What is query optimization? Tips to write efficient queries
What is query optimization?
Query optimization is the process of improving the performance of a query by finding the most efficient way to execute a given SQL statement. The goal is to reduce the time and resources required to retrieve the desired data.
Efficient and optimized queries serve as the backbone of data retrieval and analysis. They not only save businesses valuable time and resources, but also ensure accurate and reliable results. When a business understands the impact of query optimization and best practices to improve their efficiency and performance, it supports an effective integrated data management strategy.
Benefits of optimized queries
Optimizing queries for efficient performance can result in real return for businesses, including:
-
Improved performance: Well-written queries can significantly enhance the performance of data warehouses. They help to minimize execution time, reduce resource consumption and improve overall system responsiveness.
-
Scalability: As data volumes grow, the efficiency of queries becomes increasingly critical. Optimized queries scale with the growth of your data, allowing your business to process large datasets without sacrificing performance.
-
Cost savings: In data-intensive environments, inefficient queries can quickly lead to escalating costs. Writing efficient queries results in reduced data transfer, storage and processing expenses.
Tips on how to write efficient and effective queries
At Capital One, our data environment includes thousands of users running millions of queries per day meaning the impact of a few inefficiently written queries can be great. The following best practices have helped improve the effectiveness of our queries, resulting in cost efficiencies for our business. In fact, we saw a 43% decrease in cost per query by reducing inefficient query patterns across our workloads.
1. Educate users on inefficient queries and how to identify them
First and foremost, educating users on inefficient queries is important for avoiding such queries in the first place. We’ve identified some of the most frequent ones below:
-
Single row inserts
-
Select * from a large table
-
Cartesian product joins
-
Deep nested views
-
Spilling to disk
Best practices must be baked into systems to equip users for success. This will help inefficient queries to be identified and fixed before they run and waste compute.
Building a feedback loop is helpful for this, in addition to serving as continuous education for users so they don’t introduce the same inefficiencies in the future. The hope is there would also be a domino effect within the organization with users passing on their knowledge to their teams.
Based on our learnings, we built Capital One Slingshot, a data management solution that helps businesses maximize their Snowflake investment by providing greater transparency into leading cost drivers and opportunities to optimize workloads. Slingshot’s dashboard reveals the most costly users along with a list of the most costly queries to run. This information can be used to hone in on problem queries and remedy them.
Taking this a step further, Query Advisor can proactively examine an organization’s Snowflake queries, identify potential inefficiencies and provide suggestions on how to improve them.
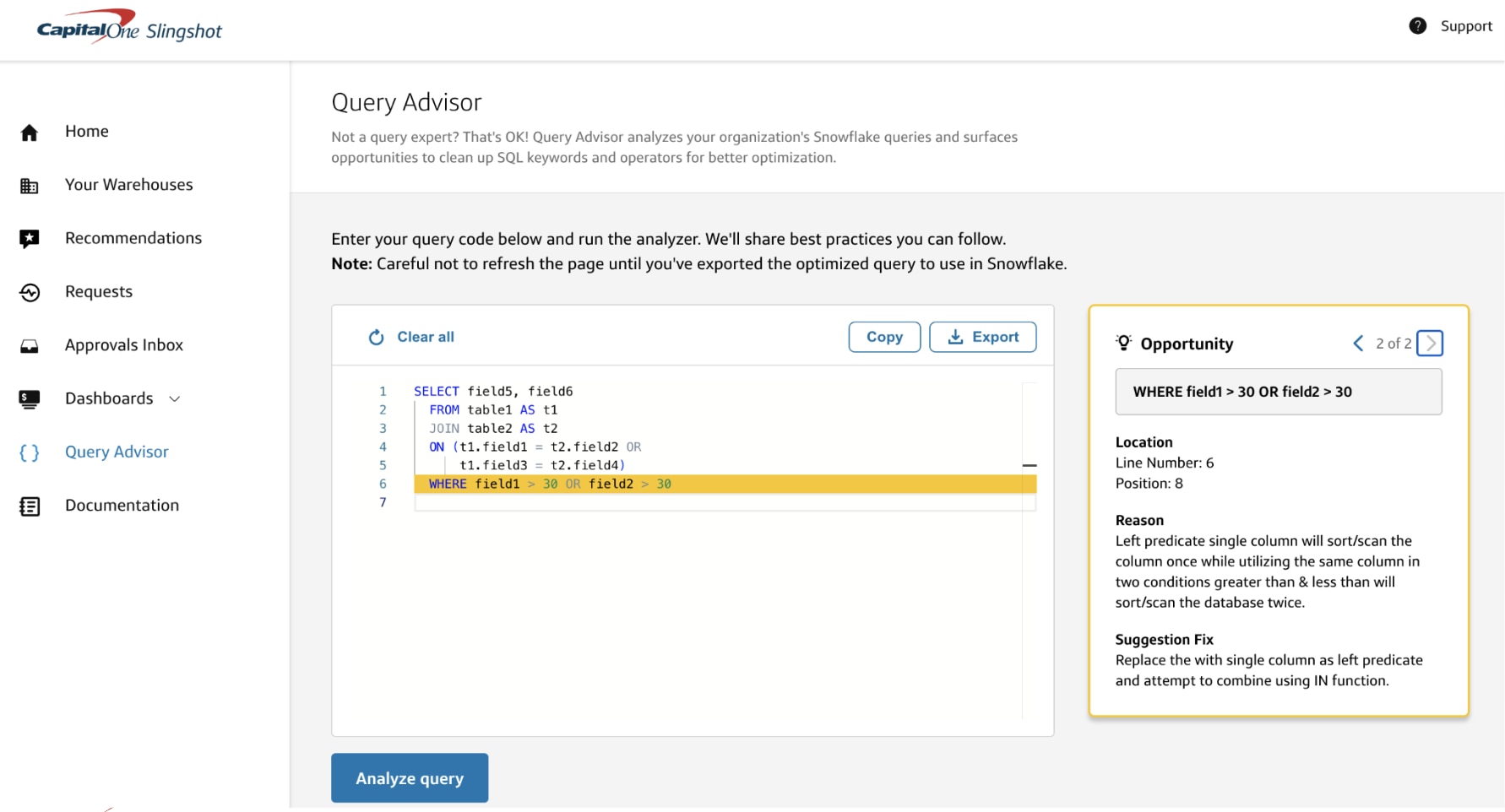
Slingshot’s Query Advisor dashboard can analyze Snowflake queries and identify opportunities
2. Establish an alerting mechanism
You don’t want your monthly bill to tell you that an expensive query cost the company excess money. An alerting mechanism can help you catch queries that should not be running, have run past a certain time, or have timed out (over the weekend, for example). Assuming you know the max query time, setting a query timeout is also helpful to avoid runaway queries. If you don’t know the max query time, as is often the case, an alerting mechanism is a helpful solution. Lastly, alerting mechanisms can help identify when there is a problem with a query so the user avoids running it repeatedly in hopes of success.
3. Reduce data scans
Another important way to optimize queries is in reducing the amount of data scanned. In Snowflake, queries with more bytes to read means longer times and greater costs. A business can improve query performance and reduce bytes by using the right filters in Snowflake to help narrow down the data that will be processed and scanned. Other strategies are avoiding certain types of joins that require large data scans and breaking a large query into multiple pieces.
4. Pay attention to data spillage
Queries that trigger spillage due to warehouse size require quick attention. They are an indication of a bad query that needs to be rewritten or a warehouse that is too small to run the query. A business that continues to run a query in a smaller warehouse will incur greater costs.
When it comes to tuning a query, the below example illustrates two options. Knowing when to choose option A (query tuning) or option B (adjust warehouse sizing) often comes down to the level of effort to tune individual queries and the frequency of the query that is run.
- Option B (adjust warehouse sizing) might be best if a query is only running once or infrequently.
- Option A (query tuning) might be best if it is a costly query and is run frequently.
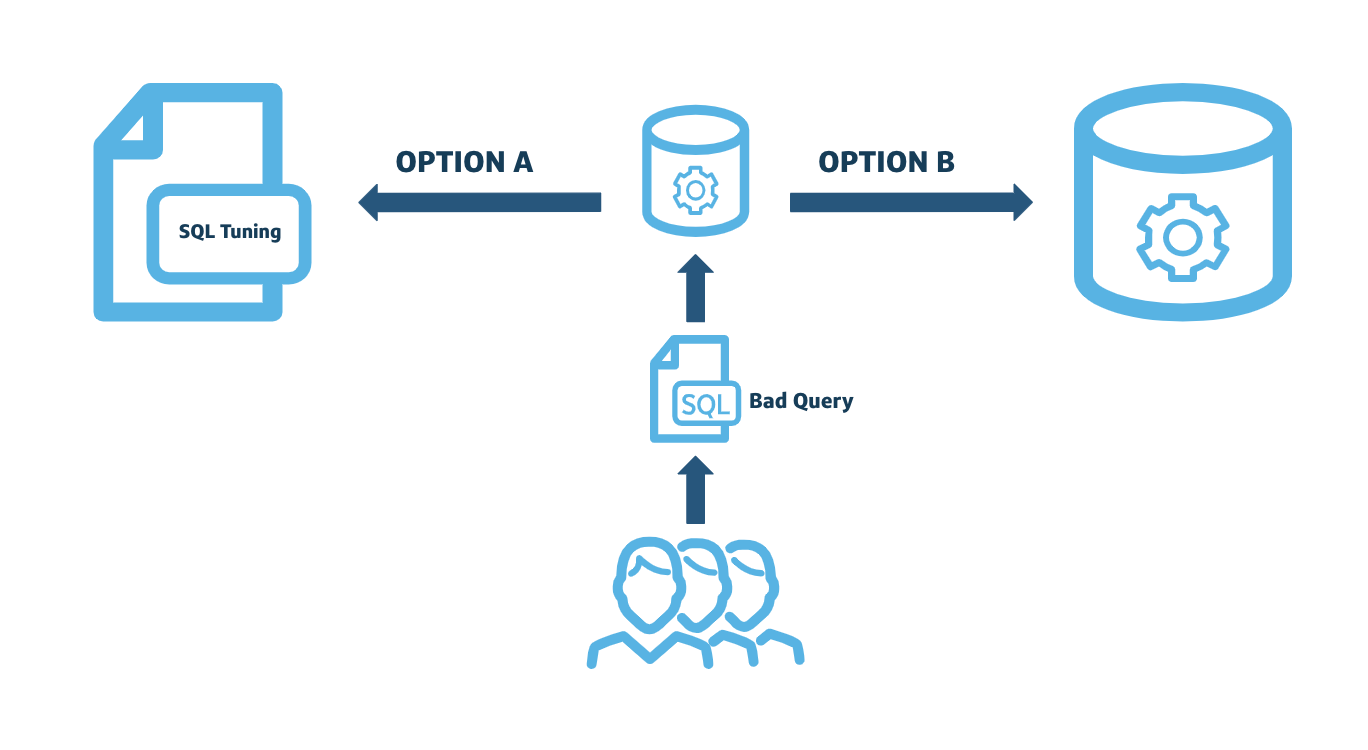
Choosing between query tuning and adjusting warehouse sizing
Optimize queries to operate efficiently in the cloud
As businesses grow and handle greater volumes of data in the cloud, efficient queries become even more crucial to the success and scalability of the company. Optimized queries lead to faster decision making, cost savings and improved system performance.


