Dask & RAPIDS: The Next Big Thing for Data Science & ML
By Ryan McEntee, Senior Director of Software Engineering, and Mike McCarty, Director of Software Engineering
Setting the Stage
Over the past 3+ years, I’ve had the opportunity to lead Capital One’s engineering effort to modernize our enterprise Data Science, Quantitative Analyst and Data Analyst platforms. Our core objective was to migrate our enterprise users of data from an on-premises, predominantly SAS-based platform to a custom built, cloud native platform that supported a wide variety of open source technologies. As you can imagine, my team and I have learned a tremendous amount from this experience, but what might be surprising is that not all of the lessons have been technical.
Our early strategy entailed looking to top Data Science and Machine Learning Engineering talent (both internal and external to the company), and our industry trend research to understand the leading open source technologies and platforms in the space. We also spent a tremendous amount of time engaging with end users from across the enterprise, covering a wide spectrum of technical acumen, to identify current pain points that we had to address. Addressing these pain points was very important as our ultimate goal was to not only enable the latest and greatest technology, but to also improve the efficiency and efficacy of our end user population.
After delivering the first iteration of our new cloud-based platform, we saw rapid, widespread adoption along with great feedback. Mission accomplished, right? Unfortunately, that was not the case. Almost immediately, we noticed a significant number of the largest AWS instances being spun up within the platform with users only utilizing 1 of the 128 available cores on each instance. Additionally, the jobs running on these instances would run for many hours as they were storing up to 3TB of data in memory using single threaded Python or R. With one of our goals being to increase compute utilization, missing the mark would be an understatement with these workloads.
Despite all of the emphasis we put on understanding the pain points of our end users, we failed to consider the inevitable skill transformation our end user population would endure.
Understanding People Transformation is Key to Success
In all of our user research, we didn’t realize just how much training and support the SAS users would need to be able to parallelize jobs using open source technologies. It was very easy for them to do this in SAS, but it was very difficult and time consuming to parallelize their workloads without it.
For example, a legacy SAS user would first need to become proficient in the most popular Python computational libraries, many of which do not utilize multiple CPU cores let alone multiple servers. Once parallelization is required to scale for larger data sets, they would also need to become proficient in Spark to re-code their solution. The re-code would likely be significant as many Python computational libraries (i.e. NumPy & Pandas) are not performant in Spark and the dataframe APIs are different. Additionally, when a job crashes in Spark, to effectively debug the error, the end users would need to know Java. Considering that our business can’t stop operating while end users learn these new technologies, the outlook to complete this transformation had a very long tail.
Well, what about the engineers; couldn’t they help lift the burden of re-coding from Python to Spark? The short answer is “no.” End users of data at Capital One greatly outnumber our engineering workforce, so developing their skills to enable them to self-serve was key to our success.
This is where Dask and RAPIDS enter the picture.
Why Dask and RAPIDS?
Dask offers a promising solution for scaling Python workloads where end users can leverage a familiar API, and avoid the need for learning Spark and adjusting their code for incompatibilities. Yes, there is still learning required to leverage Dask, but the barrier to entry is much lower than with Spark. RAPIDS, the GPU-accelerated data science libraries incubated by NVIDIA, offers the same API compatibility and enables NVIDIA GPU computing from Python. What has been just as compelling as the lower barrier to entry is that Dask and RAPIDS have also shown impressive performance gains when applied to some existing use cases.
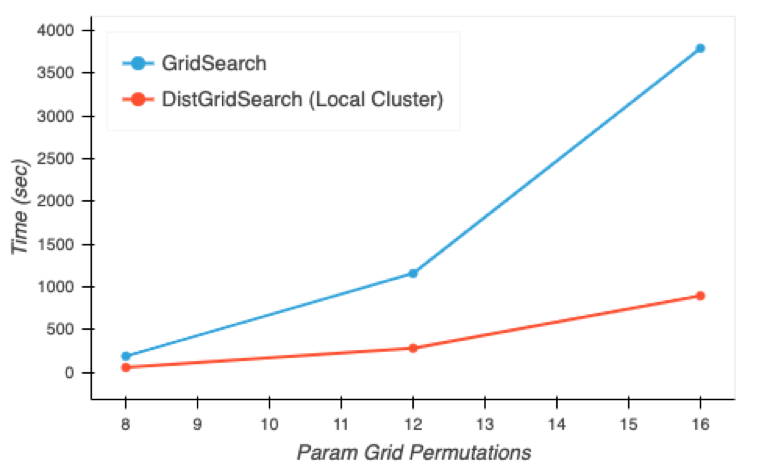
At Capital One, early implementations of Dask have reduced model training times by 91% within a few months of development effort. The figure below shows improvements we have made with a local Dask cluster during one step in a model training pipeline; the performance is even better in production on a distributed Dask cluster. Dask speeds up the iteration cycle during development, which allows developers to test their code faster.
Dask and RAPIDS can be used in tandem to scale computations horizontally and vertically on GPUs. The figure below shows a weak scaling study on an XGBoost training execution using a dataset that does not fit into memory on a single system. Here Dask is used to distribute computations across multiple GPUs on a single EC2 instance on AWS. Each GPU gets a special Dask worker that knows how to run computations on it using RAPIDS. The original training time on a multi-core CPU system is also included for reference. Please note the y-axis is logarithmically scaled.
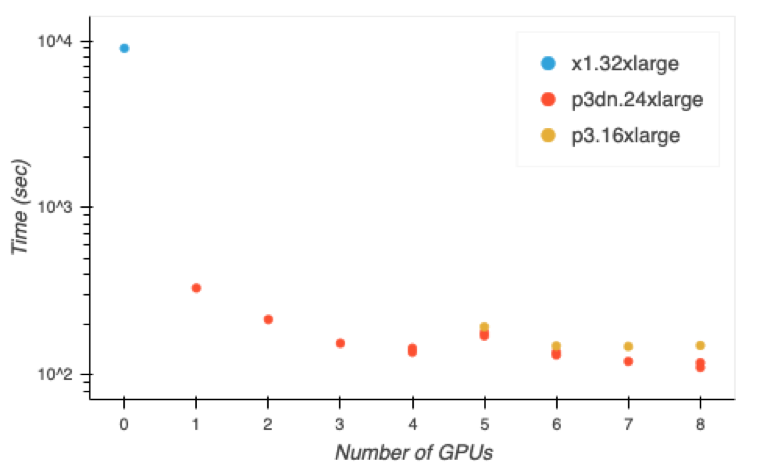
With these improvements, we have seen roughly 100x improvement model training times and costs have gone down 98%, assuming you are only paying for computation during training.
Now that the potential computational performance gains using Dask and RAPIDS have been demonstrated, the next steps are to understand model accuracy, improve deployment infrastructure, and train users. As issues are found, the team will contribute to the open source projects as much as possible.
Dask and RAPIDS scale Python natively, which allows Capital One Data Scientists and ML Engineers to maintain ownership of their code and focus on what they do best.
Want to Know More?
This is the introductory first post in a series of blogs where our resident Dask and RAPIDS expert, Mike McCarty, will dive into the deep technical details of both Dask and RAPIDS. We will also keep you all posted on developments as we work to implement these technologies at scale within Capital One.