Deep learning for transfer tabular models
Transfer learning: Machine learning’s new frontier in deep learning.
Many practitioners in the field of machine learning for tabular data still rely heavily on classical machine learning systems, choosing to use gradient-boosted decision trees (GBDT) as the preferred tabular approach. Recent advancements to neural network architectures and training routines for tabular data might change this, as leading methods in tabular deep learning now perform on par with GBDT and can offer distinct advantages—some of which have been proven to outperform GBDT models.
This blog post covers a recent paper on tabular deep learning, Transfer Learning with Deep Tabular Model. It was published in June 2022 and accepted to the premier conference for AI and deep learning, ICLR 2023. The research, done in partnership with Bayan Bruss, Sr. Director, Applied ML Research at Capital One, presents several important insights into deep learning that may change how practitioners approach tabular data in the future. Bayan worked on this research with academics at leading educational institutions, including lead authors Roman Levin and Valeriia Cherepanova, as well as PIs Andrew Gordon Wilson and Tom Goldstein.
Transfer learning experiments in the tabular domain
While transfer learning has been very successful in domains of computer vision and natural language processing (NLP), it is still largely unexplored in the tabular data domain, and the question of how to perform knowledge transfer and leverage upstream data remains open. The authors of the paper prepare to answer this question by leading a study of transfer learning with recent successful deep tabular models. In many tabular domains, we reuse similar features or feature sets across a wide range of related tasks. In the case of this paper, you want to predict two similar disease outcomes, or you might want to predict the disease and length of stay.
In the study, transfer learning experiments are conducted to compare the performance of deep learning models and GBDT implementations in the tabular data domain.
Researchers wanted the study to reflect a setting with real-world use-case and chose a realistic medical diagnosis test bed for their experiments. Working with limited data in tabular format is common in this scenario and presents an opportunity for deep learning. The team selected the MetaMIMIC repository—based on the MIMIC-IV clinical database of anonymized patient data—as their data source.
After confirming the data source, the research team created transfer learning problems by splitting the data into upstream and downstream tasks. Models were pre-trained on the upstream datasets using supervised and self-supervised pre-training strategies. The pre-trained models were then fine-tuned on downstream data with similar features and varying levels of data availability.
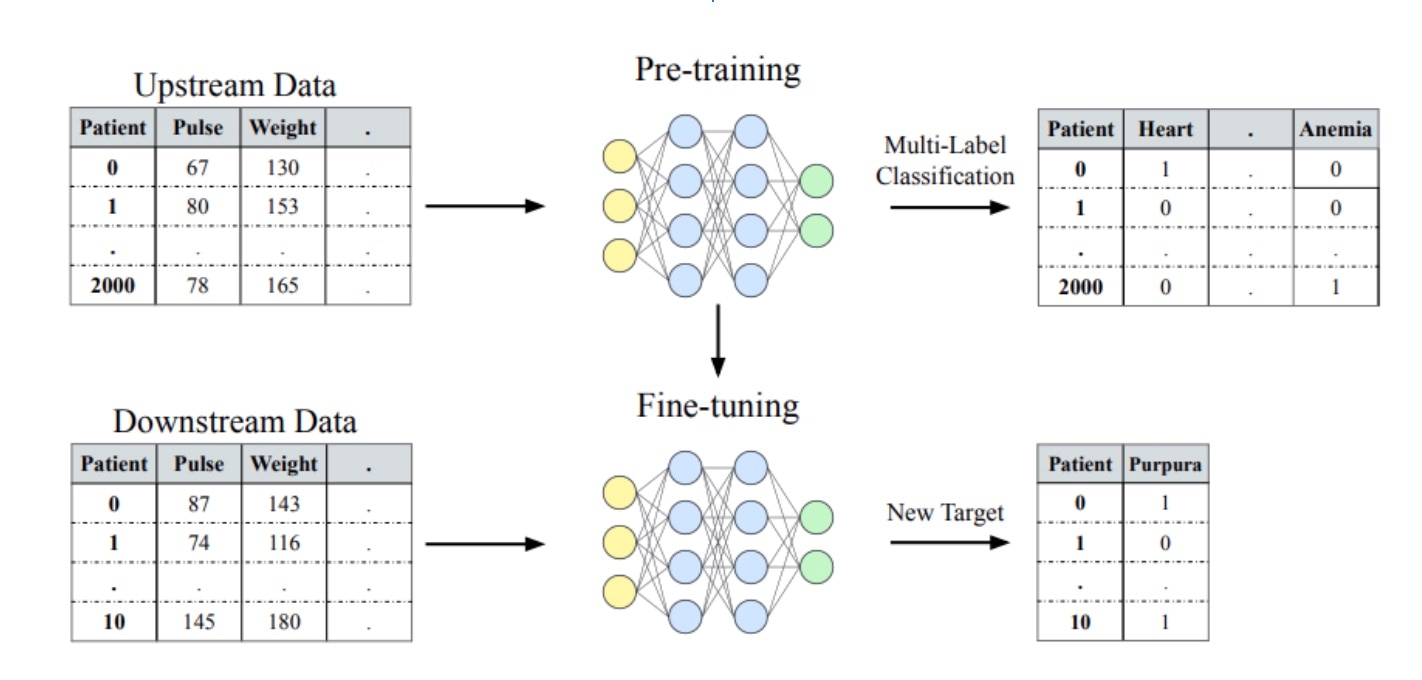
The paper details the results of the study, including a comparison of the performance and average model ranks across downstream and upstream tasks and supervised and self-supervised pre-training strategies.
Tabular models, transfer learning setups and baselines
The four tabular neural networks selected for the study use transformer-based architectures found to be most competitive with GBDT tabular approaches. Two GBDT implementations are chosen for the study that use the popular CatBoost and XGBoost libraries. Stacking, which is when you take the prediction of one model and use it as a feature in another model, was used for GBDT models to build a stronger baseline which leverages upstream data. Stacking is a fairly common way of propagating signals across heterogeneous datasets and tasks.
The following transfer learning setups for neural networks were implemented in the study:
- Linear head atop a frozen feature extractor
- MLP head atop a frozen feature extractor
- End-to-end fine-tuned feature extractor with a linear head
- End-to-end fine-tuned feature extractor with an MLP head
These setups were compared to the following baselines:
- Neural models trained from scratch on downstream data
- CatBoost and XGBoost with and without stacking
Comparing performance across downstream tasks
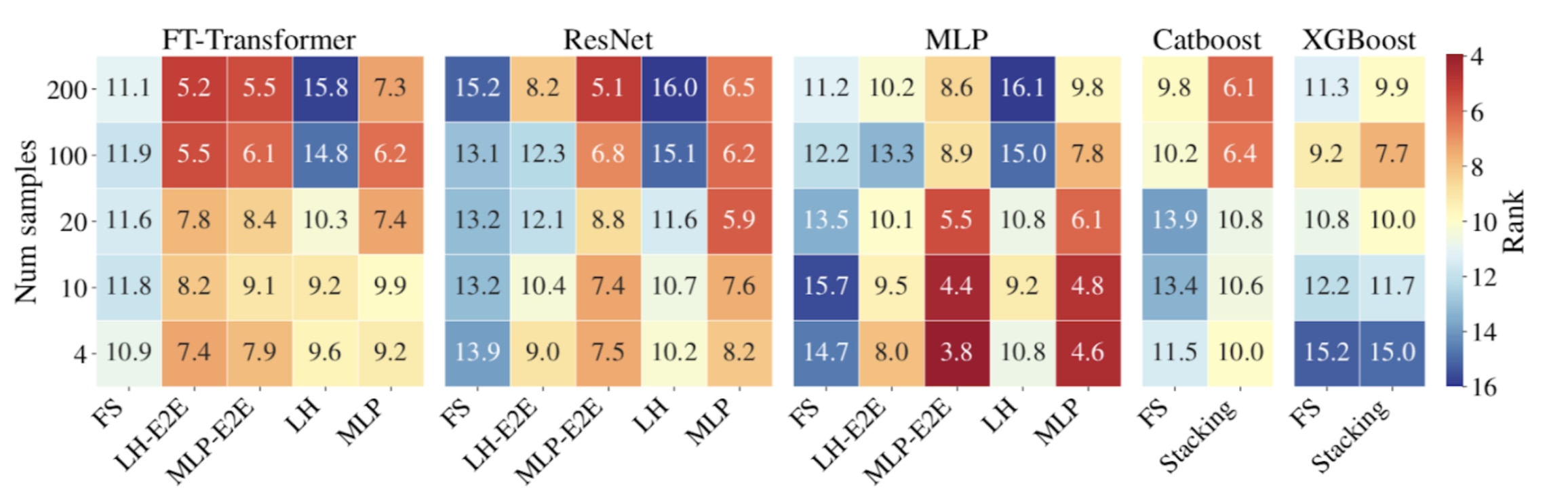
Results show that deep tabular models pre-trained on the upstream data outperformed GBDT at all data levels. The recorded gains are especially pronounced in low data regimes. Simpler models such as MLP with transfer learning are highly competitive in extremely low data regimes, and more complex architectures like FT-Transformer fine-tuned end-to-end demonstrated consistent performance gains over GBDT across all data levels.
Importantly, knowledge transfer with stacking, while providing strong boosts compared to from-scratch GBDT training, still falls behind the deep tabular models with transfer learning. This suggests that representation learning for tabular data is significantly more powerful and allows neural networks to transfer richer information than simple predictions learned on the upstream tasks.
Pre-training methods in the tabular data domain
Researchers compared different pre-training approaches, including supervised pre-training and unsupervised or self-supervised learning (SSL), to assess how the different strategies perform in the tabular domain. The study examines prominent SSL methods such as Masked Language Model (MLM) and the tabular version of contrastive learning, both of which have been proposed for tabular transformer architectures. The experiments were conducted with the FT-Transformer model for this reason.

The table above demonstrates that while self-supervised learning makes for transferable feature extractors in other domains, supervised pre-training is consistently better and significantly more effective than the recent self-supervised pre-training methods designed for tabular data, as these methods always attained the best average rank.
Aligning upstream and downstream feature sets with pseudo-features
Since tabular data is highly heterogeneous, one of the obstacles to transfer learning is the problem of downstream tasks whose formats and features differ from those of upstream data. This happens often with medical diagnosis data.
To solve this challenge, the authors propose a pseudo-feature method which enables transfer learning when upstream and downstream feature sets differ. Their approach uses transfer learning in stages:
First, a model is pre-trained on the upstream data without the feature. Then, the pre-trained model is fine-tuned on downstream data to predict values in the column absent from the upstream data. Finally, after assigning pseudo-values of the feature to the upstream samples, pre-training is repeated and the feature extractor is transferred to the downstream task.
Their approach offers appreciable performance boosts over discarding the missing features and often performs comparably to models pre-trained with the ground truth feature values.
Conclusion
In summary, the study provides several key insights into deep learning for tabular data:
- Pre-training data gives tabular neural networks a distinct advantage over decision tree baselines, which persists even when the XGBoost and CatBoost are allowed to transfer knowledge through stacking and hyperparameter transfer.
- MLP models, which typically perform worse than transformers in the from-scratch setting, often perform better when downstream data is particularly scarce, indicating that practitioners should choose architectures and fine-tuning procedures carefully for tabular transfer learning.
- Knowledge transfer can still be exploited even when there is a mismatch between upstream and downstream feature sets by leveraging pseudo-feature methods.
- Supervised pre-training is significantly more effective than self-supervised alternatives in the tabular domain where SSL methods are not thoroughly explored.
As a result of these findings, practitioners may decide to adopt tabular transfer learning in the future to increase performance, address the challenges of heterogeneous data, and solve for other possible obstacles in the tabular domain.
You can read the research paper and view the code on Github to learn more. You can also read more of Bayan’s published work here.

