9 recommendations to minimize DynamoDB operational costs
Part 3 of 3: An introduction to using and cost optimizing DynamoDB

Amazon DynamoDB is a fully managed NoSQL database service that lets you offload the administrative burdens of operating and scaling a distributed database. In this three-part series, I am going to walk you through the basics of DynamoDB and show you some best practices that could save you some operational expense while using this Amazon service.
This is the third, and the last, part of this series on DynamoDB. To start from the beginning, visit Understanding the basics of using DynamoDB. To read part 2, visit 10 DynamoDB choices that will impact your costs.
In this article we will focus on high level decisions that will yield an optimal operating cost. We will talk about best practices including attribute naming, choosing the right type of instance, and a handful of tips to save on storage space.
9 recommendations to minimize DynamoDB operational costs
1. Prune your tables systemically
Deleting unnecessary items from the operational data store and moving them into your organization’s data warehouse for archival or analytics is a best way to reduce storage cost. Note that DynamoDB does not have DELETE ON CASCADE like most RDBMS do. Therefore, you are responsible for deleting the orphaned items on a multi-relational data model in your datastore model.
2. Think twice before using strongly consistent reads or transactions APIs
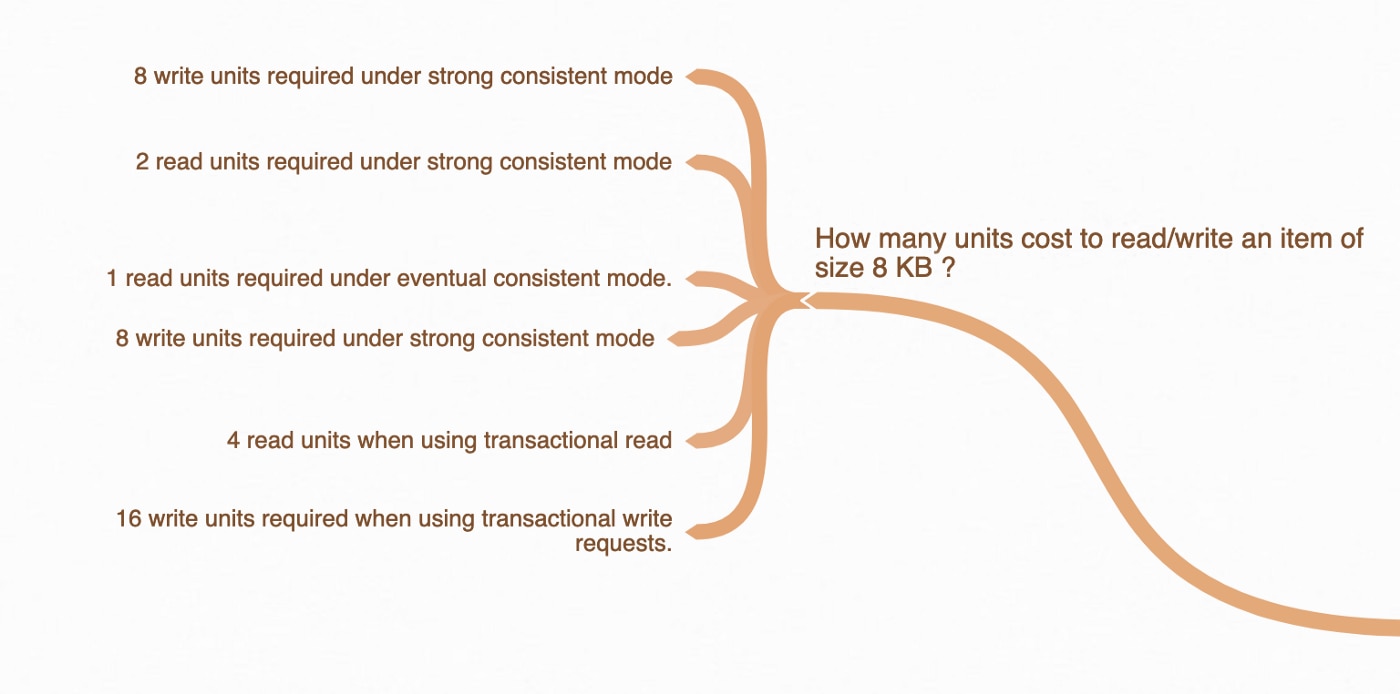
Figure 3: Cost of Reads and Writes in DynamoDB
DynamoDB charges almost twice as much for read units when using strongly consistent reads and twice more than the cost of consistent reads while using Transactional APIs. So, have a strong rationale while using consistent reads or Transaction APIs.
3. Consider using reserved capacities while using provisioned instances
If your capacity is greater than 100 units, consider purchasing reserved capacity. As of this writing, for a three year term, reserved capacity provides a 76% discount, and for a one year term, reserved capacity provides a 53% discount when compared to provisioned throughput capacity. This will provide more savings to your business.
4. Know the difference between scans and queries
DynamoDB has two ways of fetching a set of records: query and scan. While query uses partition and sort keys to retrieve desired data quickly and directly, scan, on the other hand, scans through your whole table.
Having said that, in a query, you are charged only for items which are returned. However, in a scan, you’re being charged for all the rows scanned, not just the items returned.
5. Practice using shorter attribute names
As we saw earlier, every KB read or written impacts the number of read or write units expended while interacting with your DynamoDB tables.
- Shorter attribute names lead to shorter storage cost. Always aim to have a smaller item size wherever possible. While a single read might not mean much in cost, multiplying the size recursively annually with your traffic metric will lead to significant impact.
- Shorter attributes lead to smaller object sizes, therefore smaller read and write units expended while interacting with the data.
6. Be aware of the regional cost
The cost of one read unit or write unit differs from region to region. If your organization doesn’t care about the region used, choose a region where the cost is cheaper. As of the writing of this article, the cheapest regions are generally us-east-1, us-east-2 and us-west-2 costing $0.25 per GB/month, $0.00065 per WCU/hour and $0.00013 per RCU/hour.
7. Be mindful of what you store in DynamoDB
Saving larger objects in DynamoDB can quickly skyrocket costs. It’s inefficient, and you should rather store large objects in S3 and store the S3 URL on DynamoDB. If that’s not an option, consider using compression algorithms and compress the object.
8. When using GSIs, be mindful of attribute projections (and if possible limit GSI usage)
Attribute projections specify which attributes are available when querying for data using Global Secondary Index (GSI). Reducing the amount of data available in GSIs by using Attribute Projection KEYS_ONLY or INCLUDES instead of ALL will reduce the amount of data kept in GSI significantly, thereby lowering not only the costs of storage, but also consuming less read/write units when accessing or updating the data. GSI copies attributes in indices for faster access. This increases cost as seen earlier.
9. Be mindful of on-demand usage
If you are interested in more research, I strongly recommend you to read this blog written by Yan Cui, @theburningmonk. Also, review the Part 1 of this series to understand the use cases for choosing an instance for your workload and ensure you don’t use on-demand without a strong rationale. While on-demand removes scaling configuration out of the decision making process, it comes with a cost. Pat 1 of this blog series explains the subtle change in pricing marks that leads to drastic expense.
Conclusion
Modern cloud services have so many features to help you deliver capabilities sooner and represent a revolution in software development. However, the various pricing tiers can cause confusion when trying to understand the true cost of their use. It is not the sole responsibility of an architecture team to dictate usage based on cost. It should be the responsibility of every engineer to balance operational cost versus value delivered.
I hope this article helped you understand more about DynamoDB, its features and the cost involved behind the scenes. My goal is to help you start making meaningful decisions on behalf of your organization and continue adding value for your customers.



