Understanding ARIMA Models for Machine Learning
A simple introduction to understanding autoregressive integrated moving averages
If you are among the 50% of Americans who own stock, I am sure you have had some sleepless nights thinking about the future price of your investments. You may try and calm your fears by reading predictions by economists and other investment professionals -- but how do they come up with their forecasts? One way is by using autoregressive integrated moving average (ARIMA) models.
What is an Autoregressive Integrated Moving Average?
Autoregressive Integrated Moving Average (ARIMA) models have many uses in many industries. It is widely used in demand forecasting, such as in determining future demand in food manufacturing. That is because the model provides managers with reliable guidelines in making decisions related to supply chains. ARIMA models can also be used to predict the future price of your stocks based on the past prices. Do note, that although they might help you predict changes to the S&P 500 Index’s price over time, I am so sorry to say, it won’t help you earn quick money by predicting when viral stocks like Gamestop (GME) will shoot up next time.
That’s because ARIMA models are a general class of models used for forecasting time series data. ARIMA models are generally denoted as ARIMA (p,d,q) where p is the order of autoregressive model, d is the degree of differencing, and q is the order of moving-average model. ARIMA models use differencing to convert a non-stationary time series into a stationary one, and then predict future values from historical data. These models use “auto” correlations and moving averages over residual errors in the data to forecast future values.
Potential pros of using ARIMA models
- Only requires the prior data of a time series to generalize the forecast.
- Performs well on short term forecasts.
- Models non-stationary time series.
Potential cons of using ARIMA models
- Difficult to predict turning points.
- There is quite a bit of subjectivity involved in determining (p,d,q) order of the model.
- Computationally expensive.
- Poorer performance for long term forecasts.
- Cannot be used for seasonal time series.
- Less explainable than exponential smoothing.
How to build an ARIMA model
Let’s say you want to predict a company’s stock price with an ARIMA model. First, you will have to download the company’s publicly available stock price over the last few -- let’s say ten -- years. Once you have this data, you are now ready to train the ARIMA model. Based on trends in the data, you will choose the order of differencing(d) required for this model. Next, based on autocorrelations and partial autocorrelations, you can determine the order of regression (p) and order of moving average (q). An adequate model can be selected using Akaike Information Criterion (AIC), Bayesian Information Criterion (BIC), maximum likelihood, and standard error as performance metrics.
Understanding how the ARIMA model works
As stated earlier, ARIMA(p,d,q) are one of the most popular econometrics models used to predict time series data such as stock prices, demand forecasting, and even the spread of infectious diseases. An ARIMA model is basically an ARMA model fitted on d-th order differenced time series such that the final differenced time series is stationary.
A stationary time series is one whose statistical properties such as mean, variance, autocorrelation, etc. are all constant over time. A stationarized series is relatively easy to predict --you simply predict that its statistical properties will be the same in the future as they have been in the past!
To understand how an ARIMA model functions, there are three terms within the name that you will need to better understand:
- AutoRegressive - AR(p) is a regression model with lagged values of y, until p-th time in the past, as predictors. Here, p = the number of lagged observations in the model, ε is white noise at time t, c is a constant and φs are parameters.
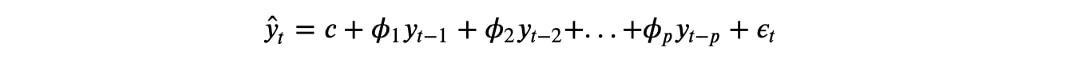
- Integrated I(d) - The difference is taken d times until the original series becomes stationary. A stationary time series is one whose properties do not depend on the time at which the series is observed.

Let’s look at two graphs from Forecasting: Principles and Practice (2nd ed) by Rob J Hyndman and George Athanasopoulos. The graph (a) on the left is Google’s stock price for 200 consecutive days. This is a non-stationary time series. Graph (b) on the right side is the daily change in the Google stock price for 200 consecutive days. Image (b) is stationary because its value does not depend on the time of observation. In this example, order of differencing would be one, as the first order differenced series is stationary.
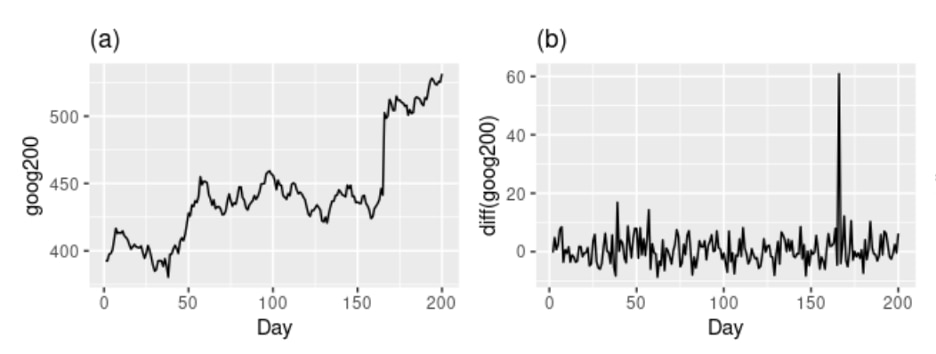
Graphs taken from Forecasting: Principles and Practice (2nd ed) by Rob J Hyndman and George Athanasopoulos (https://otexts.com/fpp2/arima.html)
- Moving average MA(q) - A moving average model uses a regression-like model on past forecast errors. Here, ε is white noise at time t, c is a constant, and θs are parameters
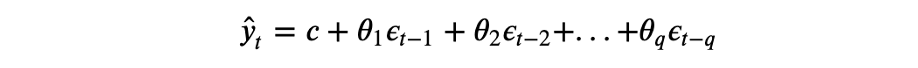
Combining all of the three types of models above gives the resulting ARIMA(p,d,q) model.
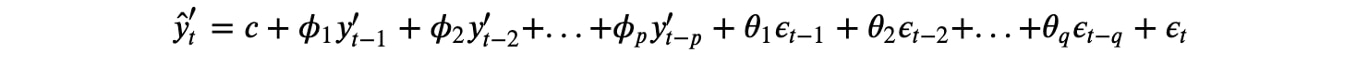
Conclusion
The ARIMA methodology is a statistical method for analyzing and building a forecasting model which best represents a time series by modeling the correlations in the data. Owing to purely statistical approaches, ARIMA models only need the historical data of a time series to generalize the forecast and manage to increase prediction accuracy while keeping the model parsimonious.
Despite being parsimonious, there are multiple potential disadvantages to using ARIMA models. Most important of them stems from the subjectivity involved in identifying p and q parameters. Although autocorrelation and partial autocorrelations are used, the choice of p and q depend on the skill and experience of the model developer. Additionally, compared to simple exponential smoothing and the Holt Winters method, ARIMA models are more complex and thus, have lower explanatory power.
Lastly, similar to all forecasting methods, by being backward looking, ARIMA models are not good at long term forecasts and are poor at predicting turning points. They can also be computationally expensive.
Thus, ARIMA models can be easily and accurately used for short-term forecasting with just the time series data, but it can take some experience and experimentation to find an optimal set of parameters for each use case.
For more resources, check out some projects using ARIMA method: