5 steps to getting your app chaos ready
Get ahead of your next outage by practising chaos engineering

Software failures and outages are a software engineer’s nightmare. To get ahead of unplanned failures, many leading tech companies - such as Netflix, Google, Amazon, and IBM just to name a few - are increasingly adopting Chaos Engineering to build resilient and reliable systems. If you are new to the concept of Chaos Engineering, below is a brief overview. If you are familiar with this concept, you can skip the introduction and dive right into the section on How to Get Your App Chaos Ready below.
What is Chaos Engineering?
Per Matt Fornaciaro, co-founder and CTO of Gremlin and Chaos Engineering Expert, you can think of Chaos Engineering as: “... a flu shot for your applications and infrastructure. You inject a bit of the bad, in a controlled manner, in order to help the system develop a tolerance.”
Going a little deeper, here is a more detailed, technical explanation published in a recent paper about creating a chaos engineering system around exception handling in JVM: “Chaos engineering is a relatively new field that constitutes injecting faults in production systems to assess their resilience. The core idea of chaos engineering is active probing: the chaos engineering system actively injects a controlled disruption and observes the impact of the disruption, as well as the reaction of the system under study.” - A Chaos Engineering System for Live Analysis and Falsification of Exception-handling in the JVM
Chaos Engineering is complementary to the static analysis and software testing you already perform for your application, with all the experiments conducted in a production-ready environment with end-user level workload. While software testing is typically binary with assertions either passing or failing, chaos testing is experimental in nature and generates new knowledge about a system under study.
The word “chaos” can be quite a misnomer since the art of Chaos Engineering is all about experimenting with failures in a controlled manner. It certainly doesn’t mean wreaking havoc on production systems. The key to running successful chaos experiments is to use controlled disruptions while minimizing the blast radius. Which, if you think about it, is anything but chaotic.
Why Should You Consider Chaos Engineering?
If you find yourself questioning the need to invest time and resources in Chaos Engineering, I might suggest you rethink how your systems will behave in the event of an actual disaster. If your answer is a variation of, “I’ve got most of the resiliency built in, but I’m not quite sure if the failover will be seamless considering the complexity and dependencies of all underlying systems” you’re probably in the same boat as most engineers. Having led my team through recovery exercises for planned and unplanned disruptions, I’ve always felt each event sheds light on new information about our systems that we didn’t know before, which has made me a big proponent of using chaos engineering to do this.

Practising Chaos Engineering can help you and your engineering teams understand your application and infrastructure better. It can help you learn what could go wrong and minimize application downtime. And it gives you the much needed confidence that your systems are truly resilient and reliable in the event of an actual disaster.
Also, if you’re a Product Owner, Product Manager, or Agile Lead you probably know very well that the stakes have never been higher to maintain the uptime of our systems. By performing chaos engineering experiments for your apps, you can count on delivering reliable, resilient products to your end customers.
How to Get Your Apps Chaos Ready?
Principles of Chaos Engineering is a good reference for anyone relatively new to this topic. Once you have a good understanding of the underlying principles, you can get started on your chaos readiness journey by using a five-step iterative approach.
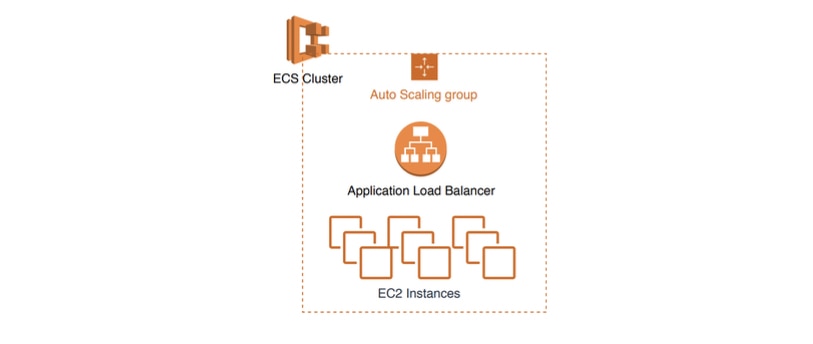
To demonstrate this approach, let’s imagine we have a notification service that sends out a message when a product is delivered to a customer. This imaginary service is deployed on an ECS cluster in AWS. There are nine running tasks and each task is a containerized unit of the service deployed on an EC2 instance. All EC2 instances are part of an Auto Scaling group (ASG) and are behind an Application Load Balancer (ALB). We’ve received customer complaints indicating they are not receiving notifications and we need to improve the resiliency of this service. Let’s use this incident as an example as we go through this five-step process.
Step 1 - Form a Hypothesis

First and foremost, it’s important to assess an application for Chaos Engineering readiness. This includes reviewing the application architecture to identify failure points, understanding the system's steady-state, and detailing out the upstream and downstream dependencies. It also includes:
- Identifying failure points for each process step and dependency.
- Understanding the customer impact for each failure point.
- Capturing steady-state hypothesis.
- Listing out existing recovery procedures, either self-healing or manual.
This should be a collaborative effort between dev and product teams. Once complete, the assessment helps group the experiments based on the impact and helps identify which ones to target first. Here is an example assessment for our imaginary notification service. Highlighted rows indicate low customer impact disruptions.

Step 2 - Plan Your Experiment

Define your steady state. The steady state is characterized by a range of metric values, and a deviation from that range the system should be considered impacted. You can use an application’s operational (Volume, Latency, Error Rate) and infrastructure (CPU, Memory, JVM) metrics to define its steady state. The “blast radius” defines the impact level of a disruption.
Always try to minimize the blast radius in each of your experiments. For example - start by terminating one instance vs. all available instances for that service. Also, define disruptions that simulate real world events such as connection timeout, hard drive exhaustion, thread death, etc.
Here are a few key considerations to plan for actionable experiments.
- Identify experiments with minimal impact to internal/external customers.
- Leverage existing Chaos Engineering tools to create a framework.
- Leverage CI/CD pipeline for increased flexibility to kick off disruptions.
Select a disruption tool and set up a framework to run chaos engineering experiments. At the end of this step you’re ready to begin experimenting.
Step 3 - Run Your Experiment

There are two phases of running an experiment:
- The control phase is a monitoring period without disruption.
- The experimental phase is a study of the system behaviors under disruption.
Run your tests in an incremental fashion. Stop the experiment immediately if you see an unacceptable deviation from steady state. Address the issues and rerun the experiments.
Here is a high-level flow for attempting to terminate one EC2 instance for our imaginary notification service. Make sure to simulate user traffic if you are attempting these experiments in a non-production environment.

Here are some tips for executing successful experiments.
- Execute and iterate through each experiment with a goal to learn from each run.
- Restrict the access to triggering experiments using specific IAM (Identity & Access Management) roles.
- Create an approval process to prevent accidental triggers.
- Take advantage of automation for a faster feedback loop.
- Capture steady state hypothesis prior to running planned disruptions.
Step 4 - Interpret the Outcomes
Now that you have results from control and experimental phases it’s time to check if the steady state was deviated. Consider leveraging the following metrics to understand results from your chaos experiments.
- CPU/ Memory utilization
- Response Times
- Service Timeouts
- Error Responses
For the instance termination experiment in the previous step, we should be able to validate if the ASG was configured correctly to bring up new instances in a self-healing way. Here are some metrics that will help identify factors that result in an increased error rate for our notification service.

Step 5 - Improve and Iterate

As your chaos experiments start running successfully, increase the blast radius of your experiments. Provided our imaginary notification service has a multi-regional active-active resiliency pattern, move on to terminate multiple EC2 instances or tasks to a point where increased failure rates trigger an auto-failover to a more stable region.
If they are not running successfully, then work on addressing the issues from your experiments.
Our instance termination experiment has identified a couple of underlying issues in our notification service:
Issue: EC2 start up times are high leading to an increased error rate and response times.
Potential Solution: Add a custom health check in addition to the default health check from ALB to signal that traffic can be routed to a new instance once bootstrapping/ provisioning is complete.
Issue: Higher error rate in second round was due to instance unavailability.
Potential Solution: Configure min, max and desired instance values in a way that at least 2-3 instances are always available with enough CPU/ Memory reservation for a container.
Also, in addition to the above solutions, a design consideration would be to add retry logic in our notification service if we want to eliminate all system errors.
Introduce resiliency patterns for your applications and rerun your experiments. Here are some of the patterns that would be applicable for our notification service.
- Update infrastructure or app level health checks
- Tune app config/ properties
- Add retry logic where applicable
- Introduce caching techniques as applicable
- Enable circuit breaking
Here is a good read for a more detailed explanation of resilience design patterns.
Get Ready for Game Day!
Now that you have formed your hypothesis, created a plan for running your chaos experiments, executed the experiments, interpreted the outcomes and as a result incorporated resilient patterns into your applications; you can increase the blast radius of your experiments. As you gain confidence with trial runs, you can schedule the experiments to run periodically on your production systems. Running chaos experiments on your production systems at a periodic basis can help generate new knowledge about the system under study and help identify strengths and weaknesses. Addressing the areas where the system is weak increases its fault tolerance and resiliency.


