LLM safety & security: NeurIPS 2024 insights
LLM safety insights from NeurIPS 2024 keynotes and research.
Exploring LLM safety breakthroughs at NeurIPS 2024
Late last year, we showcased our leading AI research at NeurIPS 2024 in Vancouver. As a company committed to responsible and innovative AI, we enjoyed sharing our latest research, connecting with fellow researchers and engaging in the vibrant exchange of ideas that defines this event.
From packed keynote halls to in-depth workshop sessions, one theme resonated: large language model (LLM) security is not optional—it’s a battleground for the future of AI.
The rapid evolution of LLMs ushered in groundbreaking capabilities alongside urgent challenges such as malicious manipulation of input data. As LLMs integrate into critical applications—from automated decision-making to content moderation—researchers are racing to develop robust AI security measures, guardrails and red-teaming strategies that uphold cybersecurity principles and ensure accountability. This proactive approach in AI systems management helps protect sensitive information from unauthorized access, exploiting the vulnerabilities in these systems.
Immersed in the realm of safe and responsible AI, we are excited to share detailed summaries of key research and a categorized table of about 100 must-read papers that are pushing the boundaries of LLM safety, adversarial resilience and synthetic data generation.
Navigating the LLM safety frontier: 100 must-read papers
With so much groundbreaking research presented at NeurIPS 2024, it can be challenging to navigate the vast space of LLM safety, guardrailing, red-teaming and synthetic data generation. To make this easier, we curated a list of about 100 (98, to be more specific!) papers that stood out, each tagged based on its core themes. This table can be found at the end of this blog. The tags are generated with the intention of helping readers to quickly find the research most relevant to their interests. To provide a broader view of where the field is focusing its efforts, the figure below shows how frequently each tag appears across these papers. This gives a high-level snapshot of the most active areas in LLM safety research–whether it’s adversarial robustness, alignment techniques or guardrailing approaches.
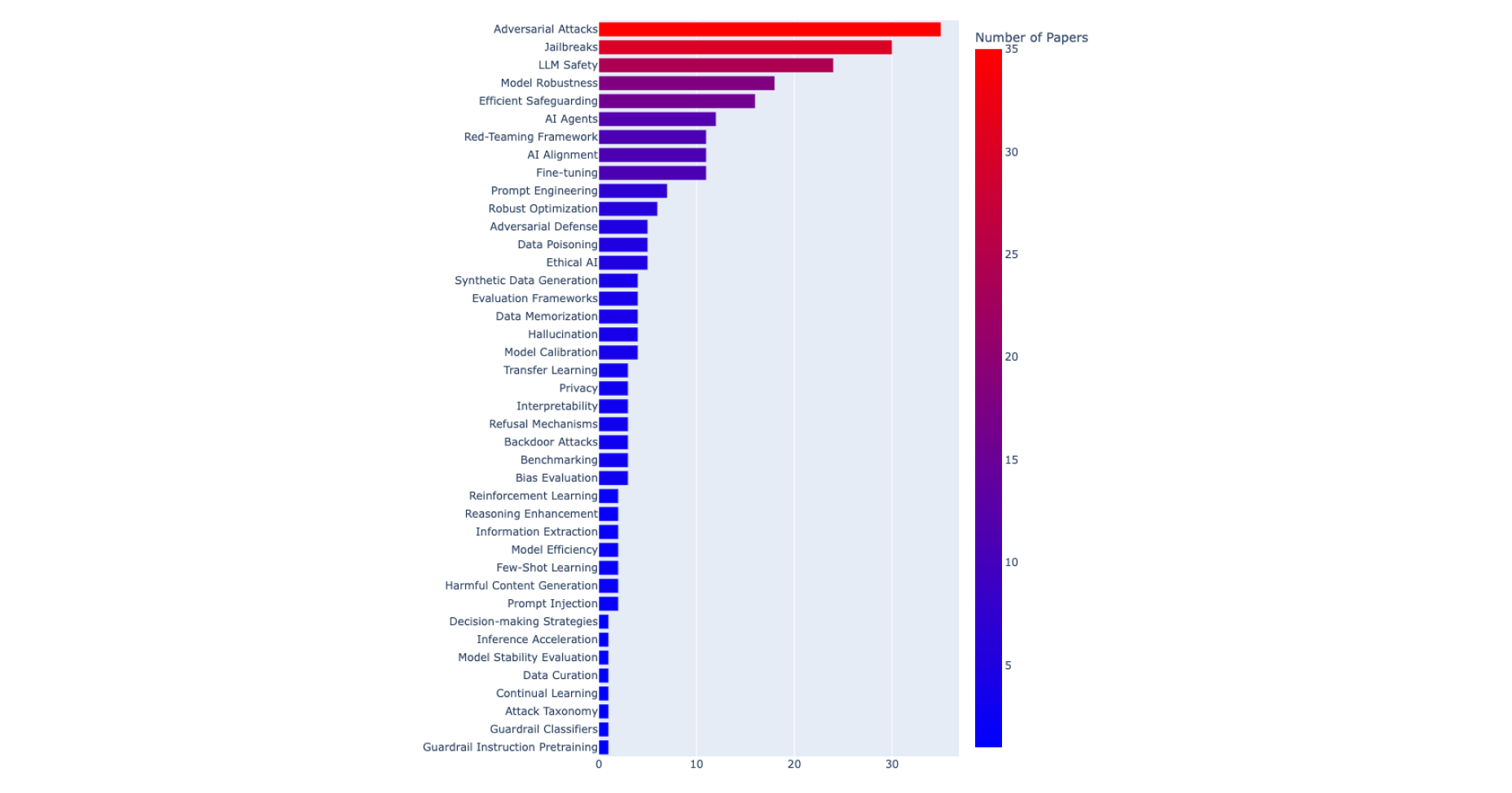
Figure 1. Distribution of tags assigned to the selection of 100 NeurIPS2024 papers in the space of LLM safety and alignment and synthetic data generation.
Research highlights: advancing LLM security and alignment
There are six standout papers from NeurIPS 2024 that offer innovative approaches to enhancing the safety and robustness of LLMs. These studies address critical challenges such as jailbreak attacks, safety alignment and synthetic data generation.
1. BackdoorAlign: mitigating fine-tuning based jailbreak attack with backdoor enhanced safety alignment
BackdoorAlign addresses the vulnerabilities introduced when LLMs are fine-tuned with customized data, focusing on Fine-tuning based Jailbreak (FJAttacks). Fine-tuning LLM APIs (Language-Model-as-a-Service or LMaaS) give malicious users the chance to include jailbreak attacks in the fine-tuning dataset. These attacks incorporate a small number of harmful queries during fine-tuning that can potentially significantly compromise a model’s safety alignment. One simple approach to this problem that has been proven to be ineffective is to integrate safety examples (i.e., harmful questions with safe answers) in the fine-tuning dataset, since a large amount of these examples are required for a meaningful mitigation of jailbreaking attacks.
The authors propose the Backdoor Enhanced Safety Alignment method, which is a novel defense mechanism inspired by backdoor attack methodologies. By integrating a secret prompt (acting as a “backdoor trigger”) into a limited number of safety examples, a strong correlation is established between this prompt and the generation of safe responses. During inference, appending this secret prompt to user inputs ensures the model generates safe responses and thereby mitigates the impact of FJAttacks.
This approach demonstrates that incorporating as few as 11 prefixed safety examples with the secret prompt into the finetuning dataset can recover the model from malicious fine-tuned behaviors to levels comparable with the original aligned models without performance degradation on benign tasks. Thus, this approach allows for efficient mitigation of FJAttacks while preserving the utility of LLMs for customization needs.
2. AutoDefense: multi-agent LLM defense against jailbreak attacks
Addressing the vulnerability of LLMs to jailbreak attacks, this study presents AutoDefense, a response-filtering-based multi-agent framework that operates by assigning various defense roles to LLM agents to collaboratively conduct defense tasks against jailbreak attacks. This division of tasks enhances the overall instruction-following capabilities of the models and allows for the integration of other defense components as tools. This is critical for defense methods to ward off against different types of jailbreaks and be model-agnostic at the same time.

Figure 2. Example of AutoDefense against jailbreak attack. Source: “AutoDefense: multi-agent LLM defense against jailbreak attacks”
Jailbreak attacks can be automatically produced through a set of universal suffixes through greedy and gradient-based search techniques (token-level jailbreak), as well Prompt Automatic Iterative Refinement (PAIR) that leverages LLMs to construct these prompts. Instead of focusing on the prompt, AutoDefense only focuses on the LLM response, rendering the specific attack types irrelevant. The primary focus of this study is competing objectives, that is when jailbreak attacks force the LLM to either choose between instruction-following or not generating content that is harmful.
The key to this method is “task decomposition.” By leveraging a multi-agent defense framework, AutoDefense uses a response-filtering mechanism where multiple LLM agents collaboratively analyze and filter harmful responses. Each agent is assigned a specific role, leading to enhanced overall instruction-following capability of the system. By dividing the defense task into sub-tasks and assigning them to different agents, AutoDefense employs the inherent alignment abilities of LLMs, encouraging divergent thinking and improving content understanding by offering varied perspectives. It also offers adaptability to various sizes and types of open-source LLMs, allowing smaller models to serve as defense against larger models against jailbreak attacks. Extensive experiments demonstrate that AutoDefense improves robustness against various jailbreak attacks while maintaining performance on standard user requests.
3. WILDTEAMING at scale: from in-the-wild jailbreaks to (adversarially) safer language models
This research explores the collection and analysis of in-the-wild jailbreak attempts to understand common vulnerabilities in LLMs. The WildTeaming framework is designed to reveal these behaviors and to curate a public large-scale resource for system safety training for models to defend against both vanilla and adversarial harmful inputs without leading to high false positive rates (i.e. high refusal rates of unharmful queries). The authors developed this automated framework to enhance the safety of LLMs by systematically identifying and mitigating vulnerabilities. This paper emphasizes the importance of large-scale data collection and adversarial testing in creating safer language models capable of withstanding sophisticated jailbreak techniques.
First, by analyzing real-world user-chatbot interactions, the authors identified 5.7K unique clusters of jailbreak tactics, including previously uncovered vulnerabilities in LLMs. This led to the development of WildJailbreak dataset, which is a comprehensive open-source synthetic safety dataset containing 262K prompt-response pairs that can be leveraged for both safety training LLMs and conducting evaluations.
WildTeaming follows a two-staged process to address the first challenge: 1) MINE: mining 105K human-devised jailbreak tactics from in-the-wild (ITW) chatbot interactions in LMSYS-CHAT-1M and (InThe( WILDCHAT), 2) COMPOSE: diversifying mined tactics into adversarial attacks by combining various tactics using open-source LLMs such as Mixtral-8x7B and GPT-4, and refining these attacks through off-topics and low-risk pruning. These data sets form WildJailbreak, to address the second challenge. WildJailbreak contains 262K prompt and response pairs of high-quality synthetic sets of instruction-tuning, and is comprised of four components: 1) Vanilla Harmful queries: these are explicit harmful and unsafe queries across many categories, 2) Vanilla Benign queries: which contain no inherent harmful content but may be similar to vanilla harmful queries in form, 3) Adversarial Harmful Queries: jailbreaking versions of harmful queries generated via WildTeaming, 4) Adversarial Benign queries: also generated by WildTeaming but used to mitigate exaggerated safety behaviors.
Through extensive experiments, the authors show that WildTeam identifies 4.6x more diverse successful adversarial attacks compared to previous methods (e.g. AutoDAN and PAIR). This paper emphasizes the importance of large-scale data collection and adversarial testing in creating safer language models capable of withstanding sophisticated jailbreak techniques.
4. DeepInception: hypnotize large language model to be jailbreaker
DeepInception proposes a novel approach designed to exploit the personification abilities of LLMs to bypass their safety measures. Inspired by the Milgram experiment, which demonstrated individuals’ propensity to follow authority figures even to the extent of causing harm, DeepInception creates virtual nested scenarios that prompt LLMs to generate content they would typically restrict.
The main restriction with the majority of jailbreak and adversarial generation approaches is that they usually leverage direct instructions that are iteratively intercepted by LLMs as their ethical and legal constraints are further bolstered over time. Additionally, a successful jailbreak tactic must be equipped with an in-depth understanding of the overriding procedures which is mainly lacking in the majority of the prevalent tactics.

Figure 3. Illustrations of the jailbreak instructions. The indirect instruction (a) lets LLMs create a single-layer fiction, while the nested instruction (b) induces a multi-layer fiction as an enhancement. Source: “DeepInception: hypnotize large language model to be jailbreaker”
The authors propose a framework to “hypnotize” LLMs into adopting roles or scenarios to bypass their inherent safety protocols, leading to the generation of content that should ideally be prohibited. Unlike previous jailbreak methods that rely on computationally intensive processes, DeepInception offers a more efficient and adaptable solution. By constructing specific prompts that guide the LLM through nested scenarios it circumvents the need for brute-force optimization or extensive computational resources.
The study conducted comprehensive experiments demonstrating that DeepInception achieves competitive jailbreak attack success rates (ASR) compared to existing methods. Notably, it facilitates continuous jailbreaks in subsequent interactions, revealing a critical vulnerability in both open-source and close-source LLMs, including Falcon, Vicuna-v1.5, Llama-2, GPT-3.5 and GPT-4. This study highlights the need for robust defense mechanisms and provides insights into potential vulnerabilities that must be addressed to prevent exploitation of LLMs.
5. GuardFormer: guardrail instruction pretraining for efficient safeGuarding
GuardFormer introduces a novel and efficient pretraining approach for safeguarding LLMs against harmful outputs. The authors highlight the efficiency of proxy guardrailing approaches that, unlike LLM safety alignment, do not result in generalization degradation of the main generation LLMs. Contrary to resource-intensive LLMs, GuardFormer leverages a synthetic data generation pipeline to pretrain a smaller, faster classifier that significantly outperforms SOTA methods, achieving this while requiring only 512MB of storage.
The core innovation of this framework lies in its guardrail-specific instruction pretraining, using synthetic data to train a single model capable of handling multiple safety policies simultaneously, demonstrating superior performance across various public and private benchmarks. The authors showcase GuardFormer’s superior speed, efficiency and generalizability, achieved through this innovative synthetic data approach and a multi-task learning architecture.
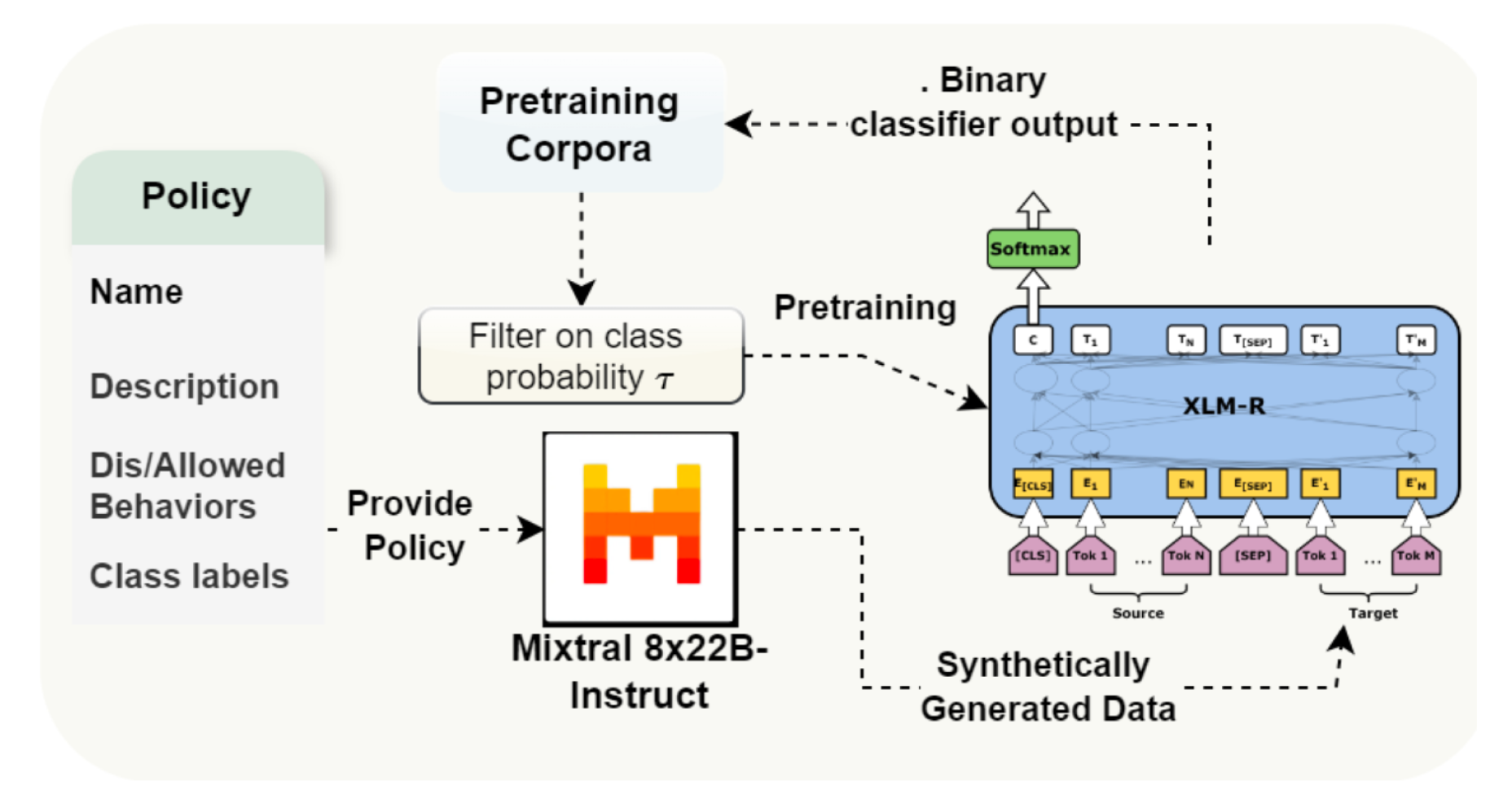
Figure 4. GuardFormer: creating robust guardrails with guardrail-instruction pretraining and guardrail classification using Synthetic Guardrail Data Generation. Source: “GuardFormer: guardrail instruction pretraining for efficient SafeGuarding”
GuardFormer is 14 times faster than GPT-4 and outperforms it by wide margins on public benchmark datasets, as well as on a custom guardrail benchmarking dataset developed by the authors, CustomGuardBenchmark.
This work proposes a synthetic data generation pipeline for both guardrail classifier pretraining to accommodate more generalizable guardrail models, and task- and policy-specific tasks. To improve the quality of data labels, the pipeline also incorporates a self-reflection step that provides an additional check on the LLM’s initial label assignments. GuardFormer leverages a multi-task learning approach, PolicyGuard that leverages the guardrail specific synthetic data in the pretraining phase.
Through comprehensive comparisons with available guardrails, including Nemo, Azure Content Safety, GPT-3.5-Turbo/4/4o OpenAI, PromptGuard and OpenAI’s Content Moderation API, it is shown that this method enhances the model’s safety without compromising its performance on legitimate tasks.
6. AnyPrefer: an automatic framework for preference data synthesis
AnyPrefer is proposed as an automatic and self-evolving framework for generating preference data using a cooperative two-player Markov game between the target and judge models to maximize reward model’s feedback. The ultimate performance of aligned models heavily depends on the quality of preference datasets. Therefore, it is crucial to ensure these datasets satisfy the alignment tuning requirements, but also that the process of generating them is cost- and labor- effective. Current methods for synthesizing these datasets are either expensive and require manual labor (such as human annotations) or do not successfully capture the nuances and preferences of the target model (e.g. leveraging external LLMs).

Figure 5. The AnyPrefer framework. Source: “AnyPrefer: an agentic framework for preference data synthesis”
Once responses are generated by the target model given the input data, the judge model scores these responses using relevant information from the selection of tools at its disposal. Next, an LLM-based reward model is used to further evaluate the preference data quality by producing a reward for each pair. The pairs with higher rewards will be incorporated into the final preference dataset and both target and judge models will be instructed to regenerate the lower-scored pairs informed by their respective rewards.
Using the low-quality scores retrieved from the reward model, the policy of the target model can be updated by optimizing its input prompt to generate higher-quality and more diverse responses. This also requires improving the system prompt for the judge model to better aggregate the information from tools.
The authors introduce leveraging tools in a strategic way based on the input data to augment relevant information to the judge model and dynamically updating them with feedback from the reward model. By using this framework, they generate a high-quality and large-scale (58K) preference pairs dataset, “Anyprefer-V1”, for a wide set of applications. The study showcases the effectiveness of AnyPrefer in improving model alignment and highlights its potential for facilitating safer and more ethical AI deployments.
Full list of recommended papers on LLM safety and security
Below is a full list of recommended papers on LLM safety and security. Each paper is tagged by topic and highlights critical challenges in AI security such as jailbreak attacks, adversarial attacks and synthetic data generation. This curated collection provides insights into best practices and principles for managing security risks and threats and ensuring accountability in AI use and access.
Adversarial attacks
- SuperDeepFool: a new fast and accurate minimal adversarial attack (adversarial attacks, model robustness)
- Query-Based adversarial prompt generation (adversarial attacks, prompt engineering)
- Semantic membership inference attack against large Language Models (adversarial attacks, LLM safety)
- Transferable adversarial attacks on SAM and its downstream models (adversarial attacks, jailbreaks, efficient safeguarding, transfer learning)
- How does LLM compression affect weight exfiltration attacks? (adversarial attacks, privacy)
- On adversarial robustness of language models in transfer learning (AI alignment, adversarial attacks, efficient safeguarding)
- Interpretability of LLM deception: universal motif (interpretability, jailbreaks, adversarial Attacks)
- Poisonedparrot: subtle data poisoning attacks to elicit copyright-infringing content from large language models (data poisoning, LLM safety, fine-tuning)
- Model manipulation attacks enable more rigorous evaluations of LLM capabilities (adversarial attacks, AI alignment)
- Investigating LLM memorization: bridging trojan detection and training data extraction (data memorization, information extraction)
- Stronger universal and transfer attacks by suppressing refusals (adversarial attacks, transfer learning, refusal mechanisms)
Jailbreak attacks
- Jailbreaking Large Language Models Against Moderation Guardrails via Cipher Characters (jailbreaks, adversarial attacks, LLM safety)
- Many-shot jailbreaking (jailbreaks, adversarial attacks, red-teaming framework)
- JailbreakBench: an open robustness benchmark for jailbreaking large language models (jailbreaks, adversarial attacks, model robustness)
- A closer look at system message robustness (jailbreaks, prompt engineering)
- Universal jailbreak backdoors in large language model alignment (backdoor attacks, jailbreaks)
- Mission impossible: a statistical perspective on jailbreaking LLMs (adversarial attacks, jailbreaks, LLM safety)
- Bag of tricks: benchmarking of jailbreak attacks on LLMs (jailbreaks, adversarial sttacks, prompt engineering)
- Efficient LLM jailbreak via adaptive dense-to-sparse constrained optimization (jailbreaks, adversarial attacks)
- When LLM meets DRL: advancing jailbreaking efficiency via DRL-guided search (reinforcement learning, adversarial attacks, jailbreaks)
- Improved few-shot jailbreaking can circumvent aligned language models and their defenses (few-shot learning, adversarial attacks, prompt engineering)
- Tree of attacks: jailbreaking black-box LLMs automatically (attack taxonomy, adversarial attacks, jailbreaks)
- Jailbreaking large language models with symbolic mathematics (LLM safety, harmful content generation, jailbreaks)
- Plentiful jailbreaks with string compositions (adversarial attacks, jailbreaks, efficient safeguarding)
- Zer0-Jack: A memory-efficient gradient-based jailbreaking method for black box multi-modal large Language models (jailbreaks, adversarial attacks, model efficiency)
- What features in prompts jailbreak LLMs? Investigating the mechanisms behind attacks (jailbreaks, prompt engineering)
- A realistic threat model for large language model jailbreaks (efficient safeguarding, adversarial attacks)
- LLM defenses are not robust to multi-turn human jailbreaks yet (model robustness, jailbreaks, adversarial attacks)
Adversarial defense & LLM safety
- BackdoorAlign: mitigating fine-tuning based jailbreak attack with backdoor enhanced safety alignment (model robustness, backdoor attacks, fine-tuning, adversarial defense, jailbreaks)
- AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents (AI agents, prompt injection, model robustness, adversarial defense)
- Agentdojo: a dynamic environment to evaluate prompt injection attacks and defenses for LLM agents (model robustness, jailbreaks, AI agents, adversarial defense)
- Mixture of adversarial LoRAs: boosting robust generalization in meta-tuning (model robustness, adversarial defense)
- Robust prompt optimization for defending language models against jailbreaking attacks (prompt engineering, robust optimization, jailbreaks)
- Fight back against jailbreaking via prompt adversarial tuning (jailbreaks, efficient safeguarding)
- Efficient adversarial training in LLMs with continuous attacks (efficient safeguarding, robust optimization, adversarial attacks)
- Generative adversarial model-based optimization via source critic regularization (robust optimization, efficient safeguarding)
- WilGuard: open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLMs (jailbreaks, LLM safety)
- Testing the limits of jailbreaking defenses with the purple problem (jailbreaks, adversarial attacks, benchmarking)
- Token highlighter: inspecting and mitigating jailbreak prompts for large language models (jailbreaks, interpretability)
- Gradient cuff: detecting jailbreak attacks on large language models by exploring refusal loss landscapes (jailbreaks, Model Robustness)
- Jailbreak defense in a narrow domain: failures of existing methods and improving transcript-based classifiers (efficient safeguarding, jailbreaks, AI alignment)
- Adversarial prompt evaluation: systematic benchmarking of guardrails against prompt input attacks on LLMs (adversarial attacks, benchmarking, LLM safety, evaluation frameworks)
- LLM improvement for jailbreak defense: analysis through the lens of over-refusal (efficient safeguarding, jailbreaks, refusal mechanisms)
- Model pairing using embedding translation for backdoor attack detection on open-set classification tasks (transfer learning, backdoor attacks, LLM safety)
- A formal framework for assessing and mitigating emergent security risks in generative ai models: bridging theory and dynamic risk mitigation (LLM safety, model robustness)
- An adversarial perspective on machine unlearning for AI safety (adversarial attacks, LLM safety)
Red-teaming
- WildTeaming at scale: from in-the-wild jailbreaks to (Adversarially) safer language models (adversarial attacks, jailbreaks, red-teaming framework, synthetic data generation, LLM safety)
- AgentPoison: Red-teaming LLM Agents via poisoning memory or knowledge bases (data poisoning, red-teaming, AI agents, model robustness, adversarial defense)
- AI Red Teaming through the lens of measurement theory (red-teaming framework, evaluation frameworks)
- Imitation guided automated Red Teaming (red-teaming framework, adversarial attacks, AI alignment, AI agents)
- SkewAct: Red Teaming large language models via activation-skewed adversarial prompt optimization (model robustness, LLM safety, adversarial attacks, red-reaming framework)
- Learning diverse attacks on large language models for robust red-teaming and safety tuning (red-teaming framework, fine-tuning, adversarial attacks, model robustness)
- Keep on swimming: real attackers only need partial knowledge of a multi-model system (red-teaming framework, LLM safety)
- Text-diffusion red-teaming of large language models: unveiling harmful behaviors with proximity constraints (red-teaming framework, adversarial attacks, harmful content generation)
- Diverse and effective red teaming with autogenerated rewards and multi-step reinforcement learning (red-teaming framework, efficient safeguarding)
- Attack atlas: a practitioner’s perspective on challenges and pitfalls in red teaming GenAI (red-teaming framework, adversarial attacks, LLM safety)
Explore Capital One's AI efforts and career opportunities
New to tech at Capital One?
-
Learn how we’re delivering value to millions of customers with proprietary AI solutions.
-
See how we're advancing the state-of-the-art research in AI for financial services.
-
Explore AI jobs and join our world-class team in accelerating AI research to change banking for good.


