Snowflake cost optimization strategies
Learn how Capital One reduced query time by 43% and projected Snowflake compute costs by 27%.
At Snowflake Summit we shared our insights on Capital One’s experience using Snowflake. A common challenge that companies face when scaling in the cloud is cost optimization, and Capital One is no different. In one of our sessions, we discussed how Capital One optimized cloud costs by saving 27 percent* on projected Snowflake costs.
The flexibility of Snowflake helps companies like Capital One unlock access to its data with performance that can scale infinitely and instantly for any workload. However, this can also create a unique challenge for large organizations with thousands of users. When lines of business manage their own computing requests and configuration, it can lead to unexpected costs.
Strategies we used to optimize our Snowflake costs
Capital One unleashed great power by adopting Snowflake, but you know what they say—with great power comes great responsibility. With a new usage-based pricing model, we didn’t want to find ourselves in a place where we couldn’t predict or understand our costs. To prevent this, we made three strategic moves:
- Federated our data infrastructure management to our lines of business and empowered them to manage their data platform
- Provided insights to help our lines of business identify inefficiencies, and make changes and adjustments themselves
- Provided tools to help our lines of business better understand and forecast their costs, as well as optimize their usage
Here’s what we learned…
1. Federating our data infrastructure
Capital One’s move to the public cloud required us to entirely re-architect our data environment, including our adoption of Snowflake. As part of this journey, we made a decision to federate data infrastructure management to our lines of business. This approach removed the bottleneck we previously encountered with a central team managing our data infrastructure. This enabled us to move rapidly through the rest of our cloud and data journey.
With Snowflake as our data platform, this decision allowed us to scale big time. We currently have about 50 petabytes of data on the platform, being accessed by about 6,000 analysts. We are running three to four million queries a day and our business teams have onboarded over 450 new use cases since we transitioned to Snowflake.
However, this ability to scale presented some challenges. We understood that this new scale increased our chances of having out of control costs, or not understanding where our costs were coming from.
2. Identifying our inefficiencies
Our previous on-prem environment was a world of fixed costs. We had predictable costs that were easy to forecast. With Snowflake, pricing and cost are based on actual usage, which means there are potentially large cost implications if you don’t manage your data with a proper cost optimization strategy.
With more data coming from more sources, we wanted to empower our lines of business to manage their own data platform. We started by identifying some inefficiencies we could improve, some of which may be impacting other organizations operating in the cloud.
Poorly written queries were costing us money
We were using “select *” on large tables. The best practice in place is to still use “*” from tables, but limit their results. We showed users how to use the preview data functionality in Snowflake.
We were also using single line insert statements—every single row insert would create a file. There is now a best practice in place to use a copy command.
Using the incorrect warehouse size for our workload
We were using large warehouses in lower environments where there was no need for heavy compute. We put policies in place to prevent this.
We also saw that we had a different type of workload in the evenings versus during business hours, so we educated our user base to accommodate for this.
We also had underutilized warehouses. We built functionality to show our lines of business where these underutilized warehouses were and where it made sense to combine workloads.
Lack of configuration when warehouses were active or inactive
We had warehouses “on” even when no queries were running. Snowflake’s default standby time before a warehouse turns off is 15 minutes. After doing some research, we realized that setting this to two minutes served our purpose.
3. Understanding Snowflake costs & optimizing usage
Dynamically tuning warehouses
We wanted to make sure that our user base could have data-backed discussions about what was more important to them—performance or cost.
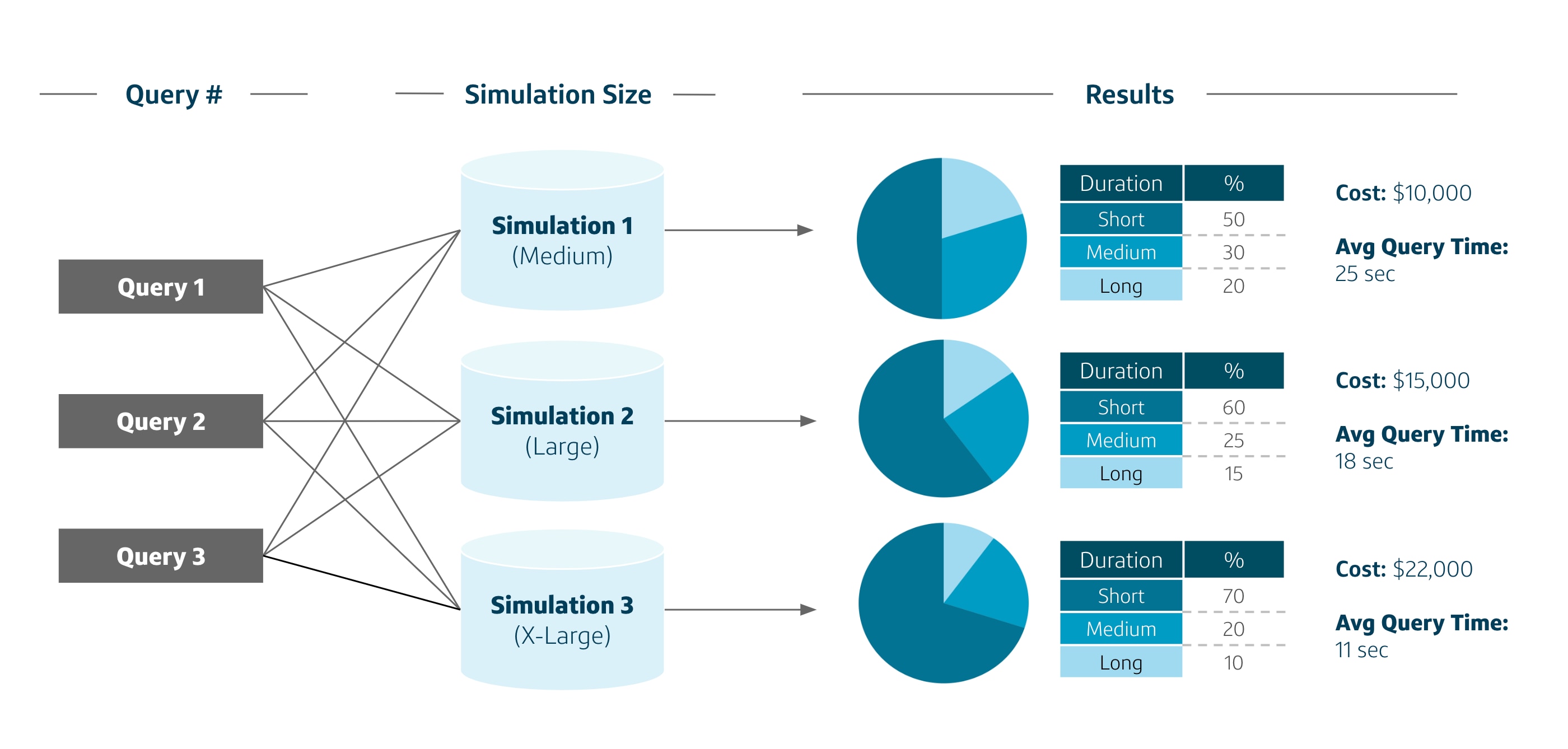
In this example, we took queries that ran in the busiest hours at the same concurrency and ran them through a simulation of varied warehouse sizes. The output gave the users a view of how query run time and cost would move based on warehouse size. Information like this was helpful for data-backed conversations.
Building cost insights dashboards
Once we had put best practices in place for better query writing and choosing the correct warehouse size, we needed to ensure our lines of business had transparency into their costs. We built cost insights dashboards to gain transparency into our costs and understand usage trends.
The dashboards we built allowed users to slice and dice their costs in several ways – month, business organization, warehouse, environment, account and more. The dashboards detected cost spikes, helped with forecasting and allowed them to see exactly how much they were spending and how closely they were trending to what was budgeted.
Putting it all together to reduce Snowflake costs
To best manage Snowflake, we must continually monitor our performance and costs and make adjustments based on these insights. The more we do this, the more we will be able to automate the process to help keep our costs consistent and predictable. For Capital One, this cycle has resulted in a reduced query time of 43% and 27% savings on projected Snowflake costs.*
We learned these lessons from our own cloud and data journey and believe other companies operating in the cloud may face similar challenges, so we built Capital One Slingshot—a data management solution that helps businesses accelerate the adoption of Snowflake’s platform, manage cloud costs and automate critical governance processes.
*This and other figures cited are based on Capital One’s internal usage of Slingshot functionality and are not indicative of future results for your business.


