DynamoDB Streams Lambda pattern: Best practices
Explore the DynamoDB Streams Lambda sandwich pattern with scaling limits, concurrency challenges and cost trade-offs.
The DynamoDB Streams Lambda sandwich pattern is a new buzzword in my world, where a Lambda function is used to process Change Data Capture (CDC) from a DynamoDB Stream. This pattern represents the next stage of data triggers—evolving from native database triggers to Debezium to DynamoDB Stream and the AWS Database Migration Service (DMS).
My experience with this pattern has presented challenges such as concurrency, scalability, consistency and cost management. While a naive implementation is easy to set up, I will present challenges and pitfalls to consider when implementing this pattern in production.
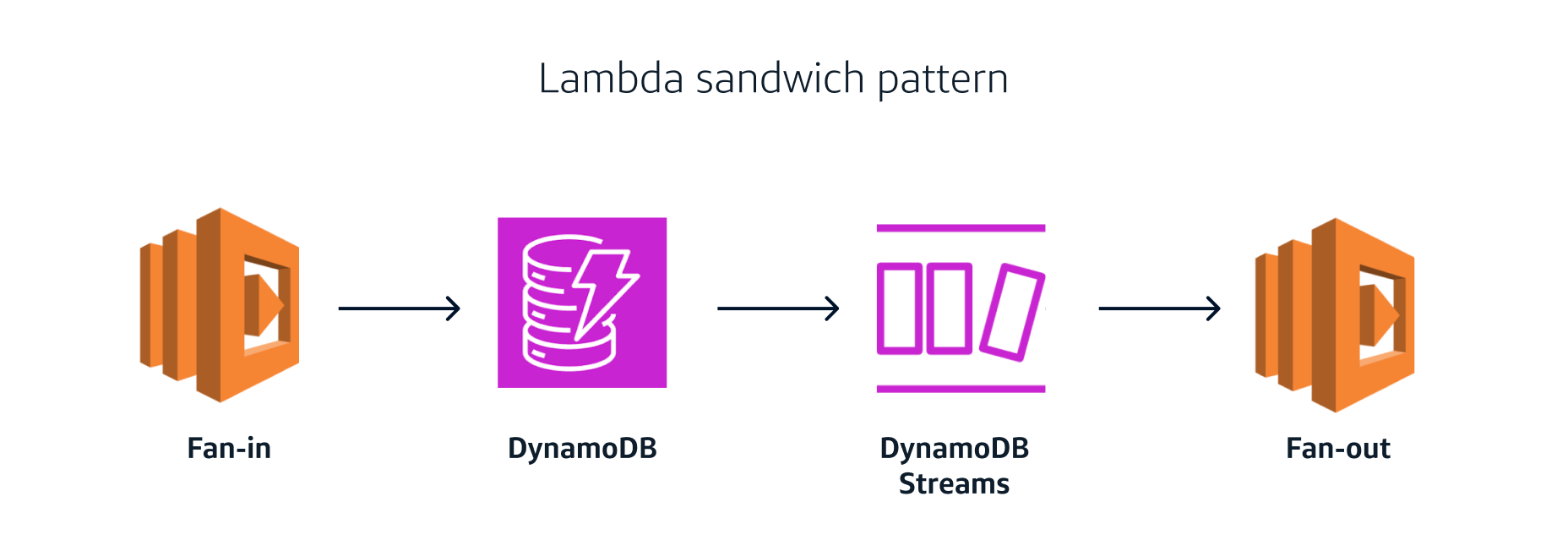
P.S. This article is focused on the challenges of designing and implementing DynamoDB Lambda sandwich pattern, so it understandably requires knowledge of DynamoDB and how its sharding mechanism works.
Lambda concurrency limits in DynamoDB Streams
Each shard in DynamoDB Streams maps to a single Lambda instance, and each Lambda invocation is triggered on a per-shard basis. By default, Lambda polls the stream by up to four times per second.
For high-volume streams, this can result in a large number of concurrent Lambda executions. However, Lambda has concurrency limits at both the function and account levels, and hitting these limits can lead to throttling and delayed processing.
Scaling limits with DynamoDB shard management
DynamoDB Streams provide limited control over sharding and partitioning. They do not dynamically increase the number of shards in response to high traffic. As a result, DynamoDB may end up with “hot” shards that funnel all records through a single Lambda instance—especially with a large table or high write throughput.
This can create a processing bottleneck and add to Lambda’s execution limit. It can also lead to downstream impacts. For instance, dependent services may be forced to wait before acting on business decisions that rely on near-real-time events from hot shards.
Complexity in managing sequential processing
Each shard in a DynamoDB Stream is processed in order, which is essential for maintaining sequential data consistency. Given the scenario with high throughput, Lambda should fan out rather than fulfill an overloaded business process that may choke the application, thereby increasing the latency. Please refer to this well architected article for reference.
Latency in stream processing
DynamoDB Streams are typically processed in near real time but come with a delay as the stream batches records before invoking Lambda. For applications requiring immediate processing, this delay might not meet the requirements.
If consistent, near-instant processing is needed, alternative solutions like Kinesis Data Streams or EventBridge may be necessary. Also consider that there can be a delay of up to several minutes when Lambda event source mapping is created or updated. This may result in data loss. Configuring the stream start position to TRIM_HORIZON can help mitigate this risk.
Dead-letter queues (DLQs)
Errors in processing or connectivity issues can result in failed Lambda executions. While AWS offers DLQs to capture unprocessed records, effectively handling errors without data loss or duplicates requires careful implementation.
By default, Lambda retries up to two more times, which can be problematic if the retry leads to further errors. This could cause a buildup of queued data—potentially a disaster when processing data in a hot shard. Consider offloading the failed data to SQS to triage and make decisions that do not impact the flow of data.
Monitoring
Comprehensive monitoring of Lambda concurrency, iterator age and DynamoDB Streams metrics—such as ReturnedRecordCounts and IteratorAge—using CloudWatch or custom alerts is critical for success and aligns with AWS Lambda architecture best practices.
Cost
Cost optimization is often premature. However, cost efficiency often becomes critical to the platform team after launch. Considering cost to be one of the pillars of trade-offs will clearly call out on target state and cost for the launch.
In this pattern, Lambda concurrency and tables with high write rates significantly drive cost. AWS Lambda Powertuning should be used to determine the amount of resources to allocate to each function.
Fan-out design
DynamoDB Streams only support one active consumer by default, limiting the architecture if multiple services need to consume the same data. In case this is needed, consider using Kinesis Data Streams to capture changes to DynamoDB, which is natively supported.
Another well-architected option is to configure Lambda as a consumer to DynamoDB Streams, then fan in to EventBridge and fan out to multiple consumers.
Event-driven architecture principles have their own advantages and disadvantages; buzzwords should not dictate the usage—use cases should.
Below are a few compiled patterns, based on approach and use case.
| Use Case | Pattern | Latency |
|
Basic transformations, low-to-moderate write volume |
DynamoDB Streams with Lambda | Near real-time |
| High throughput, multiple consumers, low latency | DynamoDB Streams to Kinesis, enables integration with Apache Flink and Amazon Data Firehose. | Low |
| Analytics, data lake/warehouse, non-real-time reporting | AWS DMS | Batch (High) |
| Event-driven applications, routing to multiple targets | DynamoDB Streams to EventBridge via Pipes (not approved yet) to Multiple Targets | Near real-time |
| Multi-regional, high throughput, data persistence |
DynamoDB Streams to Lambda to Kafka (MSK) |
Low |
| Complex event processing, real-time monitoring, CEP | DynamoDB streams to Kinesis to Apache Flink | Low |
| Real-time use cases | DynamoDB Streams to Apache Flink | Low |
Conclusion
DynamoDB Streams Lambda sandwich pattern’s buzz inspired me to analyze the challenges involved in implementing and managing in production. As a result of the learnings, I consolidated a few learnings here.
Every approach has its advantages and drawbacks. Architectural choices should be made based on the business requirements of the application. The choice of a solution should be based on the use case’s functional and nonfunctional requirements—including but not limited to availability, resiliency, consistency, latency, concurrency model and especially cost, which often becomes a consideration only after deployment.

