New visibility and optimizations features for Databricks
Today, we're thrilled to announce new features that just launched for Capital One Slingshot for Databricks! Our ultimate goal is to help users manage and optimize across data platforms, both Snowflake and Databricks.
Slingshot was built by Capital One based on the internal challenges we encountered managing massive data sets at scale. While initially focused on Snowflake, we've now expanded our footprint!
Why Databricks?
Databricks is a critical platform for organizations leveraging big data and AI. As usage grows across the enterprise, so does the challenge of managing and optimizing associated costs. We’ve seen this firsthand as we grew our Databricks usage to +4K users performing 5M job runs to-date.
As organizations scale on Databricks, they tend to struggle with visibility, allocation and optimization of spend, often leading to budget overruns and inefficiencies. Slingshot addresses these challenges head-on by providing a comprehensive suite of cost visualization and analysis, governance and optimization tools designed specifically for Databricks environments. Slingshot customers gain complete visibility and control over their Databricks investment.
In this post, we explore our complete data management solution for Databricks. At a high level, here are the main capabilities:
Automated optimizations of Jobs: ML-powered Databricks Jobs compute optimization you can apply in a click, or fully automate to scale.
Optimization hub offering best practice insights: Eliminate waste and inefficiencies with best practice-based optimizations from the Databricks experts at Capital One. A sample optimization could include: identifying likely over or under-provisioned resources, failing jobs, or forgotten resources, etc.
Visualizations & alerts: Get full visibility into the costs and performance of your Databricks ecosystem, with insights into:
-
Multi-platform cost trends (Snowflake and Databricks)
-
Cost trends by compute type, like Jobs, APC and ML/AI
-
Cost breakdown by custom tags for easy chargebacks
-
Cost insights & alerts to help you address anomalies faster
-
Databricks granular resource reports
Let’s dive into the details below.
Automated optimizations
Autonomous optimization for Databricks Jobs

Our data experts at Capital One joined forces this year with the Sync Computing team to accelerate Slingshot’s support of Databricks. We now offer ML-powered optimization for Databricks Jobs compute. Our advanced ML models auto train on target jobs to offer fully customized optimization based on your job’s unique characteristics. This results in high-impact recommendations for configuration changes you can approve in a click, or fully automate for scale.
Slingshot also surfaces cost and performance trends, opportunities and anomalies across jobs and workspaces. These include:
-
Total job cost by period
-
DBUs vs infrastructure costs
-
Each job’s last run status and last run cost
-
ML-powered insights based on job historical costs and performance
Optimization hub
A combination of best practices and optimizing clusters with advanced ML

Optimizations Hub gives you recommendations to instantly detect inefficiencies and waste based on best practices from the experts at Capital One. These optimizations include:
-
Jobs on APCs: highlight long running jobs scheduled to run on APCs, consider migrating them to jobs compute to lower costs
-
Jobs with low reliability: better allocate resources to improve the success rate of jobs
-
Over-provisioned APCs: identify opportunities to terminate long running clusters, adjust auto-scaling parameters, or consolidate workloads
-
Slow warehouses: find warehouses with high queued overload time to easily adjust warehouse clusters
Multi-platform cost trends
Unified cost visibility across your data ecosystem

Today's data teams rarely operate in a single environment. Most organizations leverage multiple platforms, from Databricks to Snowflake, AWS, Azure and more. This fragmentation can create significant challenges for comprehensive cost management.
Our multi-platform cost trends dashboard addresses this challenge by providing:
-
Unified cost dashboard that aggregates spending across all your data platforms
-
Trend visualization to spot problematic cost growth before it impacts budgets
-
Cross-platform allocation tracking to understand how costs are distributed across business units
-
Cost breakdowns to understand how much you are paying for DBUs vs. cloud infrastructure costs
By consolidating data costs across platforms, you gain unified visibility into your overall data infrastructure spending. This helps identify where Databricks fits into your broader data ecosystem. It also enables better informed decisions about resource allocation and platform selection for specific workloads.
Slingshot’s cost trends feature lets you answer questions like "How do our Databricks costs compare to our Snowflake costs?" or "Which platform delivers the best price-performance for specific workload types?"
Databricks cost trends
Track and analyze your Databricks investment over time

Understanding how your Databricks costs evolve over time is essential for budgeting, forecasting and identifying optimization opportunities. Our Databricks cost trends dashboard provides:
-
Historical cost analysis with customizable time periods, from daily to yearly views
-
Trend identification to spot unusual patterns or concerning growth trajectories
-
Granular breakdown of Databricks costs by workspace, compute type, usage category and custom tags
Cost alerts
Proactive notifications for cost management

Surprise costs are among the most frustrating aspects of managing data in the cloud. Our cost alerts detect these surprises through proactive notifications when costs have increased compared to historical trends.
Several preconfigured alerts are available out-of-the-box that are sent to either tenant admin roles, platform admin roles or both.
Databricks cost details and insights
Drill down into the specifics of every Databricks object
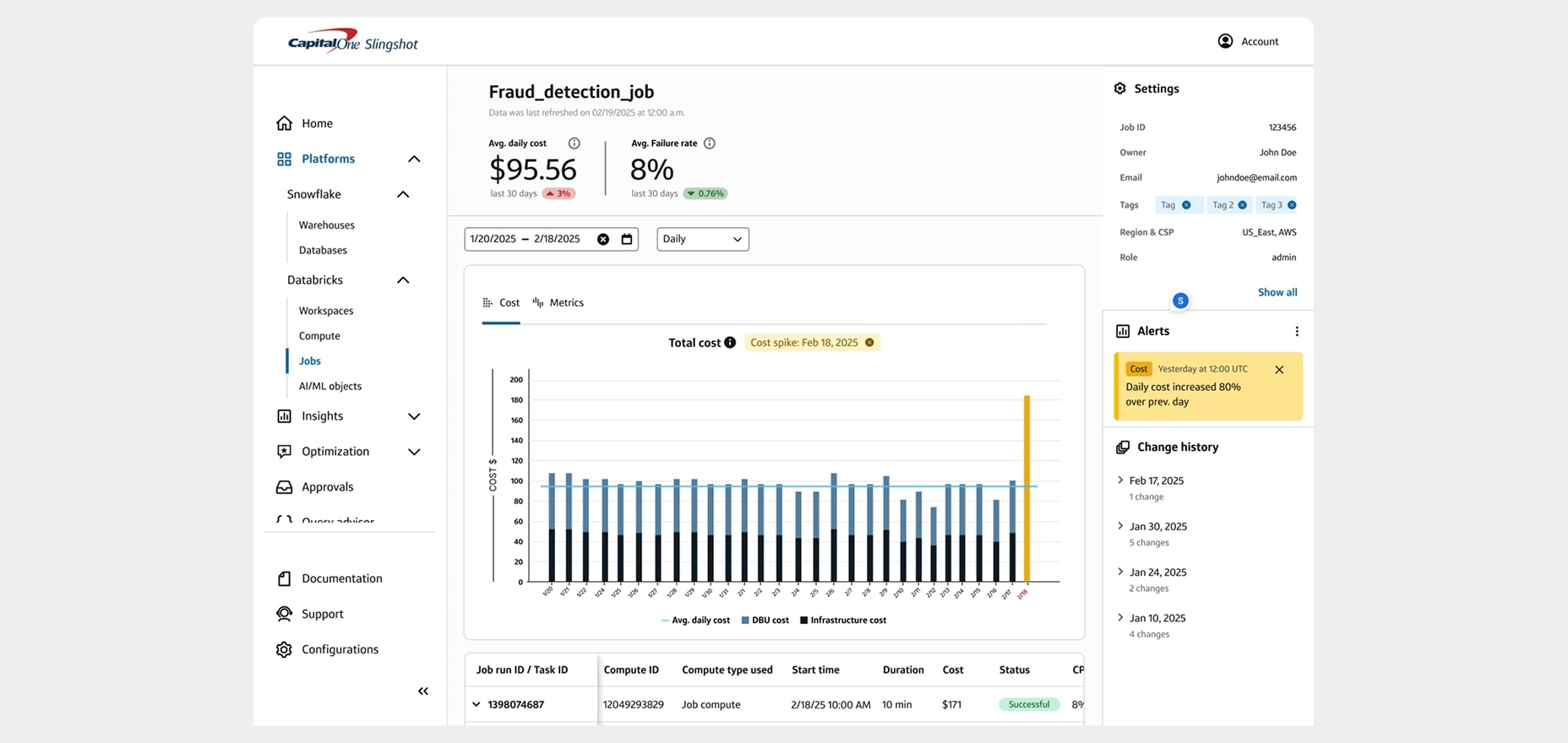
While high-level trends provide valuable context, true cost optimization requires granular visibility into individual Databricks objects. Our cost details and insights feature delivers:
-
Object-level cost attribution for workspaces and compute resources
-
Performance metrics correlation to understand the relationship between costs and utilization
-
Configuration change tracking to identify how changes impact costs over time
This deep visibility enables your team to identify which specific Databricks objects are driving your costs and which may be underutilized or inefficient. By combining cost data with performance metrics, you can make informed decisions about optimization priorities.
The change history tracking is particularly valuable for understanding how configuration adjustments impact costs. This creates a feedback loop that helps teams learn from past decisions and continuously improve their cost efficiency.
These granular insights transform abstract Databricks spending into concrete, actionable cost items that can be addressed individually.
Conclusion
Effective Databricks management requires a comprehensive approach that combines visibility, insights, and recommendations for optimization and automation. Slingshot delivers on all these fronts, providing organizations with the tools they need to understand, control and optimize their Databricks spend.
By adopting Slingshot, organizations can save costs without sacrificing performance. The combination of multi-platform cost visibility across both Databricks and Snowflake, detailed analytics, actionable recommendations and ML-powered optimization offers enterprises the ability to transform how they manage Databricks.
Contact us today to learn more about how Slingshot can help your organization maximize the value of its Databricks investment while keeping costs under control.

