Time travel is real–building offline evaluation frameworks
How a “wormhole” framework can help personalization platforms leverage machine learning
The digital revolution and access to the internet through multiple devices has increased the plethora of choices available to humans everywhere. For instance, YouTube alone has 2B+ users watching over a billion hours of videos daily across PC, Mobile, OTT(over-the-top) devices. That’s virtually never-ending video content available at your fingertips [1]. Surprisingly, humans are bad at choosing between that many options, which can lead to poor decision making [2]. Many of us have spent hours searching for news or professional content on streaming sites but ended up watching random dog videos instead. This is where personalized experience platforms can help users make the right choices at the right time.
Personalized platforms anticipate each customer’s expectations and help them to make optimal decisions, leading to enhanced engagement. The ability to provide personalized recommendations has powered the growth of online advertisements, video/games streaming platforms, and search engines for decades. Similar personalization can also be applied in financial services to help customers make payments on-time, choose financial products, or receiving personalized messages to help them manage their financial health. Marketing channel communications can also be optimized with personalization platforms.
Machine learning is at the heart of any advanced personalization platform designed to help customers make those decisions. The obvious but most effective way to maximize gains from machine learning systems is to provide better data and build robust offline evaluation frameworks. But there are challenges that need to be addressed in order to see maximum benefits.
Challenges to building robust offline evaluation frameworks
Machine learning algorithms are generally evaluated in an offline environment using historical data. Raw datasets are transformed into feature vectors that go into this offline model development stage. Deploying these same models into production requires feature generation to be done with real time services. Keeping online and offline feature generation in sync is a complex problem and significant work has been done on this in both academia and industry [3].
Machine learning engineers need to go beyond feature generation and solve for these three major challenges:
- Data collection - Upstream microservices that provide data to generate features are often not built considering machine learning needs. However, doing so can be impractical, considering the evolving nature of machine learning needs. Collecting data from such disparate sources is always a challenge.
- Temporal data processing - A temporal view of multiple data sources across systems can allow us to stitch them together and build customer interactions at a given point in time (customer journey). Adding temporal dimension for stateless systems’ data and processing to identify state of customer interactions over time is challenging.
- Offline simulation environment - Building a robust offline evaluation system on above data for constantly changing machine learning ecosystem is a complex and critical problem to solve.
When building a framework, one concept that aptly represents these challenges is wormholes. [4] Just like a wormhole links two disparate points in spacetime, we’ll want our solution to retrieve data from varied microservices and build a consistent temporal view of customer behavior while providing “time travel” capabilities. These time travel capabilities will approximately restore the state of data in the systems at a given time. This leads to creating a robust offline evaluation framework where new machine learning algorithms can be *simulated* to test in a pseudo production environment. Essentially, one can simply go back in time and ask how a new algorithm/system would have responded to customer requests at that time.
Initial considerations for a building a wormhole offline evaluation framework
In order to build this “wormhole” connecting data from our numerous microservices/systems and give us that temporal view of the customer state we need two things - state persistence and a passive temporal data snapshot builder.
1. State Persistence
Any system can be generalized as a finite-state machine (FSM), or a combination of FSMs, where it can be in exactly one of a finite number of states at any given time. Systems can also transition from one state to another based on some inputs [5].
One can consider a personalization platform as a complex FSM. In this scenario, the user logs in and takes some actions such as browsing through content, web pages, videos etc. with the help of underlying microservices and subsystems providing these functionalities. If one persists these state transitions throughout all the microservices and subsystems, then essentially they will have all the data points needed to recreate the state of the experience platform at a given point in time.
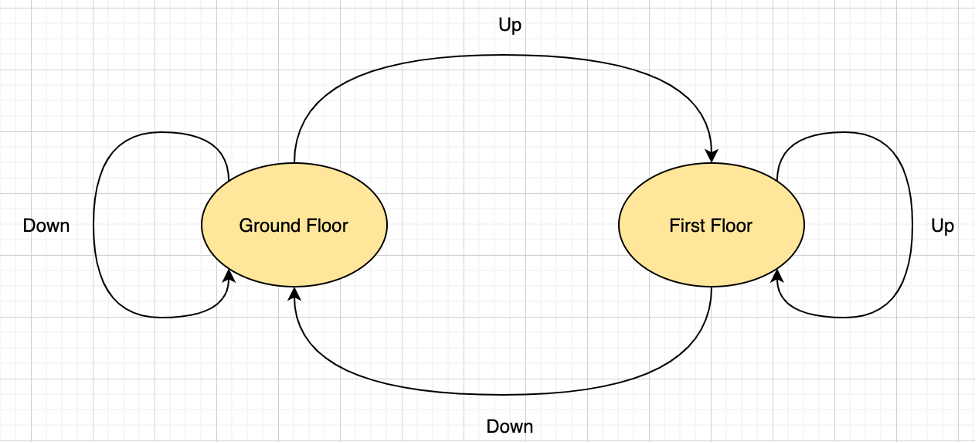
Figure1
Figure1 demonstrates this with an example of a simple elevator system. Same state transitions can be defined in tabular form below. Persisting these state transitions with the time dimension would allow us to figure out the state of the elevator system at any point in time.
|
Current State |
Action |
Next State |
|---|---|---|
|
Ground Floor |
Up |
First Floor |
|
Ground Floor |
Down |
Ground Floor |
|
First Floor |
Up |
First Floor |
|
First Floor |
Down |
Ground Floor |
2. Passive Temporal Data Snapshot Builder
State persistence might not be possible for every microservice or subsystem in a personalization platform due to legacy, engineering, or regulatory challenges. Instead we can passively read from these upstream microservices’s logs, internal databases, and streams to build temporal data snapshots. It is important to add the temporal dimension to this data to enable data stitching and time travel capabilities.
- Temporal data stitching - Temporal data snapshots from all upstream microservices and subsystems can be stitched or linked based on approximate time-window based matching to provide an approximate state of all services/systems at a given point in time.
- Offline simulation environment - Temporal datasets with stitching functionalities enable a powerful offline simulation environment. Programmatic APIs to read such stitched data in Spark or other offline environments (Python, R) helps to standardize model evaluations tools. It enables data scientists to evaluate new algorithms and models at scale, with confidence, which reduces timelines from prototypes to production releases. It also provides a robust alternative to live A/B tests which are limited in scope and come with an exploration cost in production environments.
Building a Wormhole Offline Evaluation Framework
Any personalization machine learning platform broadly takes in datasets such as:
- Customer context - Rich feature dataset of current state of customer.
- Content metadata - Content available for recommendations. Eg, videos, images, messages, web layout, product offerings, etc.
- Feedback data - Actions taken by customers on recommendations. Eg, impressions, clicks, views, likes, purchases, etc.
These datasets come from varied real time microservices and subsystems. The wormhole should work passively to collect data from these systems - persists temporal state of data - to provide time travel capabilities.
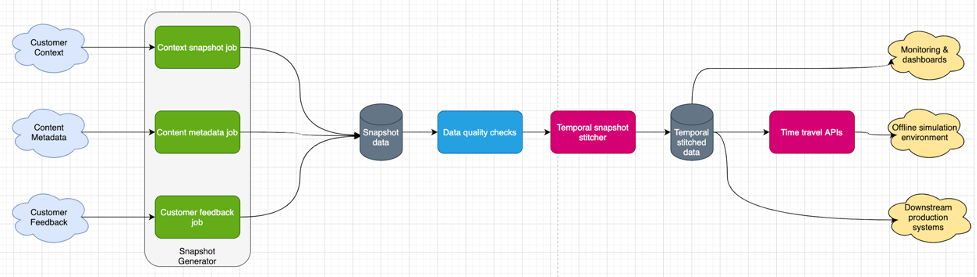
Figure2
Figure2 shows a high level architecture for the wormhole. It consists of:
- Snapshot generator - This component provides extensible and generic snapshot features that connect to microservices’ internal ephemeral storage layers and generates incremental snapshots. It can be extended to generate snapshots using various database connections, caching layers, and streams. It is critical to provide passive data collection (to avoid overloading provider systems) and temporal dimension. To minimize data loss due to failures we use speculative execution. We built a snapshot state tracker to identify any data losses proactively. There are some snapshots with regulatory reasons to obfuscate and encrypt certain sensitive attributes. We reuse internal tools and standards to meet these regulatory requirements. The end goal of this component is to make it easier to add any data sources and build reliable snapshots.
- Data quality checks - Basic data quality checks on snapshots track data issues like missing values and anomalies. This helps provide clean datasets to downstream components. This can be evolved into generic data quality framework to go beyond simple rule based checks similar to [4] and [5].
- Temporal snapshots stitcher - Merges various snapshots with approximate temporal joins. It is a JVM library of spark APIs to stitch various datasets. There are scheduled jobs that build useful stitched datasets. It also enables data scientists to generate custom datasets for ad-hoc analysis from their spark notebooks.
- Time travel functionality - This component provides user facing APIs to build the state of a specific datasource or the collective state of the system, at a given point in time. This can allow one to trace a past customer login and ask for customer context, available content, and feedback data available at that point in time. Essentially, this can recreate the state of data across all subsystems. That’s why we call it a time travel system - a wormhole! Data scientists can use these APIs and debug how recommendation algorithms worked in the past - restore the system data at that point in time - test new algorithms. It provides robust offline evaluation capabilities at scale to iterate over new ideas faster with high confidence.
- Other usage - There are many other usages of this system and available temporal datasets. e.g. exploring new features, monitoring, and valuable insights from production systems.
Enhancements
A functional system that passively generates temporal data from all subsystems and provides time travel capabilities can be incredibly powerful for personalization platforms. By using modular, extensible, and scalable architectures, one can add even more data sources with minimum efforts. However, there are several additional functionalities that one can add, mainly focusing on the offline evaluation framework. A wormhole can leverage distributed computing of Spark, or it can be extended to work in a standalone Python environment on a local machine. This way one can provide out of box support for new algorithm testing with minimal efforts. The goal of any wormhole should be to reduce prototyping to production time by providing quality data and solid infrastructure to explore new algorithms at scale with a high degree of confidence. Enabling this can help lead to a rich personalization platform that helps customers make the right decisions, at the right time.
References and Related Work
[1] YouTube prese https://www.youtube.com/about/press/
[2] Schwartz, Barry. (2015). The Paradox of Choice. 10.1002/9781118996874.ch8.
[3] https://www.featurestore.org/
[4] https://en.wikipedia.org/wiki/Wormhole
[5] https://en.wikipedia.org/wiki/Finite-state_machine
[4] https://databricks.com/session_na20/an-approach-to-data-quality-for-netflix-personalization-systems
[5] Dasu, T. et al. “Data Quality for Temporal Streams.” IEEE Data Eng. Bull. 39 (2016): 78-92.
[6] https://netflixtechblog.com/distributed-time-travel-for-feature-generation-389cccdd3907


