Active-Active Shared-Nothing Database Architecture
Choosing the right pattern for the right case

Preamble
“Hard to believe it’s not possible,“ implored a confused Ted. “This is 2020; surely, there must be another way”.
It was a teaching moment for Acme Widgets. A database in their technology stack failed and brought down a lot of their services. Ted, the Chief Technology Officer, called an emergency meeting of the senior technology leaders to chart out a course of action for tactical and long term solutions. One of the solutions he thought of was to convert all databases to active-active with no shared assets amongst them, spread geographically to reduce risks; but with no application changes. All eyes turned to Jane, the newly appointed Chief Architect, for her perspective. To everyone’s utter surprise, Jane calmly pronounced that not all databases can be Active-Active Shared-Nothing (AASN) without application refactoring. And, she also explained, that for some it is not possible and for some it is not even required to be.
This is not a new situation for Jane. As a data leader in many organizations before coming to Acme, she has had to educate many other technology leaders on the delicate nuances of data resiliency, which is different from application resiliency.
She knows from past experience that explaining what can or can be done with clear examples is the best way to prove the point of what is best for Acme.
Getting the Basics
First things first, Jane announces, is to get the definition of AASN right. It means two copies of a database in two different geographic stores with the same data both serving the copies of the application running in that data center as shown in the figure below.

Applications A1 and A2 are just copies of the same application running in two different regions--R1 and R2. Databases D1 and D2 are copies of the same database running in different regions. The databases are replicated bi-directionally, so changes to one persists in the other. A1 connects to D1 and A2 connects only to D2. The copies of the databases D1 and D2 do not share anything among themselves.
Jane reminds them that there is nothing shared between them, so systems such as Oracle Real Application Clusters (https://www.oracle.com/database/technologies/rac.html) - which share the storage or depend heavily on a synced up share storage system - do not qualify. Since they can be completely independent of each other from an availability perspective, it brings the resiliency. But, Jane stresses, that is not always possible, and not even required in many cases.
“Not required?” asks a confused Ted, “Wait, we have to have high availability for our databases, don’t we?”
“Yes, we do,” replies Jane. “AASN database architecture is often conflated with high availability; but they are different concepts.” It is possible to implement high availability in the data tier with a "hot" standby database in a perhaps a different geographic region. The standby database takes over when the current primary database fails, starting at the point of the last transaction. With proper technology and good architecture it is possible to reduce the Recovery Point Objective to 0 - i.e. no data is lost during the primary failure. Unfortunately that often comes with the possibility of a brown-out, i.e. the very small but perceptible period of time where no database is available for normal servicing. With proper architecture it may be possible to reduce that system outage or brown-out time to near zero. However, she warns that this is key, designating that hot standby database as an also-available active database is generally not possible except under very specific circumstances. Therefore the system is highly available; but may not be termed Active/Active.
“I see what you mean,” agrees Ted. “We can be highly available but not necessarily active/active with no shared assets.”
So how can we develop, the audience muses, a truly Active/Active architecture with shared-nothing assets in the database tier? As long as we approach it with caution, Jane replies, and don’t expect one size fits all prescriptive solution, it may be possible in many cases. In this article you will learn various patterns of AASN database systems explained by Jane, and the architectural considerations that must accompany them.
State of the Application
“You mentioned AASN is not possible in many applications,” inquires Ted. “Can you explain those cases?”
The key, Jane explains, is careful application design, especially that the applications be stateless and not need to cross over to another copy of the database for validation. Where maintaining a state in the application is necessary, for instance in the case of e-commerce order updates, an AASN architecture in the database comes with huge data integrity risks. The ideal scenario for implementing an AASN database tier is in the case of read-only databases where either the application’s state does not change or it does change but an eventually consistent state is acceptable. In the latter case, Jane warns, the application needs to be aware of and should be able to handle the possibility of conflicting changes made on the database copies.
The audience urges her to expand on what the application needs to do. Jane continues: the application needs to know about the three constraints of AASN database tier:
- Eventually, not immediately, consistent datastores.
- Potential conflicts due to changes occurring in the same record in both copies.
- Potential corruption of data due to one update coming in late after a conflicting update at the other copy.
Traditional Approaches
Jane continues her narrative on the approaches. First, she talks about Active/Passive Shared-Nothing (APSN) architecture, stressing the word “Passive.” Here is a traditionally accepted view of an APSN architecture in the database tier:

In this diagram, A1 and A2 are two instances of the same application running in regions R1 and R2 respectively and connect to database D1 (Master) and D2 (Standby). The database D2 is a hot standby of D1 that is constantly updated by some type of database replication technology. When the region R1 fails, the database D1 fails as a result. The database D2 simply assumes the responsibility of the primary datastore. After the failure of region R1, D2 becomes primary and the application load balancer sends the traffic to that region. At any point in time, only one copy of the data is master.

Brown-Out Period
However, before the load balancer can send the traffic to application A2, it has to make sure that the standby database is completely caught up with the changes made to the database D1. This period, however small, is still perceptible to the application and is called a brown-out period. The duration of brown-out depends entirely on the amount of changes made to the database D1, and could be possibly zero during periods of no or low activity, Jane explains.
But, the audience wonders, is it possible to eliminate the brown-out period?
Sure, Jane clarifies, it is possible to eliminate the brown-out period in a database tier; but to ensure the sync-up is not lagging behind, the replication needs to be synchronous. While that sounds good, in reality it carries two penalties we have to consider:
- It is typically very expensive, especially across regions, since the data must be transported using a very low latency medium.
- It adds performance overhead to the applications, since the database must get the acknowledgement from both D1 and D2 before sending the commit response to the application.
Therefore, database replications are generally asynchronous and hence some degree of brown-out is inevitable.
Hot Standby
That put a damper on the mood of the audience who expected to have a quick answer. Jane continues her narrative. After Region R1 comes back up, the replication in the reverse direction is started.

Jane draws the attention of the audience to the fact that in this architecture there is only one "master" copy of data. The other copy is always merely a standby. This eliminates any possibility of conflict between datastores. Active-Active Shared-Nothing datastores on the other hand assume that both datastores are always masters with replication going in both directions and the application load balancer sending traffic to both. This way when region R1 fails the load balancer merely stops sending traffic there, with all changes from D1 already available in D2 and hence no brown-out period.

“Awesome!” announces an excited Ted. “Why can’t we just convert our datastores to Active-Active Shared-Nothing, from Active-Passive Shared-Nothing? Why do we need to change our applications?”
And this is where the problem lies, Jane explains. Depending on what the application intends to do, it may not function at all, or may function with silent data corruption. And that’s what we want to watch out for.
The two phrases hung out like swords in the air--”may not function” and “silent data corruption.”
“Please explain,” implores a clearly intrigued Ted.
But before explaining further, Jane wants the audience to understand some basics of data management.
CAP Theorem
Jane poses a question for the audience to ponder on, “When we store multiple copies of the same data in two datastores to address the failure of a single copy, what happens when a copy fails?” Will the other copies be in a state to immediately assume the operations from the failure? They may, or may not, depending on the architecture. This is where rules of CAP Theorem - Consistency, Availability and Partition Tolerance (https://en.wikipedia.org/wiki/CAP_theorem) - come in.
Consistency: If there are multiple copies of data in different datastores, then are they all 100% synced up with one another at any point in time? If so, they need a high speed, low latency network. But as the time to get the commit acknowledgement from all the datastore is now longer, it negatively affects the performance of the applications.
Availability: If one datastore is not available, can the other copies take over in such a way that the application gets a non-error response. Remember, this is merely a response given by the datastore to the application. The most recent update may or may not be available there.
Partition Tolerance: When the messages between the copies of the datastore are dropped, can the application still function? This is without any guarantee that the surviving copies are all synced up.
CAP Theorem, Jane explains, states that in any design we can have only two of the three attributes; not all three.
Another way to look at this issue, she explains, is by the venn diagram shown below. Note that there are places where two of the three attributes have overlapped; but there is no space where all three have converged. It’s very important, Jane stresses, to understand that the convergence of the three is simply not possible. For instance, if we strive for consistency, we can't design for availability; but then what happens when a copy is down? When the copy comes back up, we have to suspend the operations on the datastores until we can sync up the newly brought up copy with the surviving ones. Otherwise the newly brought up partition will be inconsistent, violating the "C" in CAP.

Eventually Consistent State
So, what is the point of maintaining the copies if they are not consistent, the audience asks.
Maintaining a copy simply means that the datastores are synced up asynchronously; therefore they will be eventually in sync. But at a given point in time the system cannot guarantee that the data stores are 100% in sync. This is called eventual consistency rather than immediate consistency. It is crucial to appreciate the difference.
To illustrate the point, Jane shows them an example architecture of a data system with three datastores which satisfies the A and P in CAP theorem, leaving C out, i.e. eventually consistent.

She explains the scenario: assume the value of a data element as 1, which was initially the same in all the three datastores. Now application A2 updates the value to the 2. Since the architecture favors Availability and Partition Tolerance over Consistency, the other two datastores may not have gotten the update. At this time, if the application A3 reads the data element it may get the value 1, not 2, which is the most recent value. This may be unacceptable in many cases where the most recent value is not just desirable but absolutely necessary,. e.g. in an e-commerce order. The datastore D3 will eventually get the updated value 3; but not immediately.
Conflict Resolution
Jane explains a second problem. She considers another scenario as explained in the following diagram. We start with the original value 1 as before, and application A2 updates it to 2 in datastore D2. But before it is propagated to all other datastores, application A3, connected to datastore D3, updates the value to 3. What will be value in datastore D1?
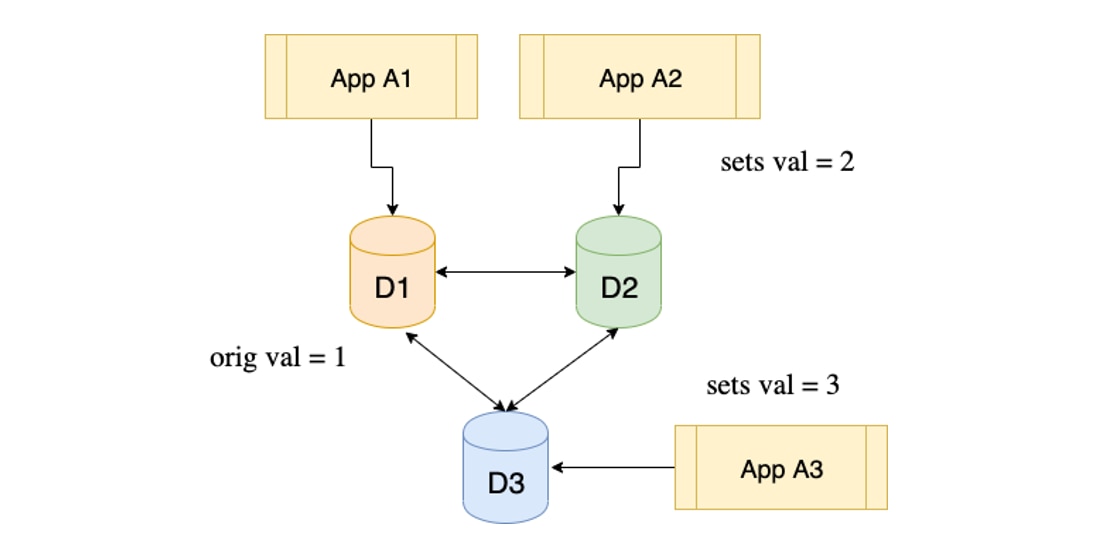
Since the data replication is asynchronous, she warns, it will be impossible to predict which update will reach first. If update from D2 reaches it first, it will be 2, otherwise it will be 3. This unpredictability in many cases may be unacceptable.
A similar problem arises for D2. Should it disregard its own update and update the element to 3? The same question applies to D3 as well.
Conflict Resolution Handling Techniques
Ted and the audience now have a clear understanding of the potential problems of Active-Active Shared-Nothing architecture. But they wonder aloud, is there any technique to avoid these problems, especially the conflict resolution?
There are ways to handle conflicts, Jane responds, but none are transparent to the application's functionality and data accuracy. Here are some of the techniques, in the order from least to most complex to implement:
- Last Man Standing: The last update to come in, regardless of the source, is applied. In the above case the value 3 will be applied to both datastores D1 and D2, assuming the messages occurred in that order. However, there is a possibility of a race condition where the updates will be cascaded multiple times. Database systems typically have built in kill switches to avoid these race conditions.
- Timestamp Weight: Is very similar to the last man standing solution, with one caveat. Rather than relying on the order of updates coming in, it checks the timestamp of the updates and compares the updates along the lines of timestamp alone. This requires all the three datastores to be synced up with a single time server (which somewhat erodes the “shared-nothing” part); but it is probably more fair and avoids the race conditions.
- Locality Weight: Each datastore is assigned a weight. The update from the highest weighted store wins and is applied to all the other datastores. In the previous example, if the weights of D1, D2 and D3 were 300, 200 and 100 respectively, then the value will be 2 eventually, since that was the update from D2, with weight 200, compared to D3, with weight 100. So the value will be updated to 2 in D3, overwriting its own change of 3. Similarly, D1 will be re-updated with 2.
- Application Weight: Each update is tagged with an application ID and each application is also weighted. The highest weighted application's changes are eventually saved.
Jane pauses here to direct the audience to ponder the impact of these techniques. “We are talking about discarding the changes in a datastore and replacing it with another,” she says. “Regardless of which technique is chosen, the implications on data accuracy are very high. We must take it into account from within the application's design; not the datastore architecture.”
The audience has been in agreement with what Jane has been saying all along but are now curious about what kind of architectural decisions can be made to take advantage of AASN and when.
Architectural Decisions
Generally datastores are divided into multiple types depending on their usage, Jane explains:
- System of Record: The datastore is used as a system of record for the application. It must be consistent without any ambiguity or questions around the veracity of data.
- System of Reference: The datastore is used as a secondary system of data, used for reference. Analytical stores fall in this category. Machine Learning, historical data analysis is done on this datastore.
- Read Only: The datastore is used for read only activities and no update ever happens.
- Static Content: The datastore is used to host static content. Examples include hosted images for web properties and marketing collaterals that do not change often.
- Cache: The datastore is used for caching data across multiple applications for faster access and is extremely sensitive to latency.
- Session State: The data is local to a specific session of the application and is irrelevant outside the session. Examples include putting behavioral data for users' interaction in an application, shopping cart, cookies, etc.
The architectural pattern acceptable for active-active consideration in a database tier, Jane continues, is dependent on the usage of datastores. On the extreme end of the spectrum, a session state datastore holds data which is relevant only to that session and is not visible outside. Creating a copy of the datastore elsewhere is not useful to the application since it cannot read the state from there. Therefore, an active data architecture actually does not add any value and is not relevant.
The audience agrees that a copy of the database is not even needed, let alone active-active, but wonder where else they may be relevant. In some other cases, Jane explains, such as in a shopping cart datastore, we may want to persist the data beyond a datastore failure. In that case a secondary copy is useful, but an active-active architecture is not required. An active-passive database configuration helps as the new instance of the application merely picks up where the old, now dead instance of the application at a different location, left off.
On the other extreme end of the spectrum, a System of Record datastore needs consistent, unambiguous and unquestionably accurate data, making it less suitable for active-active datastores. If an AASN data architecture is used, Jane explains, the application must be designed to handle the conflicts that will be inevitable in this configuration. These are not trivial issues to address. “In my experience,” Jane opines, “almost all SoR databases are not suitable for AASN architecture and most cannot be. Even those which can be will need very drastic application refactoring and often the cost outweighs the benefits.”
The audience, particularly Ted, now understands the essence of Jane’s original reticence on this issue. “Clearly the SoR database such as e-commerce order update is not a great candidate for AASN,“ he reflects. “On the other extreme end, the session state datastore is perfect; but does not even need copies of the database. But what about all the use cases in between these two extremes? What will be needed to take advantage of AASN for all those?”
The other patterns in between these extremes, Jane explains, can benefit from AASN datastores, but must be able to address these two questions:
- What will be the conflict resolution strategy - Last Man Standing, Time Weight, Locality Weight or Application Weight?
- How will the application address the logical change in data due to the conflict resolution?
Debbie, the head of application development at Acme asks Jane to expand on this a bit more.
Jane considers the case of an application cache. If the two datastores are updated differently, there will be cases where the cache will have different values. In most caches that may be acceptable, as the final value can be derived with certainty from a System of Record. A System of Reference also follows the same pattern. A machine learning training application may not be affected by minor changes in data. Most data analysts perform aggregations which do not change materially with small variations of data. So they may be all right in the eventually consistent state.
Stretching it a bit further, Jane gives another example of a self service lookup system to display the order history of the customer. Since a different database, not that of the System of Record, is used, there is no guarantee of the consistency of the data anyway; so the possibility of data drift between multiple copies does not add any additional risk. But not all Systems of Reference are used that way. If the system is meant to be an accurate copy of the System of Record, then this condition fails.
“In my experience,” Jane opines, ”no such system exists in real life, except when a point in time data is made available for reference. For instance, imagine in the case of the account lookup system where the account balance as of 12:00 AM every day, not as of now, is available. An AASN data infrastructure handles it well.”
It’s not just a data tier change, she reiterates, AASN may require a change to the application design and even the business intent of the application as well.
Application Design Patterns
Now that Debbie understands the nuances of the AASN data tier, she wants to learn some of the application patterns to leverage it.
Stateless vs Stateful Applications
The key to the design, Jane explains, is the question: is the application stateless or stateful?
Generally, an application interacts with a datastore multiple times within a single thread of execution. Does it need the database to maintain the state of the application, or does the application need to keep track of it? Or, does the application assume that every database call is independent of the other? If it is the latter, it is called a stateless application. Stateless applications are easier to implement with an Active-Active Shared-Nothing data tier.
Jane explains the patterns:
Pattern 1: Many Masters but Only One Active
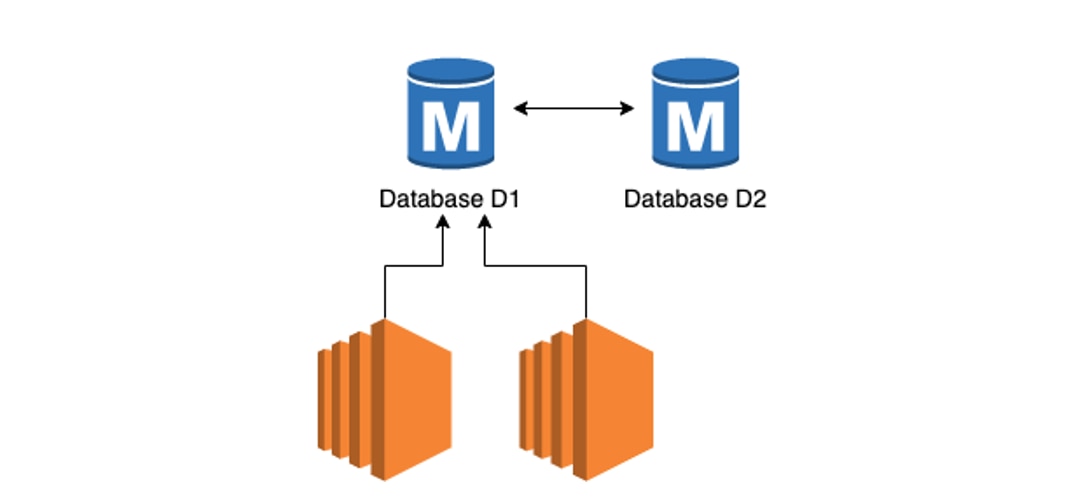
The datastores are all masters, i.e. the replications go on between all of them bidirectionally. However, Jane warns, only one of the datastores is marked as Active. If that fails, then the other master can be made Active; but at a given point in time only one is Active. By making sure all are masters, we improve the brown-out timing. And by making one master as Active we eliminate the possibility of conflicts and the associated risks.
“You said we improve the brown-out timing,” interjects Debbie, ”not eliminate them. Why?”
“That’s because the replication is asynchronous,” explains Jane, “causing the other master to be potentially lagging behind, even if a little, or even zero.”
Pattern 2: One Master and Many Standbys (Readers)
We create only one master but multiple replicas which are used for read-only access (hence no updates occur there). Some applications are purely read-only, which can go against any of the readers. After a disaster we can convert one of the readers to a master and point the transactions to that one. Since there is no active-active database, we eliminate the possibility of conflict. However, Jane warns, activating the readers takes some time; so the brown-out is a bit longer than the previous pattern.

Pattern 3: One Feeder and Many Readers
This is a combination of the two approaches shown above, but with a twist. All datastores are masters and are active-active; but one (Database F) is sort of an uber-master, called a "feeder" database. All applications connect to all the databases and update them. To maintain consistency, the feeder database is assigned a very high weight, which makes its own updates a lot more and propagates to the other masters. The other masters can also be updated but not as frequently. The chance of conflict is low, Jane warns, but not completely eliminated. If there is a conflict, the update from the feeder datastore overwrites the local changes.
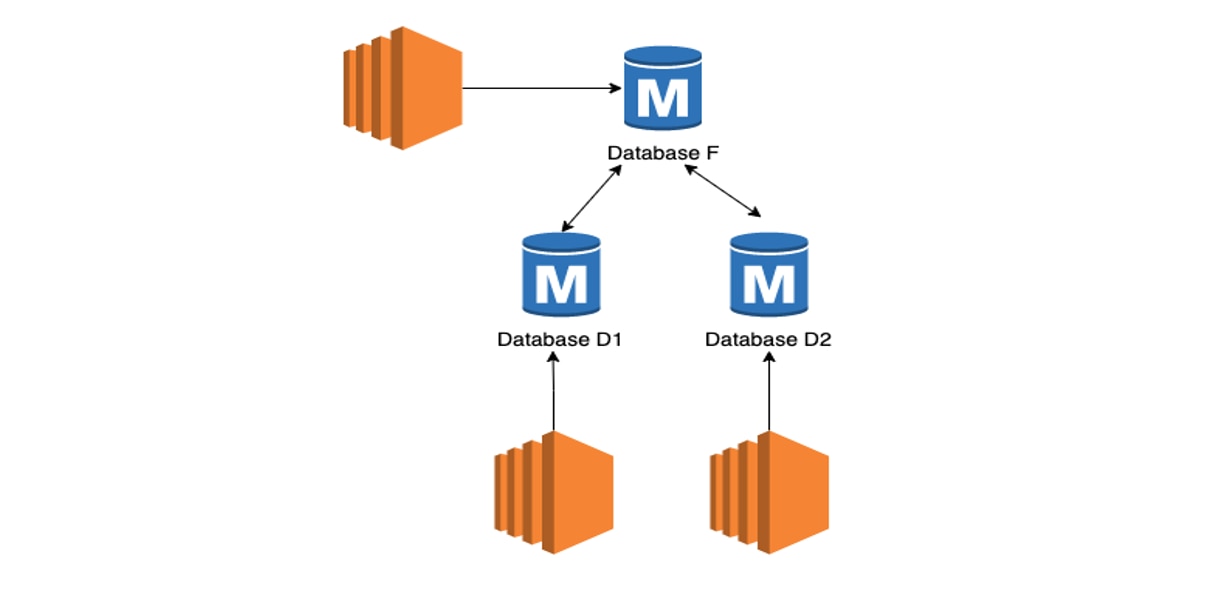
Pattern 4: Many Masters but Updated by Application
This is perhaps the most practical usage of the AASN, Jane opines. Here all the databases are masters but instead of using a database replication strategy, we use the application to update them directly.
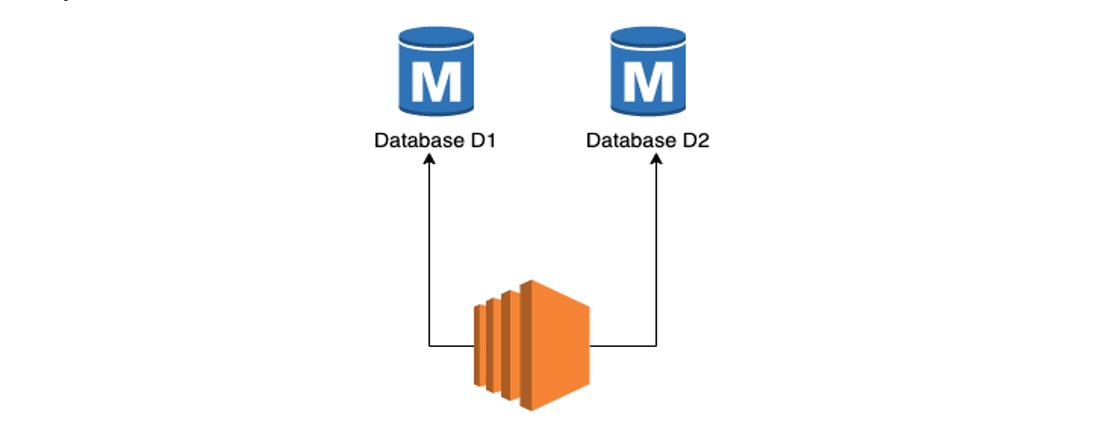
Jane draws the audience’s attention to the facts that there is no replication between the databases D1 and D2. The application updates both databases independently. Since there is no database level replication, there is no possibility of conflict and hence no consequent risks. As far as database technology is concerned, each database is unitary, i.e. no other partitions; so CAP theorem does not apply.
Pattern 5: Multiple Masters Buffered Writes
Pattern 4 presents a different problem, Jane notes, because of the number of database writes. The application can't continue until it gets the acknowledgement from all the databases. This may add to the latency issue, especially if the application is database-chatty. To address that issue, in Pattern 5 we employ a messaging layer in between. The application streams to the messaging layer instead of the database. A separate process picks it up from the messaging layer and writes to multiple master databases. The application gets the acknowledgement when the write to the messaging layer is complete, hence it is very fast.
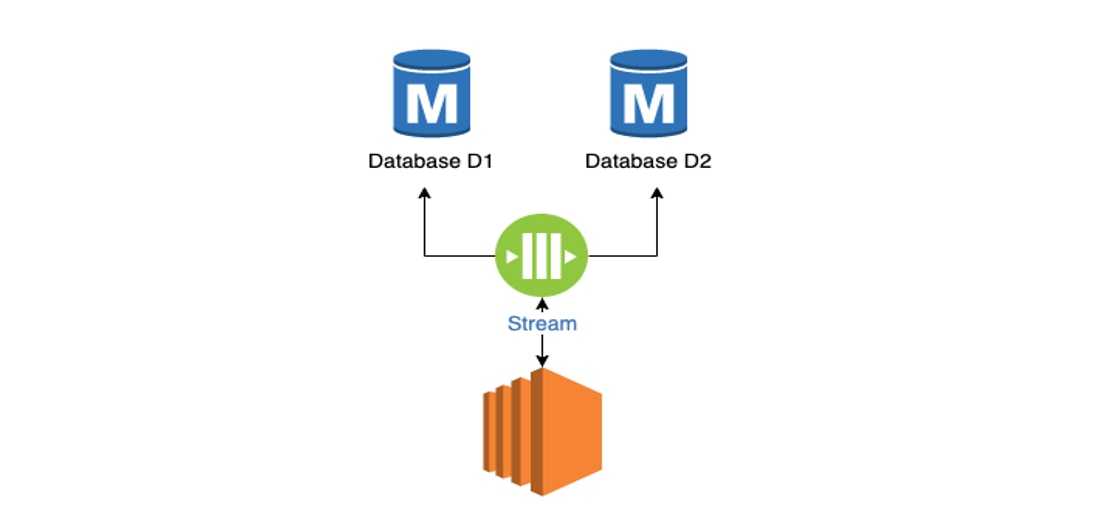
Debbie is visibly excited by this pattern; but Jane warns that while it sounds simpler, it adds two risks:
- There is more Latency to the overall data availability. The data is not written to the database when the application commits. It's written when the other process picks it up and writes to the databases.
- The order in which data is written is not guaranteed; so there may be data consistency issues.
Because of these limitations, Jane explains, this pattern is best suited for static or less frequently changing content - cache and Systems of Reference - and never for Systems of Record.
Adjournment
In summary, Jane concludes that the success of the Active-Active Shared-Nothing database tier architecture depends on the type of database, its usage, and the ability and willingness of the application to handle the data update conflicts. It's never a simple case of turning on the bi-directional replication at the database level and expecting the applications will need to be ignorant of that. In general, Systems of Record datastores are hardest to implement and Session State datastores are easiest. So Acme can implement AASN at the database tier for many systems without an application change, and for some with some application change, and not at all for some. There is also no need for AASN in the data tier for some types of systems while enabling high availability in them.
Jane summarizes this in the following table:

The meeting started with a tense note; but ended with a clear understanding and appreciation of the issues and possible solutions. Ted thanks Jane profusely and adjourns the meeting.
Key Takeaways
- AASN architecture means the datastores are spread out geographically with no assets shared between them and each datastore willing to service the instance of the application running locally.
- In most cases, AASN database tiers cannot be done without application refactoring.
- Datastores are divided into the following types: System of Record, System of Reference, Read Only, Static Content, Cache, and Session State.
- It is not possible for all datastores to have AASN configuration. In general, in the above spectrum, the suitability ranges from unsuitable to suitable from left to right.
- A single data element could be updated by two different applications in two different regions, causing data conflict. The applications have to be cognizant of that possibility. Not all applications can handle it, even after refactoring.
- Almost all replications are asynchronous, which means there will be delayed updates overwriting a more recent update, causing data corruption.
- Synchronous replications, while possible, are very expensive and often impractical.
- In some database technologies, the datastores are not consistent with each other immediately, but rather eventually. This means the applications will get different data depending on which copy they are connected to.
Business vector created by tatoenjoy - www.freepik.com



