How Capital One builds micro-frontends at scale
Lessons learned building a micro-frontends architecture for Capital One’s contact centers

By Steve Husak and Noah Mandelbaum–Distinguished Engineers
Based on a presentation at NodeConf Remote 2021
Imagine yourself in the mid 2010s. You are a developer at one of the largest banks in the United States and you work on a large, monolithic contact-center application - an application that allows agents to serve customers in key moments. While the application works well, with every passing month, you find it harder to make the changes needed to keep up with the rapid pace of innovation demanded by both customers and agents.
What do you do? In the case of Capital One, you pivot.
In the past five years, our team has made the journey from a monolith to a micro-everything architecture, building a platform with more than 100 micro-frontends and a similar number of independent Node.js microservices on the backend. Today, up to 50 teams work on the platform simultaneously and can release at any time. Bugs can frequently be resolved in hours without heroics. And, of course, being Capital One, it is 100% cloud native.
The monolith emerges–the contact center application architecture
In the late 2000s, Capital One’s Card organization set out to build a contact center application to make sure we could provide the highest level of service to our customers. It had to handle a high volume of calls across 20,000+ agents and the application also had to uphold high levels of security and regulatory compliance.
As this was late 00’s, our architects chose to use .NET WebForms, ASP.Net, and C# running on Windows servers. Most of the code was server-side components; and, of course, all the infrastructure was on-premise based.
As time went on, the application grew and grew. This growth caused releases to become slower, become more risky, and slowed development teams.
Technical challenges to our contact center monolith
As we moved into the 2010s, the application began to display some technical challenges:
- Builds took a full day, with attention from a couple of build administrators starting, stopping, and re-running scripts.
- Testing took multiple teams and could take many days.
- Large sets of changes went to production all at once - and we found it difficult to back out mistakes.
- Deployments involved moving code to staging directories, then running scheduled tasks on each Windows server to put the latest code in place.
- The application was stateful and fault tolerance was suboptimal. For instance, agents would occasionally run into errors that required them to clear their cookies and browser cache.
- Limited observability made it slow and difficult to trace transactions through the system.
- Between our primary and secondary data centers, our operations team had over a hundred production servers to manage. Server configuration easily got out of sync, which meant that the same release might work differently on each server.
And yet–the system worked and solved the initial business needs. Our customers got the service they needed and it helped our company achieve high ratings in this area. Therefore our customer service agents were generally “ok with it.”
Organizational challenges to our contact center monolith
Our unique business environment meant there were dozens of key stakeholders accountable for different customers and different regulatory bodies. Negotiations about release timing became complex and communication costs became high.
More than that - our contact center agents could do their job, but they wanted the software engineers to fix bugs faster and make improvements faster - but, unfortunately, this was very difficult to do with the monolith.
Could we go faster by replacing the monolith with micro-frontends?
At first we could articulate the problems we had more clearly than provide solutions. Our wants were profound and manifold:
- Could we have anytime releases, anywhere hosting and anywho ownership?
- Could we create a platform in which developers worked with smaller, simpler codebases?
- Could we minimize the toil associated with building, deploying and running this system?
- Could we give software engineers room to innovate (within guardrails)?
- Could we limit failure blast radius?
- A modern cloud architecture to match our company’s imperative to be “All in on the cloud”.
Advances that allowed for a micro-frontend architecture
Fortunately for us, there were good things in the air starting in the 2010s:
- 2012–Capital One began to embrace APIs and microservices were blossoming like flowers. This led our team toward a microservice backend approach.
- 2013–Capital One had started their public cloud journey with AWS - our team began to consider our infrastructure as a set of disposable resources, thus avoiding the configuration drift we had previously seen.
- 2014-2015–The team began experimenting with single-page applications - meaning that most of the application code could just run in the browser. They also started to learn more about Node.js.
- 2016–Micro-frontends popped up on the team’s radar as a viable solution.
From a software perspective, Node.js and the vibrant JavaScript community proved to be a perfect fit for our use case here and both factor into our new micro-frontend design.
Current architecture of Capital One’s contact center application
Today, our team has arrived at an architecture that matches the common micro-frontend/microservices approaches laid out by Martin Fowler:

Our front-end architecture matches pretty well to what Michael Geers might characterize as an “app shell” with multi-level routing. At the foundational level, we lean heavily on standard open source software libraries and practices. For backend libraries, we use (among others) Fastify, NestJS, Pino, Restify and Undici. On the front-end, we utilize Vue.js and React.js.
All of our browser to backend connections go through Node microservices. These microservices are responsible for most of the middle-tier work you would expect in a distributed application. This includes data orchestration, business rule enforcement, and logical decisioning.
Of special note is how this architecture handles multi-level routing, page composition, and deployments.
Multi-Level Routing
Our top-level routing is heavily dependent on a specific URL pattern that includes:
- mode: The JSON configuration to use for page composition.
- domain: The organizational grouping for the functionality that follows.
- container: A grouping of applications (or components) associated with a particular area of business functionality - where business functionality is something like “check a balance”. Likewise, containers are our fundamental unit of deployment.
- app: An individual component or application needed to implement a particular area of business functionality. The “app” can be as large as complete SPA or as small as a page fragment needed.
- resource: An actual resource for the application (JavaScript, Images, styles, etc.).
/ mode / domain / container / app / resource
With this routing structure, our “app shell” can easily parse the URLs to determine where to get assets and additional configuration. In addition to the “app shell” top-level routing, each micro-frontend utilizes its own router once a user enters it. In our case, this means the Vue.js or the React router, depending on the application in use.
Page Composition
We drive our page composition through simple JSON configurations and basic “outlets” (div tags) - this allows us to load micro-frontends into different parts of a single page.
The figure below shows a sample configuration mapped to HTML outlets for page composition.
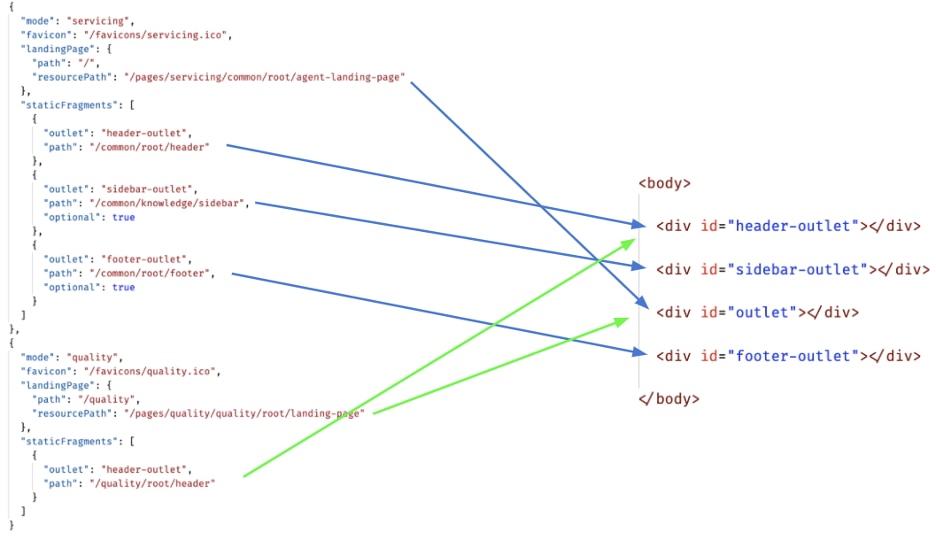
Notice that the “servicing” and the “quality” modes have different base page layouts via the configuration shown - “quality” doesn’t need the sidebar-outlet or the footer-outlet.
A composed page might look like the following:
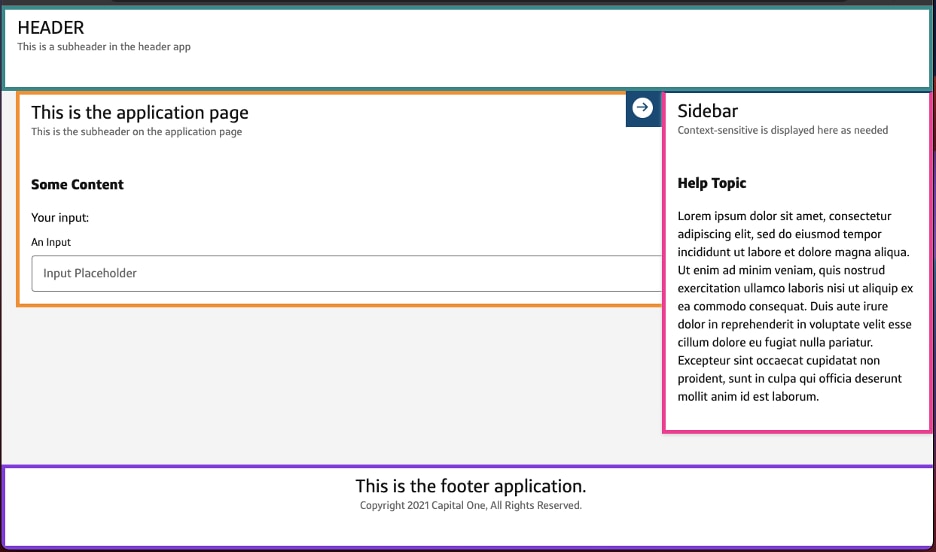
As can be seen in this screenshot, there are four visible micro-frontends on the screen. The “app shell”, which houses the overall router, loads all four applications, including:
- Green: Page header.
- Orange: The application which is the central focal point for the user.
- Magenta: Sidebar that collapses when a user clicks on the blue arrow.
- Purple: Page footer.
Deployments
All components can be individually deployed at any time, without impact to the rest of the system, using a proprietary, internal CI/CD pipeline that only requires one approval to deploy to production. This pipeline utilizes commercial tools to help us make sure our code and its dependencies are secure and properly licensed.
The following diagram shows one of many ways an application can be split and hosted. NGINX serves as a reverse proxy:

Lessons learned from building a micro-frontends architecture
At Capital One, this platform has allowed us to move much faster than before - we have gone from releasing two times a month to multiple daily releases. It has permitted up to 50 teams at a time to operate with only a moderate amount of technical and communication friction. And as mentioned above, we pivoted a lot in the design of this architecture. Along the way we learned some key lessons.
Lesson #1 - Build a foundation
In order to make our approach work, we had to put in a solid foundation to build on:
- We created a single unifying design system (composed of web components) that allowed the platform to create the illusion of a “single application”.
- We developed a standard CI/CD pipeline that allowed us to go from PR to deployment with just one approval.
- We architected an overall business domain model that helped map components to the right teams.
- We set up a system of open governance among the groups that participate in the platform, including weekly discussions on ways to improve.
- We survey our software engineers and users about their experiences - and, we act on that feedback.
Lesson #2 - Developer experience should be lightweight and flexible
During our monolith days, developers would need to build and run the entire site to see their changes - we had to frequently recompile code, redeploy changes, and restart IIS.
As we moved into Node.js and associated technologies, we started by using Docker locally to match our production environment. While this provided the value of having the local environment match the production environment more closely, we also had to give up convenience features like hot-module replacement. When running a bunch of Docker containers in this fashion, our MacBooks tended to sound like small aircraft taking off!
Today we have a more developer-focused experience which allows for the use of native tooling to the developer experience. We use a custom “developer proxy” and NPM scripting that allows us to bring the application together from pieces on the developer’s individual workstations with pieces deployed elsewhere. This approach keeps our developer experience lightweight and, it allows the developer to have exactly what they need locally versus having to run the entire system:
Our learnings about the developer experience:
- Use native tooling for the technologies in-use - Webpack Dev Server, Node.js servers for APIs, and hot reload functionality as needed.
- Add “just enough” scripting or custom tooling to bring it all together to simulate the entire application as if it is running altogether.
- Continue to invest in and refine the developer experience based on their feedback and usage patterns.
Lesson #3 - Proactively refactor
When we began our journey with Node.js, we looked to successful external companies to see how they were using Node.js and associated modules in the ecosystem to better ground some of our module choices.
One early choice was between Express and Restify. One of our deciding factors was the Netflix “Node.js in Flames” post on their technology blog. Netflix moved to Restify to improve observability and we figured we would have the same need in the future. That choice meant that as our platform grew larger, we based a large portion of our server-side code around Restify due to comfort, familiarity and delivery pressures.
Fast-forward to today: we are currently in the process of transitioning to Fastify, for a number of reasons:
- The flexible plugin architecture it provides.
- The performance increases that come out of the box.
- The vibrant ecosystem it provides, so we can continue to focus on delivering business functionality.
Lesson #4 - Memory leak analysis
Memory leaks in modern languages are not a relic of the past. JavaScript (and therefore Node.js) subtleties with closures, variable scoping and lack of exception handling can lead to memory leaks that can seriously affect the performance of your application over time.
Effective tooling and observability can help in identifying, probing and finding leaks in your code. Adding industry standard observability software to our Node.js processes has given us insight into the garbage collection and memory usage of our servers. We can see patterns and trends that help us identify potential memory leaks.
For finding actual memory leaks, we lean heavily on Clini c.js (created by NearForm):
- Clinic.js Doctor: This tool helped us find our memory leak issues in a much easier way
- Clinic.js BubbleProf: This code profiler helped us find opportunities to reduce latency between operations as well as see how the asynchronous branches of our code looked visually.
- Clinic.js Flame: Provided clear metrics via flame graphs to help us identify further areas for performance improvements.
Our lessons around memory leak analysis:
- JavaScript is not immune to memory leaks - be careful in learning and dealing with closures, unhandled exceptions, and variable scoping.
- Having observability into your running processes is needed to identify issues before they cause outages.
- Tools like Clinic.js help not only diagnose, but also measure other aspects of your code to provide insights for opportunities for tuning and performance. We also feel this toolset is important for all developers to know about.
We are fortunate in that our product team understands the value of performance increases, developer satisfaction, and the cost-savings of replacing older work with a more modern framework.
More lessons around memory leak analysis:
- Modules in the open source community come and go - for example request.
- Be ready to revisit your base assumptions on choices based on industry trends, language and runtime changes (and other advancements) - one source is the “State of JS” which is the result of surveying developers to see what is in use and how they are trending.
- As you get bigger, you have to think about the appropriate time to move to be secure and performant.
- Negotiate explicitly with your product partners as you move through the refactoring process.
Lesson #5 - Avoid breaking promises
Two years ago, James Snell gave a talk at Node + JS Interactive on how to avoid broken promises. Among the many recommendations he provided during that talk, three key items have proven to be especially relevant for our platform:
- Avoid mixing promises and callbacks - or at least understand the constraints you need to put in place to make them play nicely together.
- Don't create promises in loops.
- Understanding that synchronous promises are useless.
In response to this talk, teams working on our platform performed a pro-active code review to try to identify problem areas. We found violations for all three rules that were causing our overall platform to perform slower than expected. Fortunately, we were able to fix code in critical places before we got to full scale and prevent future fires.
Our lessons on avoiding breaking promises:
- Understand that asynchronous code is difficult for many developers - so educate yourselves and proactively refactor your systems to prevent fires.
- Learn from the best. Watch Snell’s broken promise video and read related posts on the NearForm website like this one.
- If you are operating in a pre-Node 15 environment, utilize Matteo Collina’s make-promises-safe library.
Lesson #6 - Do not block the event loop (especially through regexes)
One of the most informative guides that the Node.js community has created is called Don't Block the Event Loop (or the Worker Pool). Included in this treasure trove of information is embedded the concept of a REDOS–a “regular expression denial of service” based on “evil input”.
Over a year after the initial release of our platform, we began to find that on rare occasions, users would execute a search and the system would mysteriously freeze. Unfortunately, these freezes would occasionally occur at times when our customers needed our help the most.
It turned out a well-meaning developer had extended a regular expression and had inadvertently created a situation where catastrophic backtracking could occur when a user entered a very long string of text.
Our lessons around not blocking the event look:
- Use an APM tool (or the Node.js performance hooks if APM is not available) to keep a close eye on the event loop.
- Break complex regular expressions into smaller, simple components.
- Test all regular expressions for potential issues with a library like safe-regex.
Conclusion (or is it?)
With our Node-based platform, agents constantly get new functionality that helps them perform their daily tasks more efficiently, which in turn helps our customers. All the while, the overall micro-frontends look-and-feel makes it operate as one cohesive application regardless of how it was developed and delivered.
We’ve hit our key goals laid out at the beginning - our platform is highly modular and pretty easy to release. Our business is happy and we are delivering with the speed we need to meet our business goals. But there are always areas to improve in. For example, one thing that remains constant is the need for transparency, for documentation, and for information exchange.
Running a micro-frontend with a microservices backend in Node.js hasn’t been simple (although there are some best practices out there)–and we still have some things to still tackle–but we have found that the hard work has paid off with our current micro-frontends architecture.



