9 top practices for AWS event-driven serverless architecture
9 best practices for efficient processing & cost optimization with AWS SNS, SQS, EventBridge, & Lambdas

Event-driven architecture is a powerful architecture style that promotes de-coupling between systems, better fault isolation, independent scaling, and independent development and releases. Serverless architecture is an architecture style that provides the benefit of not having to worry about server provisioning or maintenance and has auto scaling, high fault tolerance, and is pay per use. AWS brings these two architecture styles together with the combination of serverless compute Lambda and the messaging solutions AWS Simple Queue Service (SQS), AWS Simple Notification Service (SNS), and AWS EventBridge.
In this article we will go over some challenges engineers face when using event-driven serverless architectures at scale, and how to deal with them using some best practices for the AWS services above. Let’s jump right into what those best practices are.
1. Reduce the pressure on your event consumers and their dependencies
In the event-driven serverless architecture style, one of the guardrails is to make sure there is smooth processing of the events by the consumers while keeping costs under control.
Factor in the time taken by consumers to process each event
Let’s say you have a Lambda function that is a subscriber to a SNS topic and the Lambda function takes a considerable amount of time to process every event. Example: It needs to make an external API call that is terribly slow in responding to requests.
In this scenario, if you use SNS to broadcast the messages to Lambda and there is a burst of messages this can lead to several invocations of your Lambda function running at the same time. This would be less cost efficient and can potentially hit limits on max concurrent Lambda invocations. Also, since those limits are at an account level, this could possibly cause capacity issues for other applications on the same account.
The suitable approach here is to throttle the traffic up-front. You can use SQS as a destination to SNS, wherein SQS queues can be used to hold the messages until the consumers are ready to process them as shown in the diagram below.

SNS distributes events to SQS: https://event-driven-architecture.workshop.aws/4-sns/2-filtering/message-filtering.html
Consider the scaling limitations of your event consumers as well as their dependencies
This is a slightly different scenario than above. Let’s say you have a Lambda function that is going to consume messages from an SNS topic and perform some operations on an AWS RDS database or call an API that doesn’t scale well. If there is a burst of messages to the SNS topic, even though Lambda can scale up to the concurrency limits set, the downstream dependency may not be able to handle it. Example: RDS max connection limit could be reached or the downstream API that doesn’t scale well might crash. With Lambda retries it may self heal, or we might make it worse, resulting in the messages going to DLQ (that is, if you have configured a DLQ for your Lambda).
Similar to above, leverage SQS as a destination for SNS and then have your Lambda function consume it when it is ready.
2. Use the SNS message filtering feature
This event-driven serverless best practice can be leveraged to filter the noise upfront before it hits the event consumers, thereby saving costs.
When subscribing to SNS topics, consumers can specify additional filter criteria in their subscription filter policy to say, “Only send me messages that meet certain criteria.” Filter policy is a JSON object that contains the filter criteria. The messages published to the SNS topic consist of a Message Attributes element that can host additional metadata about the message. Publishers can populate this element and SNS takes care of filtering the messages per the subscription filter policy, only delivering the messages that match the right criteria to the consumers. This way, consumers don’t need to be bothered by every single message, thereby saving costs and processing.
As an example, in the diagram shown above messages are being published to the Orders SNS topic and each of the SQS queues subscribed to that topic have a filter policy listed. SNS uses this filter policy to filter and route the matching messages to the respective SQS queues. Note: This is indicated using different color coding in the image above. Messages colored in Red are sent to Orders Queue and ones in Green are sent to Orders-EU Queue.
Here is an example of what a filter policy could look like:

Filter Policy: https://event-driven-architecture.workshop.aws/4-sns/3-advanced-filtering/adv-message-filtering.html
Use a filter policy only when it makes logical sense - i.e. the subscribers are interested in similar types of events and have similar access permission requirements to that topic. Don’t use it to push unrelated events into a single topic, that would complicate things.
3. Consider throttling your Lambda Functions that are consuming events
Inline with the best practices on cost optimization and guarding your event consumer, this technique is extremely useful in an enterprise setting where there are multiple serverless components, possibly owned by different teams under the same AWS account.
Lambda concurrency limit is at an account level, that means it is shared by all the Lambda functions under that AWS account. However, you can also have a function level concurrency limit configured in advance called reserved concurrency. It can ensure other functions don’t take up your reserved quota. It can also throttle your Lambda function invocations when there is a burst of messages that your function is subscribed to process. Keep in mind that your function's concurrent invocations will not go beyond this setting even if there is room in the unserved concurrency.
This can help reduce load on downstream dependencies like a database or another API and can help keep your costs under control. Additional requests to your function beyond the limits assigned will fail with a throttling error. Refer to point 9 below on retries for different types of errors.
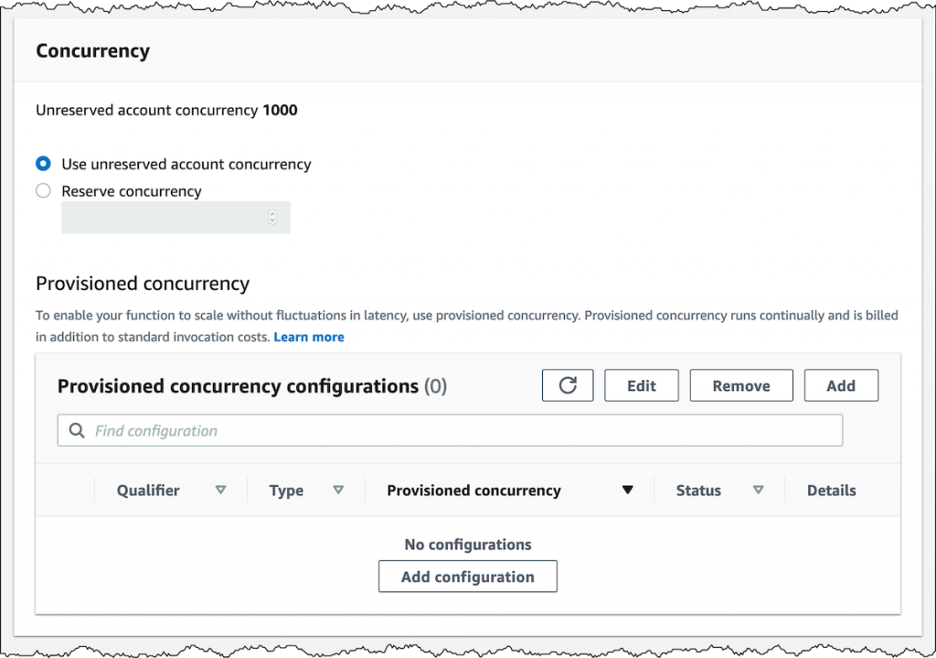
Reserved Concurrency: https://aws.amazon.com/blogs/aws/new-provisioned-concurrency-for-lambda-functions/
4. Consider using the long polling feature in SQS
With SQS, consumers can either receive messages from the queue using short polling or long polling. When consumers use Short polling, SQS immediately returns messages from a subset of the servers where messages are distributed. This can result in empty responses or a subset of the messages not being returned to the consumers. Consumers are forced to do more sweeps to fetch the complete messages available on SQS. Example below where SQS messages A,C,D, and B from servers grayed out and it did not return message E.
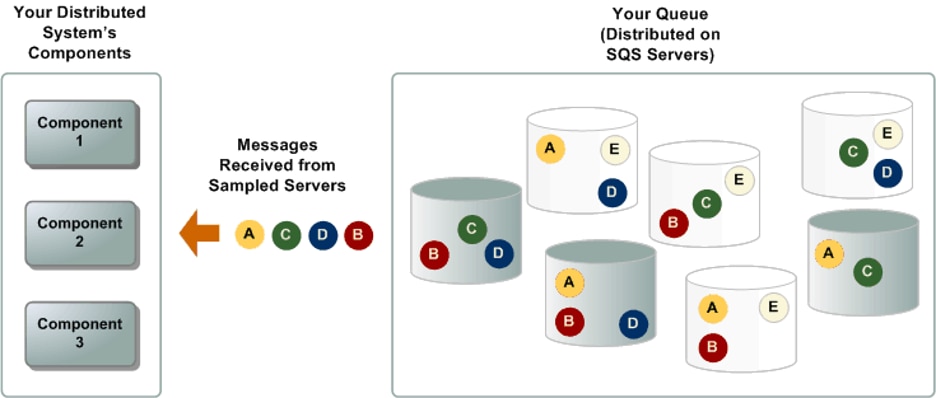
Short Polling SQS: https://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-short-and-long-polling.html
AWS pricing increases with the number of polls to the queue. Long polling is a mechanism to stay connected to the queue for a longer time (up to 20 seconds) and as soon as a message arrives, start processing. This can reduce your costs as it will reduce the number of polls resulting in less empty reads and getting a complete set of messages from all servers. You can configure this per queue, it is called Receive Message Wait Time.

In the case of AWS Lambda using a SQS trigger, Lambda polls the queue (using long polling) and invokes the function synchronously with an event that contains messages.
5. Consider using batch size with Lambda and SQS
Let’s say you have SQS as an event source for Lambda - i.e you have configured a SQS trigger for your Lambda function. In this case Lambda reads messages from the SQS queue and calls your function synchronously.
If your Lambda function code does some common initialization - like enriching data for every message that it processes, or it doesn’t have slow processing issues with downstream dependencies, etc. - it might be better to do a batch pull of messages at once. This can help save some processing time and costs. You can configure batchSize (up to 10) when you setup a SQS trigger as an event source for Lambda. Your function timeout should factor in time taken to process all messages.
When your function successfully processes a batch, Lambda deletes those messages from the queue. However, be careful about error handling here. If one of the messages that you pulled in the batch fails to process, the entire batch of messages in the SQS queue will become visible to the other consumers. Your options here would be to either be prepared to re-process the same batch again or to safely handle that exception in your code and return a success to the Lambda service that pulls from SQS (you can then leverage DLQs and explicitly send failed messages there or take care of explicitly deleting messages yourself in your function code).
Also, using batch operations with SQS FIFO queues gives you more throughput than without batching, so you can read more number of messages per second.
6. Set the right visibility timeout in SQS
Visibility timeout for an SQS queue defines the period for which a message, once picked up by a consumer, remains hidden from the other consumers. Before the visibility timeout expires, the consumer that picked up the message needs to explicitly delete it from the queue, so that it does not become visible to other consumers.
Define a visibility timeout (shown in the image above) that is a little higher than the maximum processing time your application would need to process messages from the queue. Setting this too low compared to your application processing time would result in other consumers receiving the same message again, even if your application was successful in processing the message. Setting this too high would result in other consumers not getting the failed messages in a timely manner.
7. Set the right retry count when lambdas are the consumers of SQS
When Lambda reads a batch from a SQS queue, the entire batch of messages is hidden until the queue’s visibility timeout. As messages appear in the SQS queue, Lambda initially opens five parallel long polling connections to the queue to perform the reads. If there are messages still available in the queue, it will increase the number of processes that are reading messages to 60 more instances per minute, with a maximum of 1000 batches, that can be processed in parallel.
All the Lambda processes doing the reads of the batches synchronously will attempt to invoke the Lambda functions. But, what happens if the Lambda function invocations are throttled? The messages that can’t be processed as a result would become available after the visibility timeout.
AWS recommends that you set the maxReceiveCount to at least five in your redrive policy for the queue so that messages can be retried before sending them to DLQ. Also, AWS recommends setting the visibility timeout of the source queue to at least six times your function’s timeout to allow for retries due to throttling, Lambda cold start times, etc.
8. Get to know lambda’s error handling & where to attach your dead letter queues to capture all errors
Lambdas process SQS messages synchronously and SNS messages asynchronously. If you have a DLQ for the SNS topic and Lambda is a subscriber to this topic, that DLQ will only consist of messages that were unable to be delivered to the Lambda service (due to permissions or service unavailability) after all the retries. It will not contain messages that were successfully delivered to Lambda, picked up by your function, but unsuccessfully processed due to some other code or runtime issue. It will also not contain the throttling errors due to which your Lambda function could not be invoked.
The retries for such scenarios are handled by the Lambda service using its internal queues. You can configure the number of retries, max age of the event, and where to send failed messages to SQS, SNS, EventBridge, Lambda, etc.

Lambda Asynchronous: Send failed messages to a new destination: https://docs.aws.amazon.com/lambda/latest/dg/invocation-async.html
Learn more about the different types of errors for Lambda’s.
9. Know when to use AWS EventBridge
So far we have been talking about best practices when using SQS and SNS. However, there are scenarios when they are not the best tools for the job. Recently, AWS rolled out Amazon EventBridge as another event bus with unique features that differentiate it from SQS or SNS. EventBridge was previously called CloudWatch Events, which was mainly used as the event bus for AWS resource state change events (example: EC2 instance terminated) or scheduled events (example: Using a cron expression to trigger a Lambda).
AWS EventBridge supports a lot more clients as an event source and more destinations compared to SNS. It can deliver events to other AWS accounts which is an extremely useful feature in an organization where different teams each owning different accounts may want to subscribe to events in other’s accounts. One more awesome feature that it provides is that it can ingest events from third party SaaS applications and trigger its destinations. Example: You can configure EventBridge to get incidents that are created or updated in PagerDuty delivered to a Lambda function which can create a log of it.
There are a lot more useful features that EventBridge provides such as event routing using rules where you can filter messages based on the content of the event (unlike SNS where you have to rely on MessageAttributes with some limitations). Also, you can transform the event before sending it to the target.
However, compared to SNS there are currently limitations in the number of targets per rule, its permitted throughput, and latencies. This might change in the years to come as this is still a fairly new AWS service.
***
In this post we covered best practices for event-driven serverless architectures using the AWS solutions SNS, SQS, EventBridge, and Lambdas. I hope that this gave you some ideas on opportunities for cost optimization, gaining efficiencies in processing, and minimizing errors when using AWS solutions on event-driven serverless architectures.




