Popular Myths About Relational & No-SQL Databases Explained
What’s no longer true about relational and No-SQL databases in 2020?

There are plenty of articles on the web comparing the traditional characteristics of relational and No-SQL databases. So I won’t repeat them again here. This article is intended to shed light on the catchup game that relational and No-SQL databases are in; learning and implementing some best practices from one another.
When relational databases were originally designed in the 1970’s, storage was very expensive. So relational databases were built keeping a single machine in mind and were meant to be used for properly structured data that needed ACID compliance enforced. Again, as storage was expensive, the data was normalized into several tables without any room for redundancy.
As more and more companies went digital in the 2000's - growing data collection and storage needs - it became clear that relational databases don’t give the necessary flexibility for unstructured or semi-structured data. They don’t scale well under growing demand and were a single point of failure which impacted the availability. In addition, they had slow performance due to data normalization and the added overhead of object to relational data transformation.
To address these shortcomings, at a time when storage was becoming cheaper, No-SQL databases started coming to the forefront. They provided the flexibility needed for semi-structured or unstructured data by relaxing ACID compliance and following something called BASE compliance. They also provided tremendous scalability for massive data storage needs by distributing the data on several machines. To enable high availability, they followed “eventual consistency” where availability, even with stale data, is favored over consistency with the most up-to-date data.
However, it took a while for No-SQL databases to gain wide adoption. With their relaxed policies around data structure and eventual consistency, a lot of applications that needed structure and strong consistency did not lend themselves to No-SQL databases. It wasn’t easy for someone with a legacy application, built using relational databases, to port them over to No-SQL. Also, added complexity came with the distributed nature of these databases. The learning curve associated with the wide variety of No-SQL databases meant less tech savvy users weren’t able to explore the breadth of this category and the benefits offered.
In the last few years, the momentum behind open source databases has really paved the way for the developer community to think about the best practices offered in each database type and put efforts into overcoming some of the shortcomings. In addition, managed cloud solutions have invested a lot in building services to achieve optimal results for scalability, availability, performance, and security; these have made database maintenance and administration easier.
As a result, some of the criteria that were used to decide when to use relational or a No-SQL database have changed and should be re-verified to see if they still hold true.
Below, I will try to clarify some of the myths associated with relational and No-SQL databases.
Myths About Relational Databases
1. Relational databases don’t offer fast read performance or scale
If you have a read-heavy application, modern relational databases let you set up read replicas with configurations around how the replication would take place (synchronous vs asynchronous). This enables the application’s growing read traffic to get distributed across multiple read replicas through load balancing. The number of read replicas that can be configured varies by the database. Also, scaling compute, memory, and storage have become much easier with managed solutions such as AWS RDS and there is no downtime associated to achieve the scaling.
The message here is to evaluate your specific use case and determine how many read replicas are needed for your application's growing demand and what size will be sufficient. Don’t blindly rule out relational databases assuming they don’t scale at all, because they do for reads.
Note: With asynchronous replication to read replicas, one gets a fast write performance but has to deal with the trade offs associated with eventual read consistency. Synchronous replication would result in immediate consistency but slow down the write performance.
2. Relational databases are not highly available
Availability refers to the data being always made available to applications, whenever needed, despite failure conditions or infrastructure disruptions, etc. Availability is often measured by uptime. You have probably heard of the term RTO (Recovery Time Objective) — i.e how long does it take to restore something in case of a disruption. The lesser the RTO, the higher the availability.
With managed solutions such as AWS RDS, the availability of a relational database has become super high with multi A-Z deployments. In case the primary database goes down, or connectivity to primary fails or the servers/data centers crash, AWS RDS can auto failover to the standby in a different A-Z without the need for applications to make any changes. This process of failover can take up to a couple of minutes (or even less if AWS Aurora is used).
For non-cloud solutions, this might involve setting up a primary replica architecture and using solutions to detect the primary failure and failover to the standby (making it the new primary). This failover process could take a few hours.
The message here is to evaluate if that amount of downtime is acceptable for your use case and to not rule out relational databases without that analysis.
3. Relational databases don’t offer support for a variety of data types and structures
Traditional relational databases only offered support for certain standard data types such as Integer, String, Boolean, Long, etc. However, databases like PostgreSQL are object relational in nature and give you the ability to represent an object like structure in a database. Data need not be normalized in a traditional relational database style, requiring multiple tables with joins to represent that structure. They also support several data types suited for storing geometric, network address, text search, money, and array type data. You can also define your own custom data type as well. With the support for storing data in JSONB format, PostgreSQL provides flexibility for unstructured data and enables faster data retrieval.
Myths About No-SQL Databases
1. No-SQL databases or non-relational databases cannot be used for storing relationships between entities
When someone says No-SQL or non-relational databases, it does not mean they don’t or can’t represent relationships between entities. They definitely do, but it doesn’t need to be in a normalized table/column format. In the below example you can see the contrast on how relationships are expressed in a document hierarchical structure.
Ex: Normalized structure in relational vs hierarchical structure in No-SQL

2. No-SQL databases are not reliable for critical application use cases because they are eventual consistent
Originally, No-SQL databases practiced eventual consistency to offer high availability and to have fast write performance. The tradeoffs involved applications accepting the risk of reading stale data for a while and eventually getting caught up or having data loss.
However, No-SQL databases these days allow you to choose between eventual consistency and strong consistency. You can also configure how many replicas need to acknowledge a transaction before it is committed (commonly called quorum).
Ex: Eventual Consistency in No-SQL databases
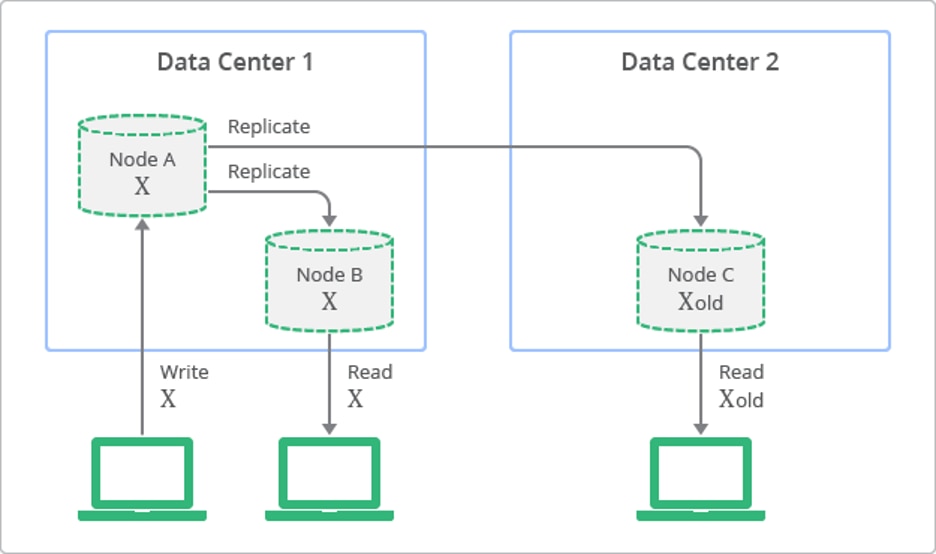
“Conceptual Depiction of Replication with Eventual Consistency” (https://cloud.google.com/datastore/docs/articles/balancing-strong-and-eventual-consistency-with-google-cloud-datastore) by Google Cloud (https://cloud.google.com/) is licensed under CC BY 4.0 (https://creativecommons.org/licenses/by/4.0/)
3. No-SQL databases offer far better performance for all scenarios
It is generally true that No-SQL databases offer superior read performance because they come custom fit for the structure of your data (key-value, graph, documents, etc).
However, there are a couple of nuances.
a. Database Design: Extracting the best performance is heavily dependent on understanding the commonly used applications data access patterns and then designing the database based on those patterns. A bad database design, despite the right choice of No-SQL database, will not yield good results. Also, if you issue ad hoc queries outside of those standard application access patterns to the No-SQL databases, the performance won’t be ideal.
b. Sharding: One of the main benefits of using a No-SQL database is how efficiently it can scale to high traffic loads using a distributed architecture technique called sharding, which is also known as a horizontal scaling mechanism. Instead of the traditional approach of increasing CPU/RAM/Disk space for a server (vertical scaling), sharding stores the data in a distributed fashion across several machines. When the traffic goes up, by increasing the number of shards (the number of machines in the cluster), the database adjusts itself to the load automatically. However, one needs to be aware of possible hotspots that can arise by choosing a wrong shard key. Data can get unevenly distributed among the shards and all the load can heavily concentrate on certain shards, not yielding the best performance.
The message here is using the wrong No-SQL database for your use case or using it incorrectly will not get you positive results. There are specific scenarios for which No-SQL databases offer far better performance, but not for everything.
4. No SQL databases are only to be used for massive data needs
While it is true that NO SQL databases are a great choice when your data is getting continuously generated and you have massive storage needs, one should not rule out No-SQL databases when they have smaller data storage needs. With “pay what you use” pricing models in the cloud, you won’t lose anything by picking No-SQL databases for small data footprints.
5. No SQL means no schema
No SQL databases give you the flexibility to store unstructured or semi-structured data. However, you can still enforce a schema, if you want to, where it is needed. Databases such as MongoDB, which stores data in a JSON format, let you perform validations using JSON Schema. You can configure if you want those validations to result in accepting or rejecting the documents during inserts or updates, and how they apply to existing documents.
****
As you can see, relational and No-SQL databases have come a long way in overcoming some of their shortcomings and have started to learn from each other. While they are still very different and solve different problems, a lot has changed over time. This convergence across database families should force us to rethink our database choices. Let’s not rule out certain databases based on market popularity or historical comparison of traditional traits. Because that information might not be as relevant in 2020 as it once was.



