Improving Virtual Card Numbers with Edge Machine Learning
How the Eno browser extension uses ML on device to read the DOM & pixel coordinates for a more accurate VCN experience
By Erik Mueller, Senior Director of Machine Learning Engineering and Senior Distinguished Machine Learning Engineer and Jennifer Chu, Software Engineer
Capital One customers have come to depend on Eno—our intelligent assistant—to check their bank balances, track purchases, pay bills online, and proactively monitor their accounts. This kind of personal, real-time service at scale is one of the hallmarks of our approach to business. Another is our continual quest to use cutting-edge technologies to power those services.
As Eno has grown from its roots as the first natural language SMS chatbot from a U.S. bank to a multichannel solution with numerous capabilities, we’ve identified opportunities to use machine learning to improve the Eno experience even more. One such opportunity presented itself around Eno’s virtual card number (VCN) capabilities. Virtual card numbers are unique, separate credit card numbers for every merchant you shop with. They allow you to transact on your credit card account with that specific merchant and that merchant only, reducing your main credit card number’s exposure to potential card fraud. By using machine learning in the Eno browser extension, could we better detect payment pages and locate payment fields, making our VCNs more accurate and frictionless to use?
How VCNs can transform the cardholder experience
Using virtual card numbers with Eno is simple. When Capital One customers want to make an online purchase, the Eno browser extension can bind a unique virtual card number to a specific merchant in lieu of their physical credit card number. From the point of view of both the cardholder and the merchant, little changes when using a VCN—the VCN is processed as seamlessly as transactions using the actual card number printed on a physical card, and the cardholder earns the same rewards. But the cardholder can rest assured that the VCN will only function for that specific merchant. If that particular online retailer stores a VCN and experiences a breach that exposes the VCN, it can’t be used elsewhere, unlike a traditional credit card number.
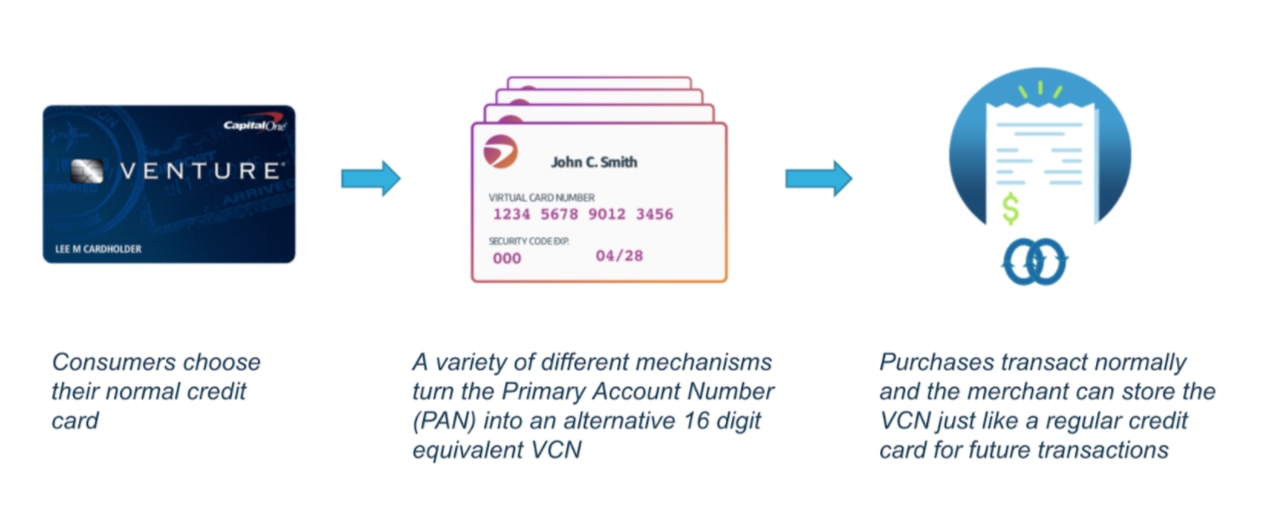
Everything about the VCN process is designed to seamlessly prioritize the security of customer credit card information. Not only does Eno automatically create VCNs at the payment page and populate (autofill) them on the page, but it also simplifies the process of updating expired or lost credit card information, as well as managing subscriptions and automatic charges and fighting fraud.
The potential of using machine learning on Eno’s VCN
The Eno browser extension identifies payment pages and fields using rules, autocomplete xpatterns, and payment processor patterns. Merchant sites use different HTML markup for their payment pages, and they often change that markup. Therefore, Eno’s rules and patterns have to be created, monitored, and maintained for each merchant site or ecommerce platform.
Since our browser extension launched in 2018, numerous feature teams have worked continuously to improve the customer experience. In 2020, one such team saw an opportunity to expand the Eno browser extension’s AI web navigation capabilities by using machine learning to automate the identification of payment fields, reducing the reliance on rules and the manual toil involved in maintaining them. They proposed building a machine learning model to identify payment pages and fields in order to improve Eno’s precision and recall. After all, rules are brittle and can be time consuming to maintain. With rules, we could only build as good of an experience as we could manually scale, since expanding our VCN capabilities to serve additional merchants would be dependent on building rules for those sites and platforms. By leveraging machine learning, they believed we could support more customers, with a better experience, while reducing the engineering work involved in rules maintenance.
Led by a product owner with a vision, this nine person team was largely assembled of engineers– like Jennifer–pulled from the Capital One Technology Development Program (TDP). This program is a two-year rotational program for recent college graduates looking to start their careers in tech. Capital One TDPs are first-class junior engineers–smart, energetic, passionate about making a difference, and unafraid of tackling new technologies. This appetite for challenges and career development opportunities formed the basis of the team as many of the engineers were “volunteers” inspired to join after early stage presentations on the potential of machine learning to revolutionize Eno’s VCN. Jennifer herself originally worked on a different Eno feature team, but was inspired to join this project so she could apply her masters in statistics to an interesting data science challenge. Other team members such as Jocelyn were inspired by the chance to work on exciting machine learning or feature engineering challenges.
I came to Capital One through CODA after double majoring in music and statistics, with a focus in machine learning. Then in CODA I worked on a small, internal project for Capital One Tech College that used natural language processing. Working on the Eno browser extension was amazing, because I and my friends & family could go to the Chrome Store and use the machine learning model I helped build!
The power of perseverance and teamwork in improving Eno’s VCN capabilities
Because this was a feature engineering team and not a machine learning team, the team worked with Erik to develop a plan of action to build the required ML capabilities. His unique role at the time included serving on the Eno leadership team, developing innovative applications of AI/ML, and increasing the impact of machine learning at Capital One by working with teams creating machine learning applications. Tapping his expertise helped them to understand the finer points of ML architectures, as well as the Capital One-specific tooling ecosystems and governance requirements needed to build a well managed model.
Erik first spent time with their product owner and engineering leads figuring out the business case for adding machine learning over rules and patterns. Then came developing metrics to gauge success, and experimenting with the greater team on different approaches. This all followed a comprehensive process, because adding machine learning for its own sake doesn’t necessarily help the customer or the business. For example, sometimes it’s better to use rules rather than machine learning. However, in this case Erik and the team agreed it was not.
When it came time to build, each person on the team had specific tasks to fulfill that played to their strengths, engineering background, and career interests. Parts of the team focused on model training, others on data sampling, other on compliance and governance, and still others on refactoring the code base to allow for the new capabilities. Testing was universal, with the entire team pitching in. In this manner, the entire feature – from collecting metrics to improving the model to preparing the code for shipping – was developed.
We built this through divide and conquer. After a few initial passes, the team split the work into parts that individual engineers could handle. As each part progressed, we kept each other updated and adjusted if any one part needed wider support. This project really showed me that I excel at working on architecture and at the edge. In order to bring the project to our customers, I had to make a number of practical decisions about how we could run and ship what we built in an effective, resilient way. I harnessed everything I knew about maintainable code and automated testing to bring it to a production-ready state; and as I formed a picture of how other engineers would want to improve the code in the future, I was able to decide the best way to set the table for them now.
Using machine learning, DOM, and pixel coordinates for a more accurate VCN experience
In the end, the team settled on the model outlined below. Because deep learning and deep neural networks require extensive training sets, we chose to rely on feature engineering, implementing two logistic regression models in TensorFlow to achieve the desired capabilities. We train the models in Keras and serve the trained models to run under TensorFlow.js in the browser.
- The payment page classification model detects when the customer is on a payment page, so that the Eno browser extension can be popped up. This model takes as input a set of features corresponding to a web page and produces as output whether the page is a payment page (yes or no). The features are constructed by examining the web page’s document object model (DOM). The features are based on text and HTML attributes appearing within the page’s <title> and <head> elements and near those elements. To determine whether some text is near an element, we use the DOM to access the pixel coordinates of the text and element as rendered by the browser on the customer’s screen. We use tf-idf weighting, which weights each term (word or HTML attribute) according to the term frequency—the number of times the term appears in the corpus—offset by the document frequency—the number of documents in the corpus containing the term.
- The payment field classification model classifies input fields within the payment page, so that the Eno browser extension can automatically fill in the appropriate payment information. This model takes as input a set of features corresponding to an <input> or <select> element and produces as output whether the element is a card number field, card security code field, or expiration date field. This model uses HTML attributes of the <input> or <select> element, as well as text near the element based on pixel coordinates.
Compared to using rules and patterns, using machine learning models on text, HTML attributes, and pixel coordinates can more reliably and resiliently identify payment pages and payment fields. Using these models, we can now extend these autofill capabilities to more online sites, more accurately, making VCNs an even easier and less error-prone choice when shopping online.
Using edge machine learning to protect customer data
By using TensorFlow.js, a Javascript library that can run directly in the browser, we can run this machine learning model at the edge—namely on customer devices rather than in the server—helping protect the privacy of customer information and improving response times. Instead of the Eno browser extension having to transmit information to a server to run the machine learning model, the model is run right inside the browser. This provides a lower latency and also increases privacy because information doesn’t have to be transmitted to a server. Edge engineering is nothing new at Capital One, but extending our usage into the machine learning space helps us to provide a new level of convenience and safety through a faster, more accurate understanding of checkout sites.
The future of edge machine learning on the Eno VCN
Improving the VCN experience for the Eno browser extension sprang from multiple goals—to use edge machine learning to improve the Eno customer experience, to create a more secure and fraud-resistant way to shop online, to do so with less manual and brittle efforts, and to help develop the machine learning expertise of our employees and feature teams.
This machine learning model makes the Eno browser extension more robust and our VCNs easier and more secure to use. But our work isn’t finished yet. As the new project lead for this feature, in 2022 Jennifer and her team are focused on data collection and model optimizations – two ways to continually improve and prioritize the customer experience – as well as continual testing of the machine learning feature.

