When to use GraphQL and how it compares to REST
GraphQL as your new BFF (backend for frontend), AWS Appsync, and Apollo Server

The last decade has seen many organizations adopt microservices to power their websites, mobile apps, and desktop applications. Perhaps you’ve seen some of Capital One’s articles on our microservices journey. With all the business logic shifted to the server side in this architectural style, there have been some notable changes and trends, including the philosophy of building APIs once and then reusing them across channels.
Limitations and challenges of directly reusing Web APIs across channels
Reusing the same APIs across multiple channels such as web, mobile, desktop, IoT, etc. can cause some challenges.
In the scenario shown below, clients are tightly coupled with the backend microservices. A lot of the time gets wasted trying to figure out which API to call, integrating to all the backend services, and then coordinating with multiple teams. Also, this increases the complexity on the client side and increases the potential for errors and downtime.
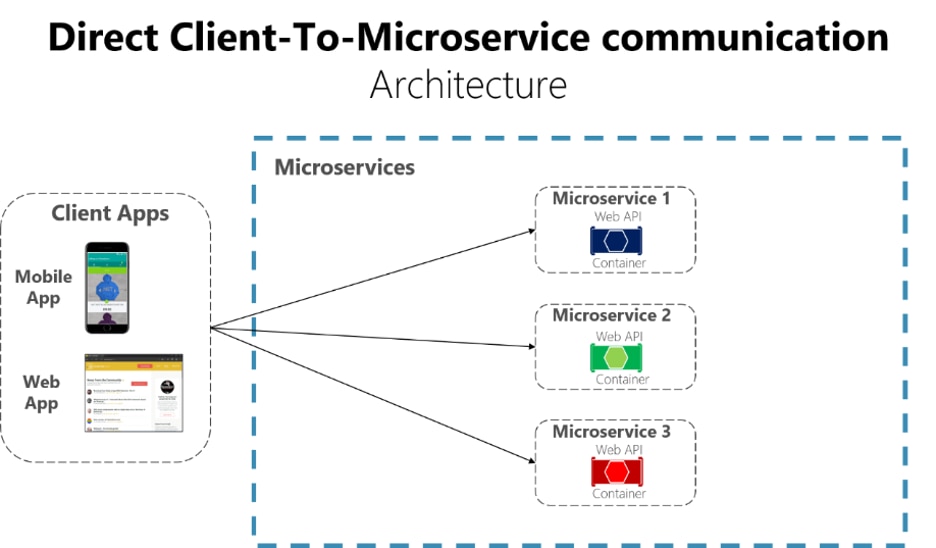
"Direct Client-To-Microservice communication Architecture" from Microsoft .NET Docs (https://docs.microsoft.com/en-us/dotnet/architecture/microservices/architect-microservice-container-applications/direct-client-to-microservice-communication-versus-the-api-gateway-pattern) is licensed under CC BY 4.0 (https://creativecommons.org/licenses/by/4.0/).
Moreso, for channels such as mobile, integrating APIs that were built for the web can cause network bandwidth bottlenecks and memory limitations. This problem is also called overfetching -- i.e fetching a lot more information than what is actually needed for a client.
Additionally, these clients can also experience a second problem due to the distributed nature of the microservice environment where the data that a user needs to see on a single screen can be scattered across multiple microservices. As a result, the mobile app has to integrate with multiple backends and make multiple network calls to fetch the data needed to load a screen. Making this worse, these calls need to be executed sequentially. This can impact performance and slow down screen load time.
The example below shows multiple REST calls that need to be made sequentially to load a specific user’s followers and their feed from an app.
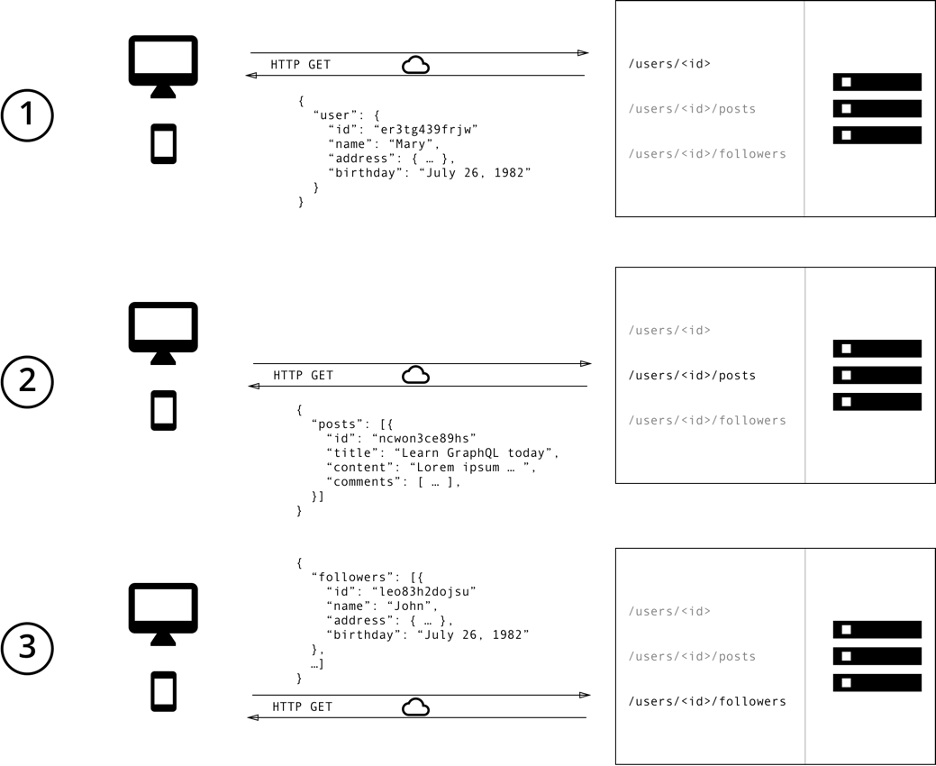
Sequential calls from client apps to backend Microservices from GraphQL is the better REST Copyright Graphcool (https://www.howtographql.com/basics/1-graphql-is-the-better-rest/). Licensed under the MIT license (https://github.com/howtographql/howtographql/blob/master/LICENSE.txt).
Overcoming challenges with Experience APIs and BFFs
To overcome all of the above challenges, some design patterns like Experience APIs or Backends For Frontend (BFF) were adopted.
An API experience layer sits on top of the existing APIs and allows each UI team to optimize the API experience for their specific app or device. A Backend for Frontend (BFF), as the name suggests, is a separate backend for each UI interface which gets optimized for that front end, without worrying about affecting other frontend experiences.
This looks something like the below diagram. The single customized endpoint on the BFF aggregates data from multiple microservices, filters what is needed for the mobile channel, and then returns only the necessary data. This not only reduces the network back and forth between the client and backend, but also provides abstraction.

Multiple Backends for FrontEnd supporting different clients
Now imagine multiple of these BFFs or Experience APIs supporting a single mobile app, including different variations of each that would be needed to maintain multiple apps. It’s a lot, right? A lot of maintenance goes into tweaking and optimizing these for each client, handling fallbacks, circuit breaker implementations, etc. Also, these APIs are subject to constant change if the views on the frontend are altered.
This can also lead to code duplication across the various BFFs. For example, a mobile team might not even be aware that the web team built another BFF for a similar flow. Or, let’s say there is a plan in your organization to integrate your APIs with smart devices like Alexa, or to eventually build an app for an Apple or Samsung Watch. Are you going to build new Experience APIs for them again? Hmm, I wonder if there is a better way to handle multiple clients...
A new alternative - using GraphQL to improve architectures
What is GraphQL?
GraphQL is a query language for APIs and a runtime for executing those queries. It was developed at Facebook in 2012 and made public in 2015. GraphQL has been considered to be an alternative to REST as it was designed to make API development faster and more flexible to handle changing client requirements.

GraphQL supporting multiple clients
What are the benefits of using GraphQL?
GraphQL provides the following benefits:
1. Flexibility to clients - With GraphQL, clients such as mobile can exactly query for information that they need, and the server will respond with only that data. I.E clients dictate what data the server needs to respond with as opposed to the server, thereby avoiding the overfetching problem with REST. Imagine how useful this is for mobile, especially when there is a slow network.
With GraphQL, clients make a single API call to fetch the information they need. This reduces the integration overhead and improves network performance. No more client-side joins or error handling.

GraphQL" from https://graphql.org/ is licensed under CC BY 3.0.
2. Flexibility to API developers - GraphQL saves the effort needed by API developers to build custom endpoints in orchestration layers or experience APIs for all possible query combinations since you can construct different page views on the client using the same endpoint and schema. Also, we can reuse this aggregation logic to support diverse clients that have varied querying needs instead of building separate BFFs per client. This simplifies the orchestration layer that one needs to maintain.
3. Versioning - With GraphQL, it’s easier to know which fields in the API are being used by what clients and which ones are not. API developers can more confidently make changes to the existing APIs with this information. This means you don't need to implement a new version when removing certain unused fields or adding new fields or types. The API can keep growing and clients need not worry as much about upgrading to the latest version. This is a stark difference from REST.
4. Documentation & schema - GraphQL uses a strongly typed schema against which queries are validated. Through GraphQL introspection, one can request the schema and know what queries are supported; this can then be used for automatic generation of documentation. Also, tools like GraphiQL can help you visually explore the graph of data and help one to author and submit a GraphQL query to the server. In REST API’s this documentation has to be explicitly created using Swagger or some other mechanism.
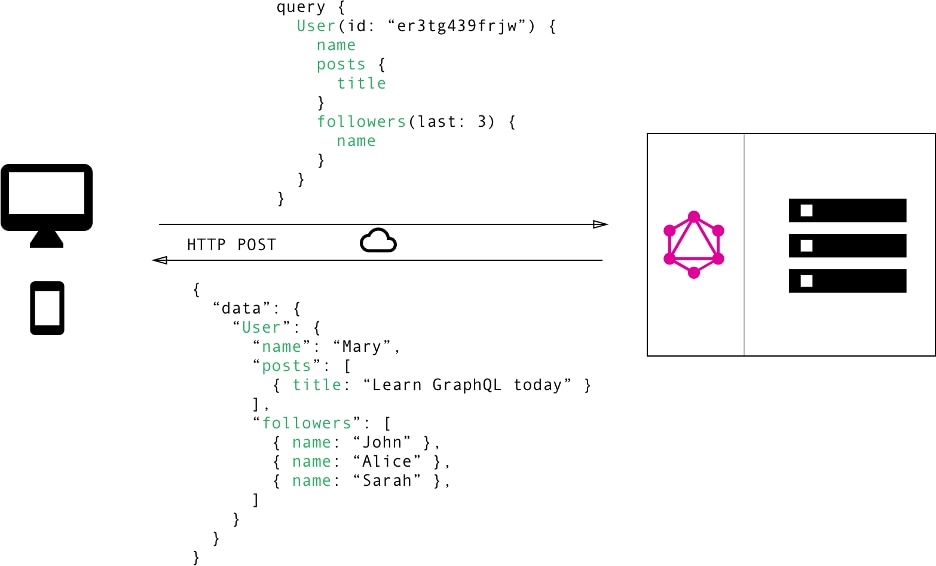
GraphQL query (https://www.howtographql.com/basics/1-graphql-is-the-better-rest/)
You can also specify which fields are nullable in the schema. I.E if there is an error fetching certain fields, the other fields can still be returned in the response.
GraphQL implementation
GraphQL has a rich language support and there are several GraphQL Server implementations available.
Apollo server and GraphQL
Apollo Server is a popular open source implementation of the GraphQL spec. Using the Apollo platform you can build, query, and manage your data graph by connecting to data sources or external APIs.

Apollo Server (https://www.apollographql.com/docs/intro/platform/) from the Apollo Server documentation. Copyright Meteor Development Group, Inc. Licensed under the MIT license (https://github.com/apollographql/apollo/blob/main/LICENSE).
The platform consists of a JavaScript GraphQL server where you can define your schema and resolver functions. It also consists of a JavaScript Apollo client component that can be used with React, Angular, or Vue frameworks. There is also support for iOS and Android client components.
The Apollo client has features that can directly update the UI components when query results arrive or change and declaratively define the queries from the UI components. Here is a good article on why to use Apollo.
AWS AppSync and GraphQL
In 2019 AWS released AWS AppSync which is a fully managed service to build GraphQL APIs. It can combine data from multiple data sources, APIs, and Lambda functions, integrating with caches for faster performance. AppSync manages auto scaling the GraphQL execution engine based on the load. It also has integration with Cloudwatch.
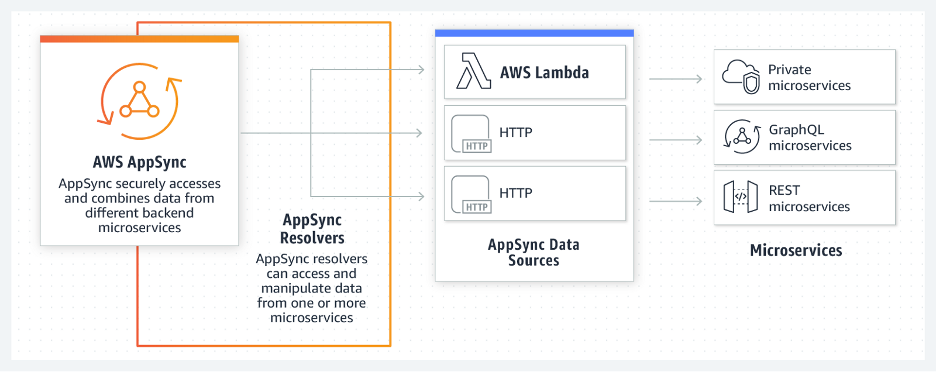
AppSync Resolvers calling backend Microservices as taken from the AWS AppSync documentation (https://aws.amazon.com/appsync/)
You can have Lambda’s as your resolver functions and segregate ownership of these functions to the teams that best know how to fetch the data. These functions can even exist in multiple AWS accounts.
Query execution in GraphQL
The execution of the client supplied query happens on the GraphQL server. The server parses the query, validates it against the schema, and finally passes the execution to resolver functions.
Let's take a look at some of the challenges involved with query execution.
Challenges to Query Execution in GraphQL
1. Safety controls to prevent expensive queries
GraphQL simplifies things for the clients by giving them the control to query for exactly what they want. However, this means the clients can potentially ask for something that is resource intensive by making a lot of database calls on the server.
This is because GraphQL executes a resolver function for each field in the GraphQL schema. Techniques such as setting timeout on queries or analyzing maximum query depth before executing the query or analyzing query complexity beforehand can be used.
Another subtle difference to note with GraphQL is that throttling based on the number of API requests is not a good factor as a single request can result in multiple queries.
2. The resolver functions, batching and performance
Each field in a GraphQL Schema maps to a resolver function which has the business logic for fetching the data. The resolvers can fetch the data by calling another API or from the database or cache etc.GraphQL also has something called default resolvers, so you don’t have to specify a resolver for each field. If there is no resolver for a field specified, GraphQL will look for that field name in the parent resolver.
When compared to REST, the performance costs of using GraphQL aren't as obvious. Even though the clients fetch information using a single API call with GraphQL, API developers still need to be watchful about the possibility of overfetching shifting to the server side by making a lot of backend database calls.
Knowing the intricacies on how to structure your resolvers and where to fetch the data from (parent vs child) is key to performance. Here is an interesting blog that explains how query parsing works and few best practices around GraphQL resolvers.
Conclusion
There are many comparisons of GraphQL vs REST and discussions about GraphQL replacing REST. REST is well proven and GraphQL is fairly new and evolving, its adoption is rapidly growing in many organizations. There is somewhat of a learning curve with GraphQL, like with any other new technology. GraphQL brings along a lot of benefits and some challenges; the solutions to deal with those challenges are effectively being built.
In my view, GraphQL provides a ton of value in scenarios where the clients need flexibility to fetch minimal data in a single shot like Mobile, or where the client needs are changing rapidly and you want to minimize the overhead on the server side. It can also be a huge benefit for building organizational API’s on top of REST where you need to support a diverse set of clients.
However, if you don't have such needs and have simple APIs with static, straightforward querying requirements, GraphQL can add unnecessary complexity compared to REST.
Geometric header photo created by rawpixel.com on www.freepik.com



