How to Avoid Coupling in Microservices Design
Doing microservices right by not creating a distributed monolith

Distributed monolith is a somewhat humorous phrase to allude to a not-so-well-designed microservices architecture. By disregarding the best microservices design practices, you have not only failed to overcome the disadvantages of a monolith, but also created new complex problems or intensified the existing ones. And while you can still proudly call it a microservices architecture, the design lacks sufficient intentionality and wouldn’t be so different from if your monolith was shattered into arbitrary pieces by some random explosion. Well, maybe not as bad as that, but you probably understand my point!
The first step towards avoiding a distributed monolith is fairly easy. Avoid microservices altogether. Monoliths are simple, and don’t have the complexity of a distributed system. One database, one log location, one monitoring system, much simpler troubleshooting, and end-to-end testing. But if you have all the right reasons to use microservices, it’s best to adopt them in such a way so that you can always talk proudly about your creation.
In this article, I am going to focus on the importance of loose coupling as a design principle for microservices. I will give examples of poor design decisions that violate loose coupling and lead to distributed monoliths. Life is already difficult. Why would you make it even harder? That’s why I am going to point out some common design mistakes that by avoiding, will make for a much smoother transition to a microservices architecture.
Loose Coupling in Microservices? Tell Me More!
Two systems are loosely coupled if changes to the design, implementation, or behavior in one won’t cause changes in another. When it comes to microservices, coupling can happen if a change to one microservice enforces an almost immediate change to all other microservices that collaborate with it directly or indirectly.
Let’s take a look at some scenarios where coupling could poke a hole in your design.
Database Sharing
Database sharing is a not uncommon form of implementation coupling. Implementation coupling happens when a service has to change its implementation in response to the implementation changes of another service.
The choice of data storage, schema, and query language are implementation details that should be hidden from clients; if you share your database, you will expose them all. Why hide implementation details like these? Implementation details are prone to future changes and can break our customers’ code unless they adopt the same changes simultaneously, which is not always feasible, or sustainable. In the left hand of Figure 1 below, Customers is sharing their database with Orders. As a result, Orders has access to the details of the customer data model, and can potentially break if any of these details change.
What to do instead?
As shown in the right hand of Figure 1 below, one way to remove this coupling is having Customers provide an API which Orders can use to retrieve the customer data. The formatting of this data will stay the same as long as Customers is committed to keeping its current contract up. Orders won’t have any idea where this data is coming from, and Customers can make an autonomous decision about dumping its database into a garbage can and replacing it with a stream data source without being worried about breaking other services.
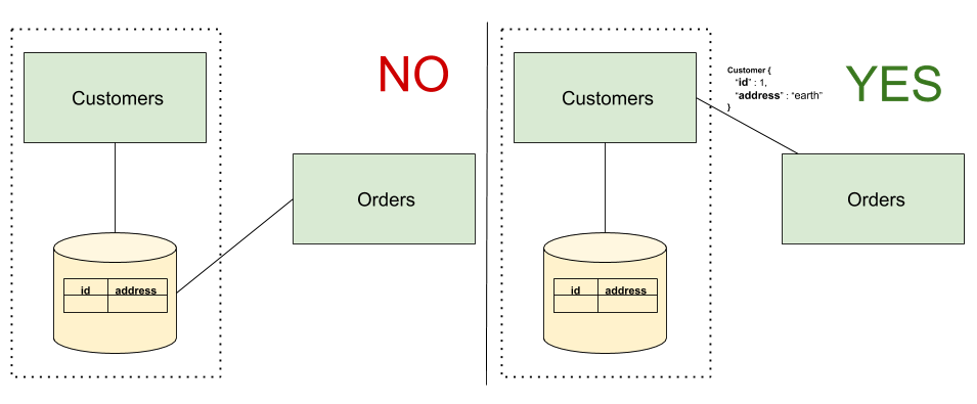
Fig. 1 - Implementation coupling through database sharing
Code Sharing
Despite having independent codebases, microservices can still fall into the trap of implementation coupling by sharing dependency libraries. Apart from the danger of creating coupling, bloated shared libraries with so many dependencies might end up needing frequent updates to fulfill the changing needs of their clients. As a result, shared code has to be as lightweight as possible with limited dependencies, and should exclude domain specific logic.
In the left hand of Figure 2 below, Customers defines the customer object in a library which is shared by Orders. Customers uses this object to model its response to requests for customer data. Orders uses the same object for reading the response body of those requests. If Customers decides to make a change to the internal structure of the customer object, such as breaking the address field into multiple address lines, Orders will break. Note that this anti-pattern could also affect Customers’ choice of programming language. If Customers decides to switch to a different programming language, it has to be considerate of all other services which are using its object model implementation.
What to do instead?
Customers and Orders should each have their own copy of the customers object in separate dependency libraries. As long as Customers stays committed to its contract everyone will be happy!
Remember, you were not hired to keep glueing together a pile of broken services every time that a change happens. You are on a mission to create a flexible architecture, and to ditch the distributed monolith!

Fig. 2 - Implementation coupling through code sharing
Synchronous Communication
Temporal coupling happens when a service - the caller - expects an instantaneous response from another - the callee - before it can resume processing. Since any delay in the response time of the callee would adversely affect the response time of the caller, the callee has to be always up and responsive. This situation usually happens when services use synchronous communication.
As shown in Figure 3 below, the longer it takes for Customers to prepare the data, the longer Orders has to wait before responding to its clients. In other words, a delayed response by Customers results in a delayed response by Orders. Cascading failures is also another possibility; If Customers fails to respond, Orders will eventually timeout and fail responding as well. If Customers continues to be slow or unresponsive for a while, Orders might end up with a lot of open connections to Customers, and eventually run out of memory, and fail! To provide a satisfactory service, Orders should eliminate the ground for temporal coupling. Nobody wants an angry line of customers waiting for their orders to arrive, and the creator of a distributed monolith is no exception.
What to do instead?
The answer depends on whether you are looking for a long-term or a short-term solution. If you have no choice but to keep your synchronous calls in place, you could decrease your temporal dependency by caching the responses to your requests or using the circuit breaker pattern as a mechanism to control cascading failures. A better alternative is to switch to asynchronous communication through polling or by relying on a message broker like Kafka to transfer your messages to their destinations. When adopting asynchronous communication, services should consider how a lag in reaching a state of eventual consistency with their downstream services might affect their response time, and make necessary adjustments to avoid breaking their contracts. Service-level agreements are important parts of a contract.
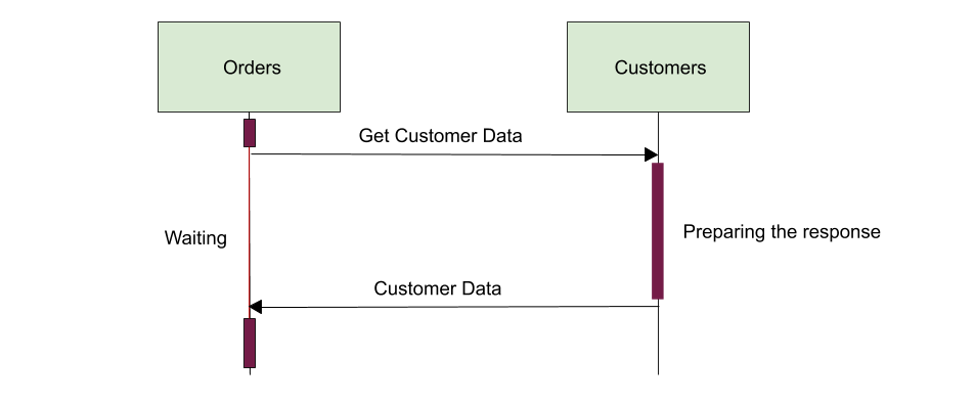
Fig. 3 - Temporal coupling caused by synchronous communication between services
Shared Test Environments
Deployment coupling happens when the continuous integration or continuous delivery of one service is impeded by another one. Microservices are meant to be agile, and having an independent deployment process is a necessity towards reaching that goal.
One prominent example for deployment coupling is when services share the same test environment. Imagine a service that has to pass a brief performance test before its final deployment to production. As a lighter version of the performance tests that run directly in production, this step of the pipeline is designed to test the performance of a release candidate. If this service shares its test environment with another service that happens to run a performance test simultaneously, they might end up taking the test environment down or saturating it by sending unexpectedly high traffic. And the final result? Not a happy one! Deployment failure. Yuck!
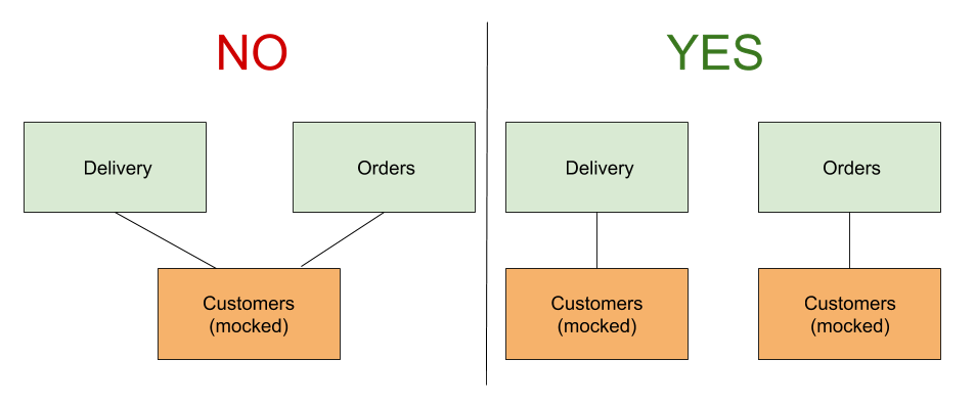
Fig. 4 - Deployment coupling caused by sharing test environments
In the left hand of Figure 4 above, both Delivery and Orders use the same mock of the Customers service for their performance tests. The Orders team originally designed this mocked service to mimic the behavior of Customers given a pre-calculated amount of resources. By adding Delivery to the picture, those calculations are now void and running simultaneous performance tests on both services can cause a deployment failure. Consequently, someone has to reconfigure the mocked service to mimic the same response rate using more resources. This can go on and on as more services start to share the same environment.
What to do instead?
Fairly easy! Do not share your mocked services with anyone.
Hitting Downstream Services for Integration Tests
This is also a form of deployment coupling. It happens when functional tests are run against an instance of a microservice which makes direct calls to its downstream services in a non-test environment - which is hopefully different from production! This dependency creates a need for those downstream services to be up and running for the whole duration of the tests. Any lag in the availability or response time of the downstream services can cause the tests, the build pipeline, and the deployment to fail altogether. That’s a lot of failure for one day!
What to do instead?
Mock your downstream services for integration tests unless you have a really good reason to do otherwise. It would be best if you could containerize and load them on the same instance that hosts your microservice under test to avoid network connectivity issues.
Excessive Sharing of the Domain Data
Domain driven design is a recommended technique for breaking a monolith into microservices. The general rule is to start with one microservice per business subdomain. Each microservice would operate within the boundaries of its subdomain without having to deal with anything outside of it. A utopia where trespassers are not welcome.
If microservices start to share domain specific data they will create a distributed monolith through domain coupling, which defeats the initial purpose of separating their boundaries. A service will not have control over what its clients do with that shared data. A client can inadvertently turn into the source of truth for data that it doesn’t own, or might misuse it due to its lack of domain specific knowledge.
Also, if a service shares too widely it might introduce a security threat by sharing sensitive data. You might have perfect protection around what you consider as sensitive, but there is no guarantee that your clients would do the same because that responsibility or knowledge falls outside of their domain anyways.
Figure 5 below shows an example of domain coupling. In the left hand of the picture, Orders asks for customer data from Customers and receives the customer's credit card number along with their address. It then makes a call to Billing, passing all that data in addition to fee and item id. After Billing charges the customer successfully, Orders sends the same exact set of data fields to Delivery. The right hand of this figure, however, shows the desirable amount of data exchange between these microservices. If designed correctly, Billing should be the only microservice which owns and stores the billing information. It won’t need to receive it from other services.
What to do instead?
Only share the data that your clients absolutely need. If they need something that is outside of their domain boundary, it’s time to rethink your service boundaries.
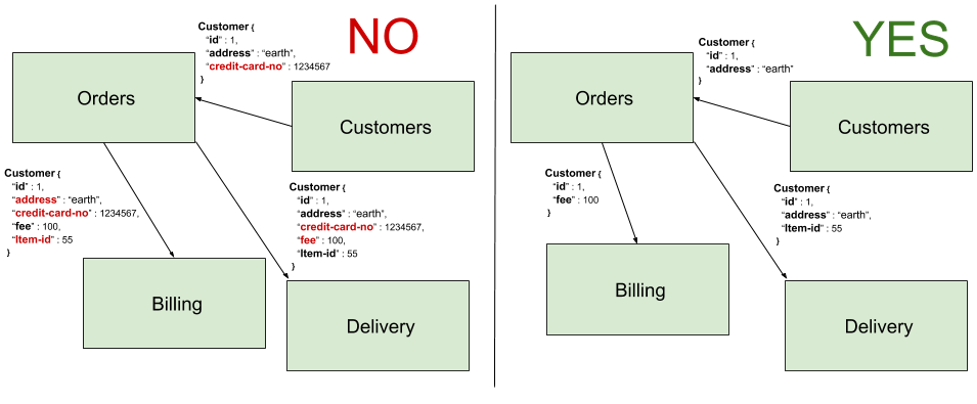
Fig. 5 - Domain coupling through excessive data sharing
Summary
Microservices is a trendy architectural style that if not adopted properly can outweigh its benefits. To avoid a prematurely designed network of microservices, i.e. a distributed monolith, your system needs to be born as a monolith and broken down to the proper set of microservices later down the path.
When migrating your monolith to a microservices architecture, there are many ways that your design could go wrong, and lack of loose coupling is definitely an important one to be mindful of. Coupling can appear in different forms; implementation, temporal, deployment, and domain coupling. In this article we saw examples for each type of coupling, and some suggested solutions to help you avoid each situation thoughtfully. If you already have a distributed monolith, no worries! It’s never too late to take corrective actions by following some of the techniques discussed in this article.
References
Sam Newman (2020), Monolith to Microservices. O'REILLY.
Martin Fowler, How to break a Monolith into Microservices.



