How to boost developer productivity with automated testing
Boost Snowflake developer productivity: Automated testing strategies for data.
Presented at Snowflake Summit 2025 by Kishore Kolanu, Director of Data Engineering at Capital One Software and David Ellis, Senior Lead Data Engineer at Capital One Software
Today’s data systems must handle large volumes of data and complex processing while maintaining a high degree of accuracy and performance for a well-functioning organization. As these data ecosystems grow, proper testing is necessary to get the best performance and reduce errors in faulty stored procedures and inconsistencies with Snowpark models and functions. Without effective testing, issues can persist and grow, leading to downstream failures and eroding data trust in the organization. Automated testing can significantly improve developer productivity by catching issues early and reducing time spent on identifying and correcting errors, ultimately improving confidence of functionality and cost in production deployments. In this blog, we explore requirements for effective data testing in Snowflake and a framework for automated testing that can provide organizations with a strategic advantage in their modern data deployments.
The data engineers’ dilemma
While Snowflake is a powerful platform for efficient and scalable data processing and storage, testing is a complex challenge and pain point in data application development. Today’s enterprise data applications typically involve a diverse set of data sources that feed data into a central repository like Snowflake. These upstream data producers can include CSV files, e-commerce platforms, credit card transactions, cloud storage providers like AWS, and enterprise applications such as Salesforce. Data sources feed data into the repository where data is processed in various applications that operate in the central repository. Applications can include Snowpark applications, developer frameworks, custom-built applications natively hosted in Snowflake, model training and stored procedures. Data users like analysts and data scientists and products like dashboards and reports consume the processed data from Snowflake.
Data applications typically involve data flows for various data producers through the ingestion process to consumers. To ensure product quality and customer satisfaction, it is critical to perform large-scale testing of these applications. But these components of a modern data application highlight a major challenge for data engineers: reliable testing requires data that mimic real-world production-like conditions.
But bringing production-ready data to testing environments is difficult and complex. Stored procedures, for example, present obstacles because the business logic is coupled with the database and make separating and testing individual pieces of code difficult. The main factors that make testing data applications challenging include:
-
Disparate sources: Modern data applications depend on a network of unrelated sources that vary in volume, format, cadence and reliability. Even data from the same source can diverge, leading to different outcomes.
-
Statefulness and dependencies: External factors, such as latencies in ingestion and changes in schemas, dictate the performance and outcome of data applications, leading to dependencies. Upstream data or external systems affect data applications, and changes in one object can break a process further downstream.
-
High costs: As data applications scale to serve more use cases, costs soar and inefficiencies multiply.
Production-like test data that simulate real-world conditions is crucial to establishing reliable testing. But the complexity of modern data applications along with performance issues and costs associated with scaling data environments result in significant obstacles. Additionally, much of the testing is manual, which is time consuming and leads to bottlenecks in the software delivery cycle
Software testing principles applied to data applications
Applying software testing practices and principles to data testing offers a solution for mitigating the challenges found in testing data applications. The software application test pyramid is a framework in software development that organizes testing efforts into unit, component and integration testing layers. The approach helps ensure comprehensive, balanced testing with testing efforts organized by granularity. At the base, unit tests focus on a single functionality and are faster and less costly than the middle of the pyramid where component tests check the interaction between different components like APIs and external systems. At the top, integration tests, which are the most resource-intensive and slowest, check the entire application from the point of view of the end user in real-world conditions.
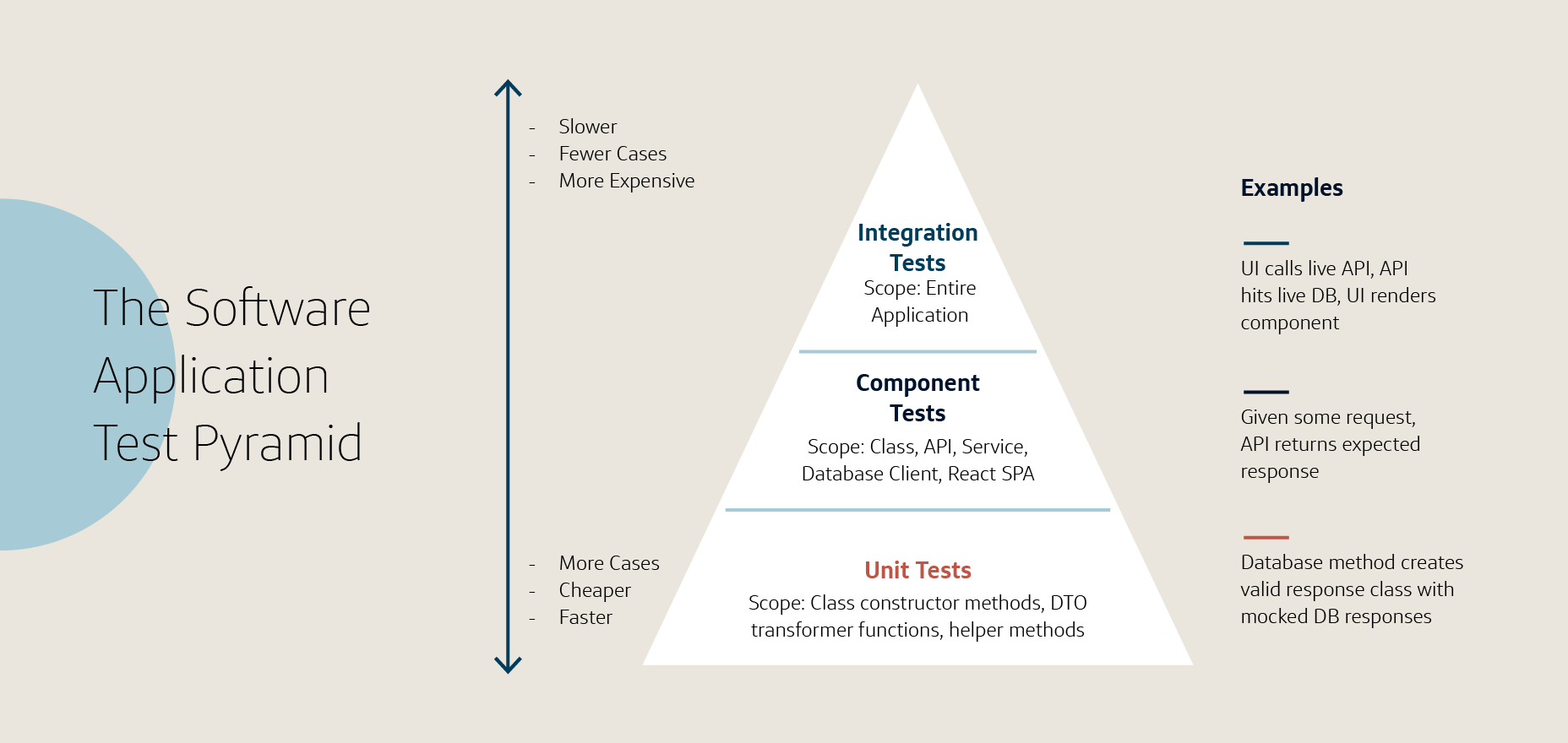
The same principles can apply for a data application test pyramid. Data application testing includes unit testing at a stored procedure level and mocking up data that tests function-level logic without external dependencies. Component testing verifies the proper integration of the stored procedure in tables, ETL stage or visualization. Integration testing covers the entire ETL pipeline. While unit testing in both software and data applications is functionally similar, component and integration testing is uniquely tailored for data applications.

These specialized testing approaches offer ways to solve data testing issues by simulating data sources, varying data volume and latencies, and establishing specific data states. By mocking real production conditions (e.g., source variability) and bringing predictability and control to the test environment, component and integration testing make it possible to reproduce real-life scenarios and manage many of the challenges of testing data applications.
Automating testing with the Slingshot testing framework
At Capital One, we faced many of the challenges we outlined above when developing components on Snowflake for Slingshot, our data management optimization product that helps companies maximize their Snowflake investments. Slingshot engineers created a framework to address these challenges. Slingshot Testing Framework solves the challenges we faced in testing Snowflake objects.
Our goal with the framework was to empower developers with production-like data during the testing phases of the development lifecycle.
To achieve this goal, we would need to meet two critical objectives: 1. Bring production-like data to the test suite and 2. Enable performance validations at test time. As we have covered, data application testing can be difficult because of disparate sources, statefulness and costs, particularly unexpected costs. Success for us looked like solving all three problems with the Slingshot Testing Framework.
A framework overview
At a high level, the framework brings the nuances and scale of production data to the test suite. We achieve this through configuration, or YAML, files that define the resources needed at test time and the constraints. The data generation strategy, defined in the test code or YAML file, allows for mocking different test cases and situations. The Slingshot Testing Framework includes the following steps:
-
Define YAML files: Configuration files define the Snowflake object or resources and its constraints. Resources can be Snowflake tables, views, streams, tasks or any other Snowflake object. YAML files define declaratively what the test data should look like.
-
Expose classes in the test code: Different classes in the test code allow for consuming the YAML file with additional constraints and considerations around what the data should look like. In our example, the definition class reads the YAML file and the SnowflakeTable class implements the interface. The framework exposes an interface that each Snowflake resource class implements. This interface can be implemented by other types like Snowflake streams or table view, creating the instance of that object.
-
Create a data generator with constraints for structures: Using the definition, the data generator creates data as defined by the developer. The generator can also set additional constraints like the number of rows, allowing for varying the scale.
-
Create ephemeral data and destroy it: Then the data is actually created with a resulting table containing data that meets the constraints that were defined. This is temporary and gets deleted by the framework at the end of the test.

Solving for data testing challenges in Snowflake
A deeper look at the Slingshot Testing Framework shows how it resolves the problems associated with testing data applications in Snowflake.
Modeling data through configuration: Solving for disparate sources
Looking at the YAML file, the first thing is to define the object, in this case the table. The attributes of the object are the fields where one can define the field data, or the constraints. A developer can define what data should be in them from a constant attributes perspective. But variable attributes can also be defined, such as a percentage field in which the value will always be between 0 and 100. When defined in this way, the framework creates data randomly within the constraints, allowing for nuances in what the data looks like from different sources and setting the scene for the test. In this way, data sources are mocked and constrained through configuration files that are checked into the SCM (Source Control Management) like using Git.

Creating complex relationships: Solving for statefulness
Relationships and system states can be created through YAML configuration or runtime object attributes. Two YAML files can define different resources and create relationships between the resources. Attributes can also be declared once and reused across multiple objects. As a result, an individual can create virtually any scenario, creating complex relationships and simulating the state of the data at a specific point in time.

Testing for performance: Solving for unwanted costs
Lastly, the framework can be used to assert performance (e.g., runtime) statistics as a part of the testing process to ensure cost thresholds will be met in the deployed environment. A data engineer or developer can run an assertion based on the results that were collected. In this example, we assert the performance expectation runtime in milliseconds is at least 7,000 with an allowance of 10% on either side. This kind of performance assertion is powerful because it guarantees that further down the line, such as six months later, there will be no drift in performance as new enhancements emerge.

The Slingshot testing framework provides an automated approach to testing data applications that is repeatable across Snowflake object types and addresses the major issues against data application testing.
Shift left: Integrating into the CI pipeline

In contrast, the Slingshot Testing Framework seeks to bring data closer to the developer by shifting left. In local development, developers can emulate production-like data environments without dependency on other systems. In pull request reviews, the reviewer can clearly see what the developer expects, for example the expectation to run the test in under 10 seconds based on a certain volume of data. These kinds of tests and their transparency provide everyone confidence in the CI pipeline. They federate confidence in the system that these tests will run every time so something that could break the system will not make it into production. Additionally, because the testing is ephemeral in emulating production data, the costs come down for testing in pre-production and non-production environments. This leads to a reduction in reliance on non-production systems as well as costs.

In the deployed environment, developers can still test costs and conduct performance testing. The performance tests will act as a health monitor in this case, ensuring the production system is still meeting the expectations that were written into the test.
The end result of the Slingshot Testing Framework is to bring data to the developer and increase performance and reduce costs while inspiring greater confidence among all stakeholders in the pipeline.
Moving forward
Difficulties in testing Snowflake objects come from data dependencies, lack of repeatability and manual processes. By using an automated and reusable testing framework and integrating it into a CI pipeline, teams can achieve faster and more thorough testing of Snowflake objects, which in turn lead to improved developer productivity, higher quality code and successful deployments.

