Securing Personal Devices with Machine Learning
An exploration of leveraging machine learning to limit data exfiltration on personal devices
By Jeremy Goodsitt, Rui Zhang, Sudheendra Kumar Kaanugovi (Sudhee), Sandeep Gadde, Kenny Bean, Dustin Summers, Jagmeet Singh, and Austin Walters
Many discussions of data loss prevention (DLP) typically entail the exfiltration of data stemming from either data theft or data leakage. However, as enterprise applications have become integrated into their customers’ personal devices, companies must also consider DLP techniques within these end-user devices. Additionally, DLP techniques have navigated towards using machine learning, such as Capital One’s open source Data Profiler, which can become more complicated to employ on personal devices. In this article, we discuss the complexity of limiting data exfiltration on the end-user device.
While critical to improving a customer’s mobile application experience, logging mechanisms have the possibility of unintentionally capturing sensitive customer data. At the same time, it’s important that sensitive data never leave the end-user device. So for this project, we set out to enhance end-user device data sanitization efforts prior to utilization. To that end, we focused on two sanitizing algorithms, a system of regex rules (baseline) and Capital One’s Data Labeler from the Data Profiler (a character-embedded convolution neural network).

Comparing Regex and Deep Learning for Data Loss Prevention
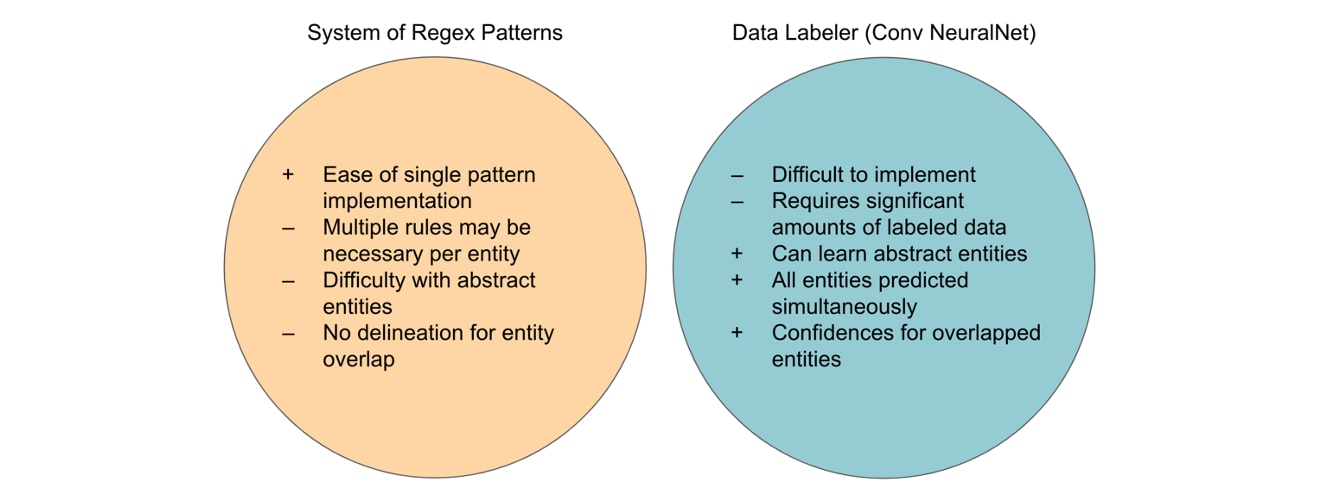
Regex has been a fundamental pattern recognition utility. Despite being easy to implement, it is not without its own drawbacks. For example, if we choose a simplistic piece of sensitive data such as a credit card number, the expected pattern is easily defined in regex. However, a credit card number can take many forms (Fig X). Depending on the implementation of the regex, this can increase linearly if each form were designed as a separate pattern.
Moreover, this only captures its boolean match: is it a credit card or not? However, this ignores whether the pattern overlaps with another sensitive data type. Instead of a credit card number, imagine the complexity of implementing a regex pattern for customer addresses or names. Without context around either of the aforementioned sensitive data types, it becomes significantly more difficult to generate patterns to identify them.
Deep learning, on the other hand, can handle complex data identification at scale, but comes with the unique requirements of large quantities of labeled data and an intimate knowledge of neural network design. While Capital One’s Data Labeler attempts to simplify these requirements by providing a known neural network architecture (Fig X), gathering the data required to train the model can be formidable.
This article offers further discussion of the model behind the Data Labeler and its training, and finds that the Data Labeler provides more flexibility for complex sensitive data types, resulting in higher accuracy on the data entities evaluated. The question remained, however, whether or not the model could easily be transferred to a mobile environment. If it could be transferred, additional questions regarding its effect on mobile application performance needed to be addressed.
Moving a Deep Learning Model to the Mobile Environment
Unsurprisingly, code conversion is specific to each mobile environment due to the varying programming languages. In this investigation, Core ML (swift) and TFLite (kotlin) were used for the conversion of iOS and Android, respectively. The initial step was to convert all pre- and post-processing systems into each respective language. Additionally, we moved the Data Labeler’s character encoding layer, a lambda layer, out of the model for both iOS and Android and into the preprocessing steps; otherwise, complications arose from this lambda layer during code conversion.

Once removed, the steps for converting the model for the two operating systems began to diverge. The iOS conversion tool Core ML worked seamlessly and the model was integrated immediately, yet Android’s TFLite required three additional alterations to the model prior to its migration into kotlin.
- The ArgMax Thresh output of the Data Labeler needed to be stripped from the model due to conversion complications.
- Input and output layers needed recasting to uint8/or float32 because kotlin had a limited set of supported input and output data types.
- A custom model wrapper was written to handle the model interaction since Android Studio’s template could not automatically interpret the TFLite model.
At this point, the model could ingest unstructured text for sensitive data scanning. But its effect on mobile application performance remained.
Validating Model Feasibility in the Mobile Environment
We evaluated four key performance metrics on a Google Pixel 3XL and iPhone XC: prediction time; application storage size; load time; and memory footprint. Limiting iOS/Android application deployments to devices supporting Core ML/TFLite respectively, the model could be deployed across 99.99% of current end-user devices.
On these devices, prediction times took ~170ms. Since these could be processed in a background thread, this had minimal impact on the overall application. Increases to the subsequent 3 metrics were minimal: <1MB to app size, <300ms to load time , and <22MB to the memory footprint. Furthermore, TFLite and Core ML give users the ability to quantize their models at the potential cost of accuracy which would further limit the effects on the application performance, however, these were not evaluated.
In conclusion, deploying a machine learning model like the Data Labeler was relatively straightforward; most of the effort focused on the code conversion for pre-/post-processing as well as the model adaptation for Android. In addition, even if the model had a significant impact on mobile application performance, both iOS/Android model conversion tools provide optimization mechanisms.
While not discussed in this article, our future investigations will evaluate model performance monitoring and tuning techniques in mobile environments which might be further complicated by sensitive data considerations.


