Data mesh vs. data fabric: Key differences and use cases

In recent years, a growth in the reliance on data to drive business decisions has led to new demands for real-time data, self-service capabilities and automation. Companies are under pressure to provide quick and easy access to data while adhering to necessary governance and security rules.
Many companies traditionally have depended on data warehouses and data lakes for data storage and analysis. But organizations are realizing their current data architectures don’t meet the growing needs for greater data access and scalability, particularly as workloads move to the cloud.
Data mesh and data fabric are two concepts that have emerged to address the challenges of data management and present solutions to data scalability across an organization. They aim to solve the problem of managing data in an increasingly heterogeneous environment.
Challenges with the traditional approach: Data lakes and data warehouses
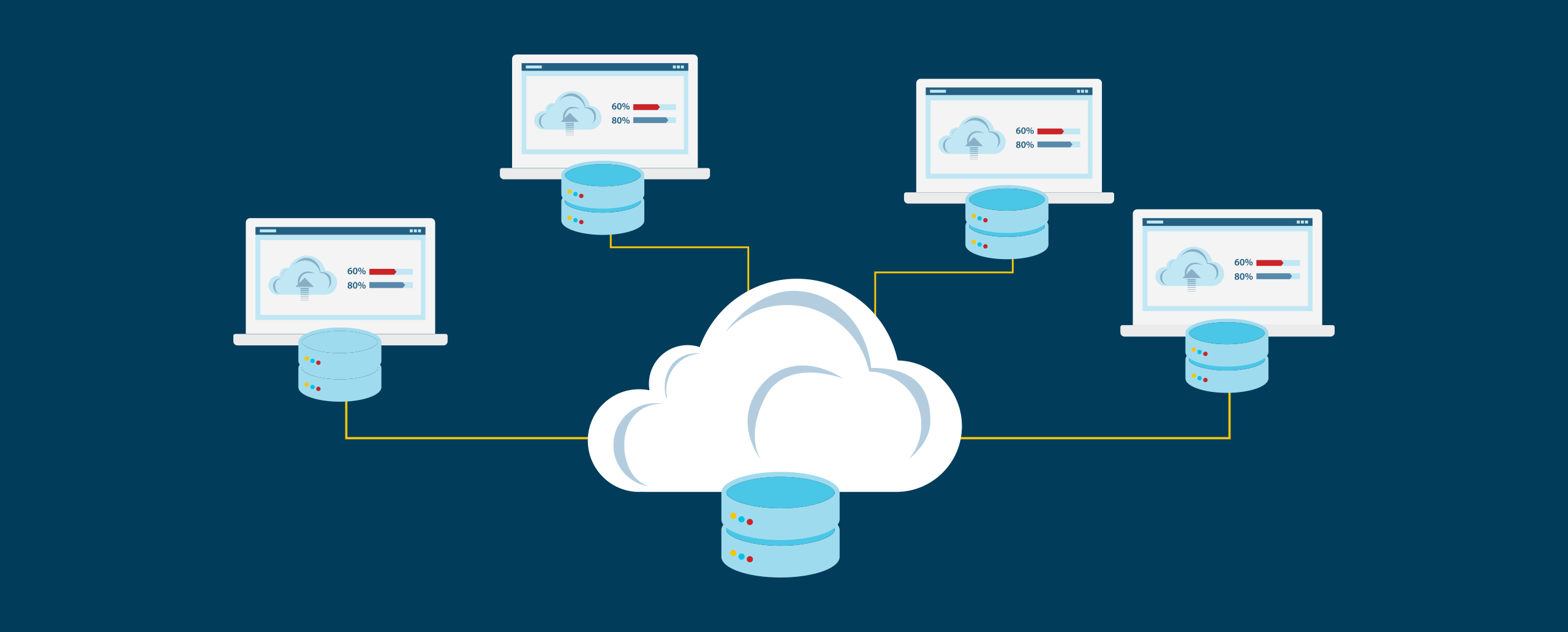
Many data environments employ a data lake and data warehouse. A data lake acts as the single source of truth for storing all kinds of data, after which pipelines load the data downstream into a data warehouse for analysis purposes. The limitations of this approach are becoming clear as data volume and complexity grow, and companies find that centralizing data storage significantly slows down and even limits access to the data. Organizations have dealt with the difficulty of scaling a monolith of data, as they must scale the entire data store to meet the needs of individual services. As volumes of data increase, data scientists and analysts must go through a central ETL pipeline to gain access to datasets for analysis, significantly slowing down the path to gaining value from data. Additionally, the responsibility for managing data falls to a central team with specialized technical skills, which can create bottlenecks as downstream data stakeholders wait for a response.
This is where data mesh and data fabric, approaches to data management that aim to solve the challenges of centralized data stores, come in.
- Data fabric aims to unite disparate data repositories with a common layer through which users can access data management tools.
- Data mesh supports a decentralized approach to data ownership that increases data quality, data accountability and speed to market.
What is data mesh?
Data mesh is an architectural framework for data management that distributes data ownership to the various groups in an organization that are closest to the data. In this federated data management approach, each domain or group takes end-to-end responsibility for its own data from source to pipelines and governance, creating a high-quality data product that the rest of the organization can use. The goal is to enable data usage and analysis at scale by organizing data ownership into decentralized, independent pods.
Data mesh is built on the tenets of treating data as a product, domain-oriented ownership of data, providing a self-serve infrastructure and federated data governance. Data meshes attempt to address the need for easy cross-domain data access, an area in which centralized approaches fail. In these ways, data mesh takes a bottom-up approach to data management that potentially solves the issues with data quality, accountability and access that arise in centralized solutions based on data warehouses and data lakes.
One challenge with data mesh is that it’s a concept at its core that helps organizations scale data efforts by organizing data ownership around domains. Without important guardrails in place, such as central tooling and policy, this approach can exacerbate data silos across the different ownership groups leading to fragmented, duplicate and inconsistent data.
What is a data fabric?
Data fabric seeks to solve similar challenges as data mesh, but approaches the problems from a technology standpoint rather than an organizational one. A data fabric is a solution that provides a unified user experience by pulling together disparate data tools and technologies and making them available in a central location through APIs.
Unlike a traditional data warehouse or data lake, data fabric eliminates the need to move data from its source or storage location. Instead, it uses metadata to connect data across a data environment. This means data fabric allows for the storing and processing of data at the source, giving quick access to data and faster insights for businesses.
Applied in an enterprise, data fabric is the technology that ties an organization’s data platform and governance together. Automation is a key piece of data fabric: what used to be a series of time-consuming manual tasks is completed in the background through automatic processes so that data scientists and analysts gain quick access to the data they need without turning to a technical resource. Built into the solution is adherence to the necessary enterprise-wide governance standards and security rules of an organization.
In the cloud, data fabric can play a pivotal role in connecting data that’s spread across multi-cloud and hybrid cloud environments. About 20% of organizations have adopted multiple clouds, according to Forrester, and this figure is set to double in the next three years. Data fabric can provide the unified view of data that companies are missing today.
The potential downside of data fabric is its heavy dependence on the right technology, which can lead to issues such as vendor lock-in and roadblocks in successful integration between tools.
Data mesh vs. data fabric
Both data mesh and data fabric seek to solve the data management challenges that arise within an increasingly complex and diverse data environment, such as how to manage growing volumes of data at scale in a unified way across an organization. But they offer solutions from different angles.
Key differences
| Data mesh | Data fabric |
| Focuses on the organizational structure of an enterprise | Tackles challenges through a technical implementation |
| Mainly an approach to data management | Mainly a solution for data integration |
| Emphasizes decentralization, namely to disburse data ownership to groups that manage data as they see fit while keeping common governance policies in place | Focuses on centralization through a common data management layer built on top of distributed data |
Both build on the idea of a modern data warehouse by offering a self-service way of accessing and consuming data across different technologies.
Applying data mesh and data fabric
While they are different, data mesh and a data fabric are not mutually exclusive. Many modern data architectures will benefit from having both. Companies can think of data mesh as the architectural concept while data fabric allows you to make it a reality.
At Capital One, we built a data management experience that combines the decentralized architectural approach of data mesh with the centralized, self-service tooling of data fabric. We decided as an organization to go all-in on the cloud and we knew we could no longer rely on a traditional, centralized approach to data management to help us scale data products and analysis in the cloud.
While the majority of metrics and business analyses were always created locally, we further federated data ownership to our lines of business in line with data mesh’s concept. This enabled teams to more efficiently access and exert more influence over the data they consumed and reduced dependencies on a single shared services team. Additionally, federating data responsibilities improved data accountability and access.
However, we found that data mesh doesn't work without centralized tooling that standardizes and enforces your governance. Following many of the principles of data fabric, we built a self-service experience to implement automated enforcement of central policies across our lines of business.
Read more: How Capital One Operationalized Data Mesh on Snowflake
The right data architecture for your business
Data mesh and data fabric will continue to evolve as companies experiment with the best implementations to support flexible, scalable data architectures for their businesses. Each business should design a data architecture that meets their data management needs while remaining flexible to adopt new technologies and approaches in today’s quickly changing and expanding data landscape.