Principles and patterns of a serverless first mindset
Increasing delivery speed and reducing operational overhead
“No server is easier to manage than no server.” — Werner Vogel
In this blog I will be talking about why in the last few years serverless has become a great choice for many engineers looking to develop and deploy production ready code. We will go over how serverless eliminates a bunch of deployment steps and DevOps work along the way, discuss a couple of the most widely used enterprise patterns in serverless, and finally talk about some of the limitations that we need to be aware of when designing serverless applications.
The term ‘serverless’ is a little deceiving as there are servers behind the scenes, but vendors have built an abstraction layer that allows developers to focus purely on application functionality without worrying about maintenance or management of the infrastructure. Also, serverless eliminates the need for application developers to address scalability issues, as this is done automatically by the vendor under the hood.
How we got here —evolution of servers from bare-metal to serverless
Bare metal
Not so long ago, creating a new service involved procuring a physical server, installing the OS, securing the machine, installing and configuring network tools, and finally getting the application code deployed.
Virtual machines
As the demand for scaling increased to improve server utilization, companies started to use virtual machines. This allowed them to reap the benefits of simplifying deployment, automating and scripting the deployment process, improving security across the infrastructure, automating patching, etc. This also eliminated the need to get new hardware and configure it and manage server utilization and scaling effectively.
Containers
Just a few years later Docker came along and changed the way we deploy things forever. Now there was an opportunity to eliminate another step in the process of installing and managing different OS and environment related dependencies. Application development became faster, and it eliminated a bunch of stuff developers needed to worry about including managing OS dependencies and shipping code that works anywhere.
Serverless containers
Cloud providers then provided various container orchestration frameworks as PaaS to deploy production grade containers in a matter of hours. This allowed application developers to build containers and let the container orchestration frameworks deal with underlying container management, application scaling, etc. AWS Fargate is a serverless compute engine for containers that works with both Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Service (EKS). But this still involved creating a docker image with all the dependencies specified.
Serverless functions
Finally came FaaS (Function as a service) where application developers can just focus on the code. In the Serverless model the cloud provider manages the servers, containers, and application stacks allowing developers to focus on the code for the business functionality. Some of the major benefits of serverless functions include:
- Lower operational overhead - Serverless involves lower overhead as it does not require operational tasks to manage servers such as installing and configuring software, managing software updates, patching, managing security updates, server configuration, etc. These are managed by the vendor.
- Automatic scaling - Application can be scaled automatically or by adjusting its capacity through toggling the units of consumption in the configuration provided by the framework.
- Automated resiliency and high availability - Resiliency is also vendor managed. For example, Lambda runs your function in multiple Availability Zones to ensure that it is available to process events in case of a service interruption in a single zone.
- Support for multiple integration patterns - Serverless functions are typically event-driven, hence support various integration patterns. Events can be an HTTP call to your function or a change in your database or a message landing in a queue.
Rethinking how we architect applications for serverless - from microservices to data pipelines
Serverless eliminates a lot of common application architecture problems. It does this by forcing developers to adopt industry standard design patterns and rethink the way applications are designed. When developing applications on serverless it’s more important than ever to follow microservice principles and decouple dependencies. However, serverless makes it easy for developers to more readily design and develop applications following microservices design patterns. This reduces a lot of operational overhead by adhering to some of the 12 Factor App principles that are inherent to adopting serverless frameworks (https://12factor.net/). These principles include:
Config - Store config in the environment
Lambdas have a separate environment variable section where you can configure the key/value pairs that are made available to the Lambda runtime. These configs can include resource handles, credentials, or environment specific values. So by design, Lambdas allow you to separate these from the code and eliminate the need to use any heavy frameworks.
For more information, check out - https://docs.aws.amazon.com/lambda/latest/dg/configuration-envvars.html
Backing services - Treat backing services as attached resources
Lambdas inherently provide clear separation between the code and the resources it accesses through the network. The framework does not allow you to run a dependent service or multiple processes inside the function.
Processes - Execute the app as one or more stateless processes
Lambda functions by design are stateless and ephemeral. This means any application data is stored in the stateful backing service, typically a SQL or a NoSQL store.
Concurrency - Scale out via the process model
This is one of the main benefits of using Lambdas. With Lambdas, scaling comes out of the box as Lambdas are designed to automatically scale to meet the demands of your application.
Concurrency is generally set at an account level ‘AccountLimit’, and they can also be set at an individual Lambda level to allow for provisioned scaling capacity.
For more information, check out - https://docs.aws.amazon.com/lambda/latest/dg/invocation-scaling.html
Disposability - Maximize robustness with fast startup and graceful shutdown
Lambdas are ephemeral, on occasions the container that created the function does not get reused. So when a new Lambda function starts, unless the containers are kept warm, there is some latency with regard to setting up the execution context and bootstrapping. However, when best practices are followed, the startup time itself is very fast and there are multiple techniques that can be used to minimize the cold starts. Below is a link for more information on Lambda cold starts and how to minimize them.
For more information, check out - https://dzone.com/articles/aws-lambda-best-practices
Dev/Prod parity - Keep development, staging, and production as similar as possible
Historically, there have been several gaps between development and production environments. Lambdas, by minimizing the time to deploy, encouraging CICD, and standardizing the underlying stack, have enabled the use of standard contracts across various environments. So, by simply decoupling the code from the environment variables and config, developers can quite easily achieve parity across various environments.
For more information, check out - https://aws.amazon.com/quickstart/architecture/serverless-cicd-for-enterprise/
Common enterprise serverless patterns
Let’s talk about a few of the most common patterns that are highly useful and which cover a wide range of use cases.
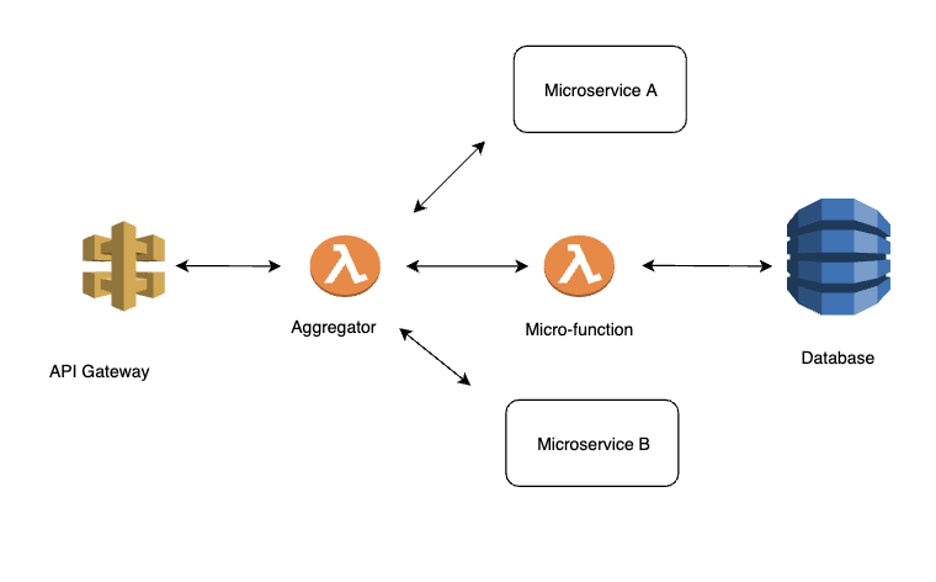
Aggregator pattern
Aggregator pattern is probably the most common pattern in microservices design. A common use case is for a serverless function to call multiple internal/external APIs and/or microservices, aggregate the responses, add some business logic, and return the results to the caller. To optimize the performance, typically asynchronous calls are used for calling the downstream services. The benefit of using this pattern is it allows you to have a thin function to orchestrate the calls and encapsulate the business logic.
Event-driven data pipeline patterns
When we try to model a data pipeline for a complex business process, typically it can involve several steps and states. The main challenge is having a configurable integration pattern that can combine and orchestrate these steps. Leveraging a serverless state machine (AWS Step Functions https://aws.amazon.com/step-functions/ is used below) is a great option to solve this complex problem. Using this approach allows you to build a distributed pipeline that allows you to mix and match the different components required to custom tailor your process needs.

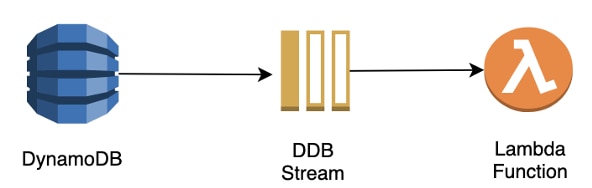
Database event stream to serverless function
Another common pattern is triggering serverless functions from events in the database. For example, you can configure AWS Lambda functions to respond to events from DynamoDB streams. This allows you to trigger functions and business logic when the data in databases changes. The Lambda function can perform any actions you specify, such as notification, or initiating a workflow or a downstream event.
Limitations of serverless applications
While designing and architecting your serverless applications it is really important to understand some of the limitations.
- Colds starts (optimizing managing startups) - This is the time required for the container to startup. This latency can vary a lot depending on various factors including dependencies, SDK, code size, etc. There are various solutions to mitigate cold startups including reducing the code size, increasing the memory, using native binaries like GRAAL/Quarkus, using vendor provided options to keep containers warm, etc.
- Execution time - Typically there are limits around the maximum execution time. For example, a AWS lambda will timeout in 15 minutes. So serverless functions typically do not support long running processes.
- Threshold on maximum memory - There are limits on the maximum memory that can be allocated to the function.
- Code size - There are limits on the maximum package sizes. For example, AWS has a 50MB limit and the unzipped size cannot exceed 250MB including the dependencies.
- Concurrency limits - Vendors have limits for the maximum concurrent executions at an account level.
Wrapping up
In this blog post we have gone through a journey all the way from developing and deploying applications on physical servers to now being able to ship code using serverless functions. We have also covered some of the most common patterns and the best practices and limitations we need to be aware of when designing serverless applications.
Utilizing serverless brings several advantages with it, including automatic scalability, less operational overhead, better resiliency, support for modern design patterns like event-driven architecture, faster time to market, etc. At the same time, there are some downsides to consider including support for a handful of languages, vendor specific implementations, additional network or function calls, and so on.


