Trading snakes for gophers: a migration case study
One Capital One team’s journey converting a platform from Python to Go

vi versus emacs. Monorepo versus polyrepo. Python versus Go? If you’re here looking for a technological holy war, you’ve come to the wrong place. This article is not going to talk about one language being better than another, but rather our team’s journey reshaping a platform and how the decision to change languages mid-flight changed the outcome of the product.
I’m the product owner for a platform at Capital One that’s used for provisioning and management of resources on the public cloud. Over the past year and a half I’ve been working with a team of talented software engineers to rewrite our platform (client + server) from Python to Go. Before starting development, I set out to understand what others thought of the product, both good and bad. The results were pretty clear - users wanted a self-service platform that was reliable, transparent, and supported a range of client architectures.
Capital One encourages autonomy within the developer community, allowing them to make these kinds of decisions based on what is best for their products and platforms. Right from the start, the planning and design for our use case centered around a choice between Python and Go. Both Python and Go are used extensively across the enterprise at Capital One - which you can read about here, here, here, and here. As we were looking to seriously overhaul the platform we wanted to make sure that if we were going to do it, we were going to do it right. In choosing a language, we considered several factors between Python and Go:
- Client portability
- Code reuse/maintenance
- Static compilation
- Public cloud API support
- Developer support
Let’s go into our thoughts on each of these factors and how they impacted our project.
Python vs. Go - Client portability
Developers at Capital One work on a range of operating systems (Windows, Linux, and MacOS) when interacting with our platform. Being able to easily and reliably support all of them is an absolute necessity. To ensure runtime dependencies are met with Python (and avoid source distribution builds, missing linux packages, or required binary extensions), we would really need to ship the client artifacts inside a Docker image. Docker solves this problem, except now you’ve added another layer between your user and your platform - this can create some unintended future challenges if users need to pass in file input, credentials, etc. And yes, there are other ways of achieving portability in Python - please see my next point below. But Go makes building a binary for a particular OS or architecture a breeze - just set your environment variables and go!
Advantage: Go

Python vs. Go - Code reuse/maintenance
One thing I’ve learned in my experience working on the public cloud is that sometimes less is more. What I mean by that is that the simpler solution (with less pieces and parts to maintain) is often more desirable in the long term due to the cognitive load and effort required to maintain a system that has many parts. You can apply this to codebases, infrastructure, and just about any other type of software artifact or configuration that a software development team might be responsible for maintaining. Python makes this a bit more challenging with an array of tools for dependency management, packaging, and installation, while Go includes well-integrated tools in its distribution to do this natively, providing an easy mechanism to import and share code from the ground up with git.
Advantage: Go
Python vs. Go - Static compilation
A better way to phrase this would probably be - when do you want to discover that your application has bugs in it? If you’ve developed software for more than 10 minutes, you’ve already realized that there is no such thing as bug-free software. This topic isn’t new and there’s likely not a shortage of opinions in the tech community as to what the right answer is. You can find good discussions on compiled versus interpreted languages on Stack Overflow, Medium, and Coursera. Static compilation allows us to identify bugs at compile time and produce a binary executable that is portable and fast. Interpreted languages aren’t always able to take advantage of this feature and generally have slower execution times due to the fact that there is a middleman interpreting the language into machine-readable instructions.
Advantage: Go
Python vs. Go - Public cloud API support
Our platform relies heavily on the availability of public cloud APIs. To be successful in this refactor, we needed to choose a language that had both a mature API and robust feature set for interacting with public cloud services. This decision was a little bit tougher, with Python and Go each having well maintained SDKs and APIs for all of the major public cloud providers.
Python:
Go:
Advantage: TIE!

Python vs. Go - Developer support
A bit of a catch-all - we wanted to ensure there was good community support for the language we chose. This included new features going into the language, bugs being fixed, and new software engineers being trained to enter the workforce. Developer support is more of a forward looking metric and is meant to be a general measure of support available for a language. You can find Python at the top of just about every list (here, here, and here) for in-demand programming languages going back for the last several years. It’s general purpose, easy to learn, and runs on all major platforms and operating systems.
Advantage: Python

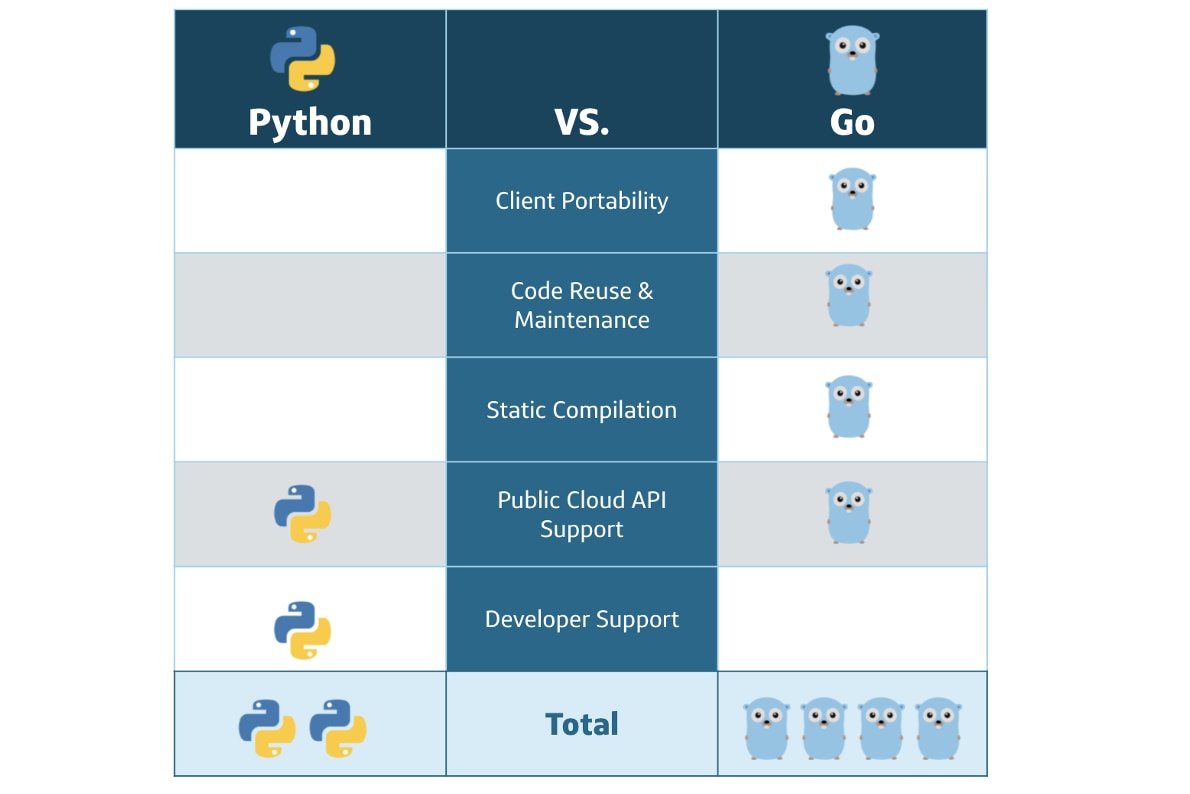
Comparison of our considerations between Python and Go
And the winner for our project was….

Gopher Mascot Generated with Gopherize.me (http:/Gopherize.me__;!!EFVe01R3CjU!IjyWo8esadqQE5IsseqfbP2yWKgMKU8lCZoOhpj0nl-yzB3uhLAv9mB6h-_tcY8113-k$)
Let’s Go!
The factors above really don’t do this comparison justice, but ultimately, we ended up go-ing with Go. Static compilation, cross compilation, and general ease of code reuse were very important factors in our decision. Once the language was selected, the team hit the ground running, focusing initially on the refactor of the command line interface (CLI), to quickly add support for MacOS and Windows clients. This decision provided some breathing room, allowing us to extend support to new customers and allow for some time to think about our design and approach for refactoring the backend.
At this point, the backend was a series of Python functions glued together through a service-based workflow that returned a pass/fail response back to the client based on the original request. We wanted to change this from a hierarchical, sequence-based workflow (implemented through physical services and resources) to a flatter, more discrete set of high level functions that resembled modern day microservices and APIs. As we began the refactor, we started to notice opportunities for eliminating layers of infrastructure and began relying more on the intrinsic features of Go. One by one, we refactored those backend functions from Python to Go, without impacting our customers.
Somewhere in this refactoring process, teams within Capital One began to reach out about potential opportunities for expanding our CLI to support other interfaces, especially ones popular in infrastructure and systems automation. This is really where the light bulbs started to go off. Not only were we seeing a rapid reduction of physical infrastructure and services on the backend, but we were starting to see increased interest on the client side to expand support to new environments and ecosystems. This feedback was exactly what we needed to reaffirm our original decision to move the platform to Go.
We continued down this path for several months, completely finishing the refactor of the backend over the course of nine months. At this point, the team had eliminated a significant amount of infrastructure from its management responsibilities, consolidated and improved code reuse, and increased developer interest and contributions to the platform across the company.
They build it, you own it
Capital One has adopted the model of you build it, you own it (YBYO) to give developers the freedom to innovate and encourage them to make technical decisions that are in the best interest of... the tech. GitHub, O’Reilly, and Salesforce all lay out the benefits of innersourcing and how it can positively impact companies - but, what if you find yourself smack dab in the middle of an innersourcing frenzy? Deciding who owns which component can get confusing faster than those three pull requests that just came in.
To help manage the incoming contributions to the platform, we measured them based on:
- Customer demand
- Overall company value
- Whether or not it increased adoption of the platform
If contributions met any of the criteria above, we would approve them, provided the code changes met basic styling, linting, and continuous integration checks. Contributions which met more than one criteria (and all previously mentioned checks) were merged and put into the release cycle for an upcoming release. The innersourcing model that we chose, while delicate and balanced, provided us the best opportunity to improve the platform and provide value to the company at the same time. There were plenty of contributions that didn’t live up to those expectations - in which case we worked with the requesting teams to modify them or politely decline.
Our platform today
With the refactoring now behind us, the team is focused on expanding functionality within the platform, building out more APIs, and generally making it easier to integrate the platform into Capital One’s CICD pipelines. Even though it’s an aggressive amount of work, we’re Go-ing to continue to measure our success the same way that we measure all contributions - one pull request at a time.
Be on the lookout for future articles from our team detailing our work with Go, APIs, microservices and all things DevOps.



