s Tay, a Twitter bot designed to behave like a Millennial American woman between the ages of 18 and 24. Microsoft incorporated realtime adaptive learning into what may have been an end-to-end model, allowing users interacting with it on Twitter to teach it how to behave. Within 16 hours, Tay’s account was shut down because of its high volume of extremely offensive tweets. The incorporation of real tweets and interactions as training data was meant to continuously improve performance. But, as Nagy and Neff describe, “this social and technological experiment failed because the capacities for Tay to produce unexpected and uncharacteristic behaviors were used to spam her followers with weird, politically insensitive, or racist and misogynistic tweets.”
Minimizing the risk of producing offensive content is a difficult task, and techniques to eliminate offensive content can sometimes backfire, as occurred with Microsoft’s Zo, the successor to Tay. Zo was designed to simulate a teenage girl and interacted with users on platforms such as Messenger, Twitter, and Skype. According to a Microsoft spokesperson quoted by Stuart-Ulin, “Zo uses a combination of innovative approaches to recognize and generate conversation, including neural nets and Long Short Term Memory (LSTMs).” Zo was designed to avoid discussing certain topics. Unfortunately, this wasn’t sufficient to prevent discriminatory utterances, and Zo was shut down.
Researchers are exploring techniques for minimizing offensive language about specific demographic groups. To avoid racist language, Schlesinger, Hara, and Taylor suggest augmenting training data with “databases of diverse race-talk—talk where race is both explicit and implicit.”
Risk #3: Producing biased output
Bias can be defined as “prejudice for or against a person, group, idea, or thing – particularly expressed in an unfair way.” For machine learning tasks, implicit bias can be hard to avoid because the training “data itself is often a product of social and historical process that operated to the disadvantage of certain groups.”

Table 2 “Results of detecting bias in dialogue datasets.” Source: Ethical Challenges in Data-Driven Dialogue Systems (https://arxiv.org/abs/1711.09050)
Bias is often implicit in word embeddings, the vector representations of textual data that encode the context in which words appear. Word embedding techniques such as GloVe and Word2Vec have been found to have significant gender bias. For example, in a semantic role labeling task, “the activity cooking is over 33% more likely to involve females than males in a training set, and a trained model further amplifies the disparity to 68% at test time.”

Table 3 “The most extreme occupations as projected on to the she-he gender direction on g2vNEWS.” Source: Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings (https://arxiv.org/abs/1607.06520)
But significant progress has been made on techniques for debiasing word embeddings. Both the hard and soft debiasing techniques presented by Bolukbasi, Chang, Zou, Saligrama, and Kalai significantly reduce “gender stereotypes, such as the association [between] the words receptionist and female, while maintaining desired associations such as between the words queen and female.”
Conclusion
End-to-end models are a useful technology for building AI systems. They should be considered because of their simplicity, performance, and data-driven nature. Because of their potential issues including unpredictability, bias, and lack of explainability, they may not be suitable for all applications. To date, these risks can be partially, but not completely, mitigated.
Background vector created by starline - www.freepik.com



