Using ML and Open Source BPM in a Reactive Microservices Architecture
Taking automation to another level.
Machine learning is changing the world. Self-driving cars, conversational virtual assistants, and airline check-ins via facial recognition are a few examples of where we are headed. In each of these examples, machine learning is automating processes that the human brain has done in the past, such as how images are recognized, and language is processed.
This also extends to the processes that companies across the world use to run their businesses. Business processes are typically a great opportunity for automation, which open source BPM products can help solve. Combining open source BPM and machine learning together can take automation to another level.
For example, machine learning can be used to provide recommendations that can improve decision making in a business process. But how can we integrate machine learning and open source BPM in a reactive microservices architecture? We want our services to be small and focus on doing one thing well, while being decoupled and independently deployable. In this article, we will discuss an integration pattern for achieving this using machine learning, open source BPM and reactive microservices.
Machine Learning background
First let’s start off by providing a quick background on machine learning. It’s really a type of artificial intelligence (AI). Below is a timeline history that illustrates the different phases we will walk through.
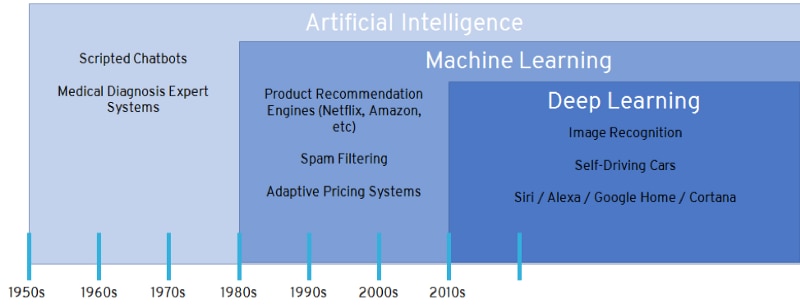
Diagram credit Patrick Wagstrom
AI started in the 1950’s with what was known as expert systems. These systems contained if/then logic that was programmed by a human. Later on, early forms of machine learning software focused on linear regression, trees, time series regression, and unsupervised learning. In the 1980’s, neural network machine learning started to emerge. In the past 25 years, machine learning software has greatly advanced and much of it has become open source.
Compute power has also become a lot cheaper and quicker to acquire through cloud computing. H2O is one such example of an open source in-memory big data machine learning platform. It provides a number of algorithms (e.g. Generalized Linear Model, Random Forest, Gradient Boosting Machine, Principals Components Analysis, etc.) for training machine learning models along with generating metrics showing the accuracy and performance of the generated model.
H2O will also generate a deployable artifact that you can include in your project, such a POJO (Plain Old Java Object) or MOJO ( Model ObJect,Optimized) artifact. MOJO is typically used when the POJO hits the size limit or higher performance is needed.
The next key concept to understand with machine learning are two high level categories — supervised and unsupervised.
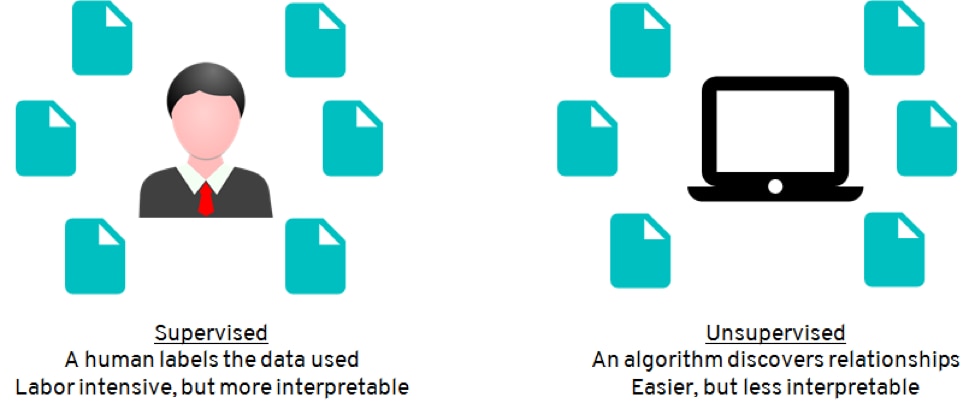
Diagram credit Patrick Wagstrom
Supervised is where you label your data and include features along with a target variable in a data set. This target variable represents the data element you want to predict, while the features are the data elements that can be used to predict the target. The target variable is provided in the dataset for past records, and the algorithms use the features to determine how to predict the provided target variable. Unsupervised is where you don’t label your data (target is not provided), rather let the software find relationships. It typically does this through grouping similar data together.
With both cases, it is always good to provide as much data as possible, so the machine learning software can be as accurate as possible. Also, it’s important to make sure the data is not biased in anyway, otherwise the model will be biased. With machine learning, the model is only as good as the data.
Integrating machine learning into reactive microservices
Now that you have some context on machine learning, let’s discuss how it can be integrated with microservices, reactive architecture and open source BPM. By now you have probably all heard about microservices and their benefits.
First let’s talk about the use case. Imagine a scenario where you have a business process that may involve some degree of human workflow along with system API calls. Machine learning could be used to help reduce the amount of workflow to the user. It could also be used to provide the user with additional information to make better decisions.
From a design perspective, you typically want to keep your open source BPM business processes light, and have it focus on the things it is good at doing. Otherwise, you can quickly end up with a monolithic application. So, have BPM focus on the workflow and have external services focus on doing the work.
To help achieve this, you can leverage Kafka as the integration mechanism. http://kafka.apache.org/
Kafka is a distributed streaming platform that can be used as an event stream in a reactive microservices architecture. Microservices are pre-programmed ahead of time to react to specific events present in Kafka. Kafka itself is fast and has high throughput, proven by LinkedIn as they use it to process billions of transactions a day. It is also often used for backpressure in many architectures, acting as a buffer between a producer and consumer that allows the consumer to read at the rate they desire. It also has configurable persistence, which can be used for event replay in a microservices architecture. This enables microservices to catch back up with any records it may missed while being down.
One proof of concept I built recently (along with David Murphy from Red Hat) uses a native Kafka extension to the open source BPM tool, Red Hat Process Automation Manager™ (PAM). (Red Hat PAM is the new name for Red Hat BPM Suite and both are based on older branches of the community project jBPM.)Extending Red Hat PAM to integrate with Kafka enables a business process to directly produce and consume events to Kafka topics. To achieve this, we created a custom work item handler for Kafka in Red Hat PAM™, along with Kie Server Extension (developed by David Murphy from Red Hat). The work item handler creates a Kafka service task that can be used in the business process to produce to Kafka. The Kie Server Extension update consumes events from Kafka, does some parsing, and then sends those events as signal events to the business process. Below is a sample diagram that illustrates the Kie Server Extension, which is based off an older version of BPM Suite 6.2 and leverages an EJB construct.
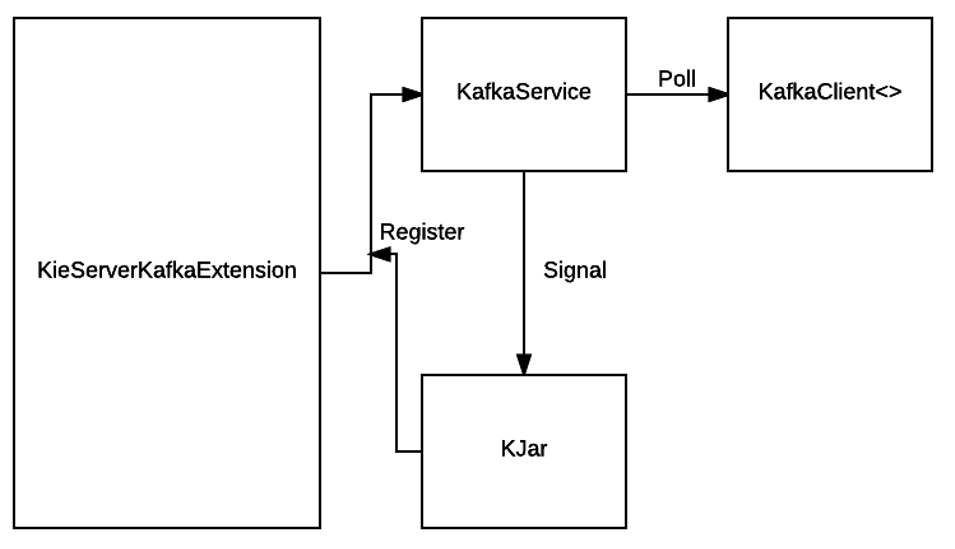
Diagram credit David Murphy
In Red Hat PAM 7.0, the architecture would look like this, which removes the EJB construct and uses the Event Emitter concept:
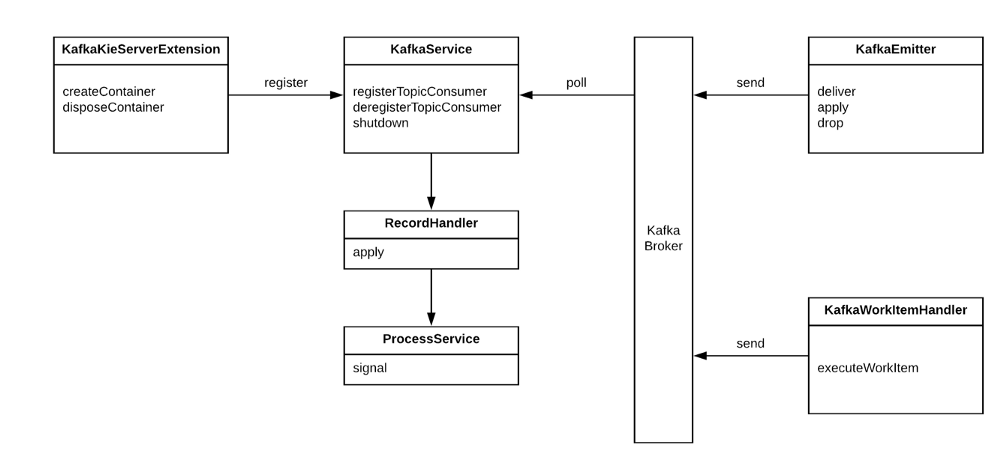
Diagram credit David Murphy
You can find the source code for the older version here: Murph / kie-server-kafka and GitLab.comgitlab.com
After connecting Red Hat PAM to Kafka, you can program a business process to produce events to Kafka that will trigger external microservices. This enables Red Hat PAM to manage just the workflow and lets the external microservices do the work.
This follows a “Hybrid — Reactive Between and a Coordinator to Drive Flow”pattern. Below is an architecture diagram of the overall proof of concept:
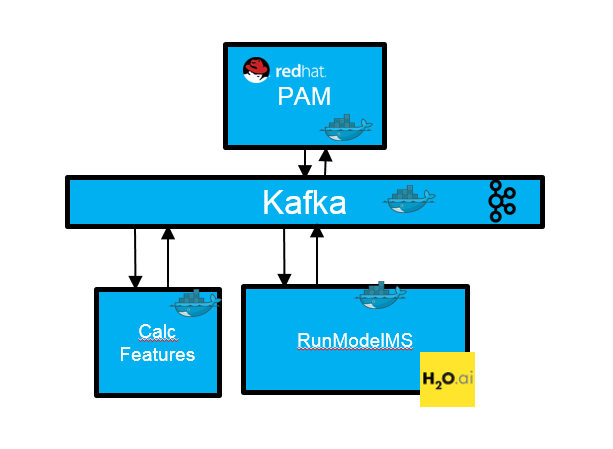
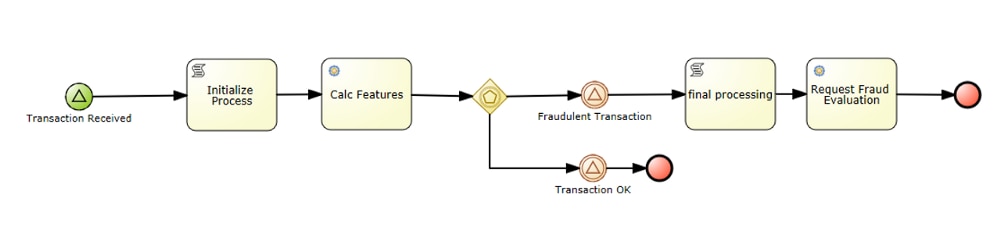
Let’s walk through this proof of concept in more detail.You can find the source code for it below:
An important concept we implement in this example are commands and events. Commands are things that need to be done whereas events are things that have happened in the past.
Acting as the coordinator, Red Hat PAM is producing commands to Kafka that the external microservices consume, do some processing, and then produce events that are then consumed by either another microservice or by Red Hat PAM. We have two microservices in this proof of concept. One for calculating the features and a second for executing a H2O model.
We intentionally broke these out, so they can be scaled separately if needed. Both of these are deployed as dockerized Java JARs that leverage the Kafka API to consume and produce to Kafka. For the H2O model, it was trained using the distributed random forest algorithm on a sample credit card fraud detection dataset from Kaggle. It includes 28 decimal features, along with time, transaction amount, and a class variable that indicates if the transaction is fraud (1) or not (0).
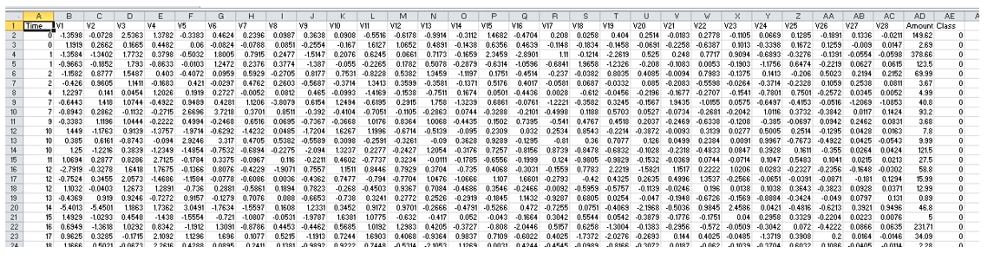
We integrated the H2O generated POJO into our Java microservice by importing it into our java project:
import com.decisioning.drf_c79982d1_29c6_47bd_8950_897ba97ba737;Next, we wrote some wrapper code to create an instantiation of the model:
hex.genmodel.GenModel rawModel = null;
rawModel = (hex.genmodel.GenModel) new drf_c79982d1_29c6_47bd_8950_897ba97ba737();
EasyPredictModelWrapper model = new EasyPredictModelWrapper(rawModel);
RowData row = new RowData();Next, we map the input variables to the row object which is an instance of a the RowData class:
row.put("Time", time);
row.put("V1", v1);
row.put("V2", v2);
row.put("V3", v3);
row.put("V4", v4);
row.put("V5", v5);
row.put("V6", v6);
row.put("V7", v7);
row.put("V8", v8);
row.put("V9", v9);
row.put("V10", v10);
row.put("V11", v11);
row.put("V12", v12);
row.put("V13", v13);
row.put("V14", v14);
row.put("V15", v15);
row.put("V16", v16);
row.put("V17", v17);
row.put("V18", v18);
row.put("V19", v19);
row.put("V20", v20);
row.put("V21", v21);
row.put("V22", v22);
row.put("V23", v23);
row.put("V24", v24);
row.put("V25", v25);
row.put("V26", v26);
row.put("V27", v27);
row.put("V28", v28);
row.put("Amount", amount);Then we execute the model:
BinomialModelPrediction p = null;
try {
p = model.predictBinomial(row);
} catch (PredictException e) {
e.printStackTrace();
}Then write out the contents of p.label (1 for fraud, 0 for non-fraud) and p.classProbability to get the results: (the JSON below is hard coded for example purposes)
//if the H2o model thinks its fraud, return Fraudulent Transaction
if (p.label.equalsIgnoreCase("1"))
line = "{\"id\":\"" + appid + "\",\"action\": \"Fraudulent Transaction\",\"data\": {\"timestamp\": \"" + ts + "\"},\"p.label\":\"" + p.label + "\",\"p.classProbability\":\"," + p.classProbabilities[0] + "\"}";
else //if h2o model does not think its fraud, return Transaction OK
line = "{\"id\":\"" + appid + "\",\"action\": \"Transaction OK\",\"data\": {\"timestamp\": \"" + ts + "\"},\"p.label\":\"" + p.label + "\",\"p.classProbability\":\"," + p.classProbabilities[0] + "\"}";
return line;Let’s dive deeper into the Red HAT PAM box. In this example, Red Hat PAM is executing a business process that is listening for signal events (represented as the triangles in enclosed circles) that are coming from Kafka which is being processed by the Kie Server Extension.
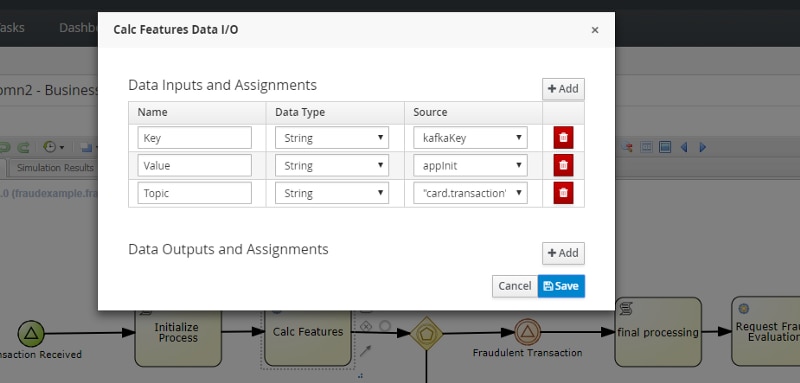
The Calc Features task is the Kafka Service task we created that enables you to produce a message directly to a Kafka topic. It takes three inputs. The KafkaKey, the Value (data you want written to Kafka), and the topic you want to produce to. In this case it is writing to the card.transaction topic and sending a value of “Calc Features” (which is what is in the appInit variable) as a command.
This appears in the Kafka topic as:
{“id”: “b0e0193b-9c2c-46d0–8dfe-12d2ac88adf3”,”action”: “Calc Features”}Next, the Calc Features microservice is programmed to react when it sees an event in Kafka with an action of “Calc Features”. It calculates 28 different numerical features and then writes them back to Kafka:
{“id”:”b0e0193b-9c2c-46d0–8dfe-12d2ac88adf3",”action”: “Features Calculated”,”data”: {“timestamp”: “2018–07–10 16:38:52.578”, “time”: “7891”, “v1”: “-1.585505367”, “v2”: “-3.261584548”,”v3": “-4.137421983”,”v4": “2.357096252”,”v5": “-1.405043314”,”v6": “-1.879437193”,”v7": “-3.513686871”,”v8": “1.515606746”,”v9": “-1.207166361”,”v10": “-6.234561332”,”v11": “5.450746067”,”v12": “-7.333714067”,”v13": “1.361193324”,”v14": “-6.608068252”,”v15": “-0.481069425”,”v16": “-2.60247787”,”v17": “-4.835112052”,”v18": “-0.553026089”,”v19": “0.351948943”,”v20": “0.315957259”,”v21": “0.501543149”,”v22": “-0.546868812”,”v23": “-0.076583636”,”v24": “-0.425550367”,”v25": “0.123644186”,”v26": “0.321984539”,”v27": “0.264028161”,”v28": “0.13281672”,”amount”: “1”}}}The run model microservice is programmed to react when it sees the features calculated and then executes an H2O model and writes back the output of the model and indicates if the transaction is OK:
{“id”:”703d2ff8–9a60–43f6–8d76–0065ec3528a0",”action”: “Transaction OK”,”data”: {“timestamp”: “2018–07–10 16:38:44.633”},”p.label”:”0",”p.classProbability”:”,0.40568148708343504"}or if it is a Fraudulent Transaction:
{“id”:”b0e0193b-9c2c-46d0–8dfe-12d2ac88adf3",”action”: “Fraudulent Transaction”,”data”: {“timestamp”: “2018–07–10 16:38:52.591”},”p.label”:”1",”p.classProbability”:”,0.022"}Red Hat PAM has a signal event that looks for the OK or Fraudulent Transaction value and either ends the process or writes back out to Kafka indicating further evaluation is needed:
{“id”: “b0e0193b-9c2c-46d0–8dfe-12d2ac88adf3”,”action”: “Evaluate Fraud”}Below is a sequence diagram that help illustrates the flow:
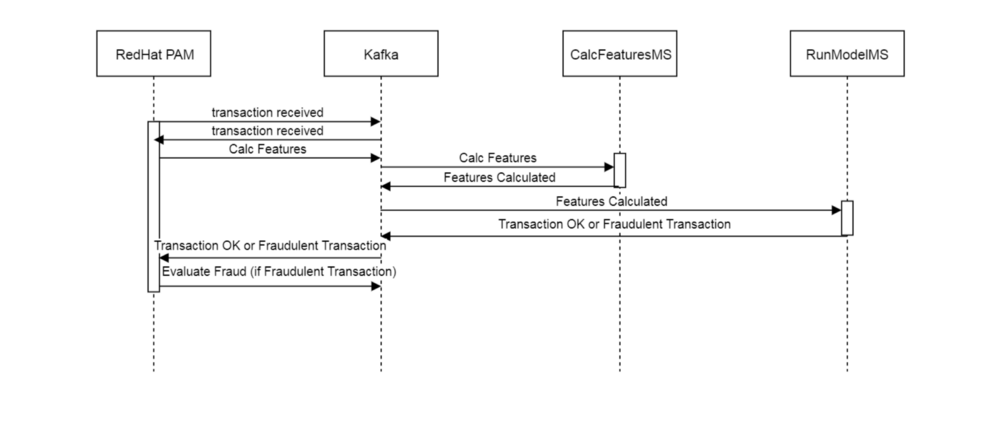
We can see the overall path taken by the workflow in Red Hat PAM by using the REST service:
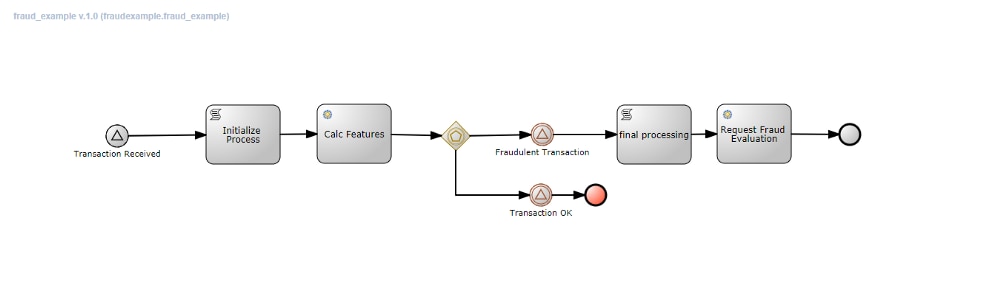
Request Fraud Evaluation Workflow Path
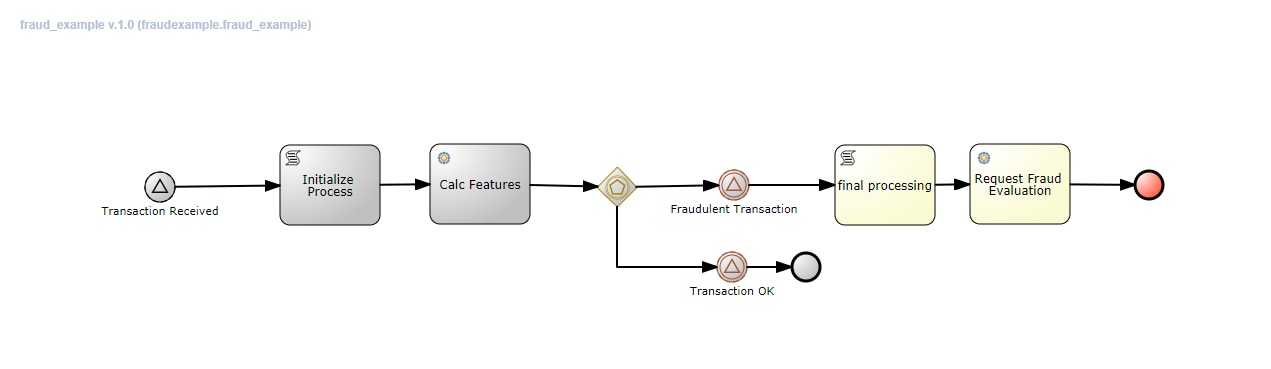
Transaction OK workflow path
Summary
In summary, this proof of concept provides a working example of how you can integrate machine learning in a reactive microservices architecture while also incorporating open source BPM. If implementing BPM as a hybrid coordinator pattern, here are some important things to consider:
● Apply the coordinator pattern where:
- There are synchronous blocks of asynchronous processing.
- There is a need to see the overall all end to end business process at design time and run-time.
- There is a need to decouple as much as possible to eliminate dependencies.
● The Coordinator can be a single of point of failure. Make sure it is worth the tradeoff and simplifies your architecture. Evaluate multi-deployment for active/active (application and database layers).
● Leverage correlation IDs in events to piece back the different events.
I hope you find this blog helpful. You can find a live demo of the proof of concept here. I’d like to thank David Murphy at RedHat for your contributions to this blog. Thanks!



