The journey from batch to real-time with change data capture
Using change data capture (CDC) technology to produce consumable data for microservices

In today’s digital era, customers require that services are always available with the most recent data. However, many financial applications across the industry are still batch monoliths and perform batch based processing periodically (often daily), against a presented data set. This creates challenges for data consumers that want to react quickly to data changes as they happen. Ultimately processing can only progress as fast as the slowest dependency.
How can we solve this? Decomposing the monolith into microservices is a start, but if the data publishing is still happening once a day it won’t solve the problem. Using a Reactive Architecture gets you closer to solving the problem as decoupled microservices publish events to an Event Stream. However, the same problem will exist if those events are batched up with microservices. To address the problem, we have to start at the data producer and their data publishing pattern.
In this article, we will discuss taking the microservice reactive pattern a step further by applying the Event Sourcing pattern and using what’s known as Change Data Capture (CDC). CDC is a modern technique that leverages Event Sourcing to stream data updates in real-time as changes are made to a database. This enables microservices consumers to subscribe to a stream and get real-time updates as they occur in a financial application. In this article, we will provide :
- An overview of CDC and Event Sourcing
- Guidance on when to use CDC
- A high level comparison of commonly used CDC technologies including Debezium, and AWS Data Migration Service (DMS)
An overview of Change Data Capture (CDC) and event sourcing
What is change data capture (CDC) ?
CDC originally came about as an alternative to batch based data replication. At one point in time, data replication required systems to go offline as they copied an entire database from source to destination. CDC improved on this by providing continuous replication on much smaller datasets — at the individual event level. Most databases have a transaction log that keeps track of all of the transactions on a database. CDC technologies typically read this transaction log and provide interfaces to stream out the transactions as they happen to stream technologies such as Kafka. Consumer applications then consume them by subscribing to a particular topic.
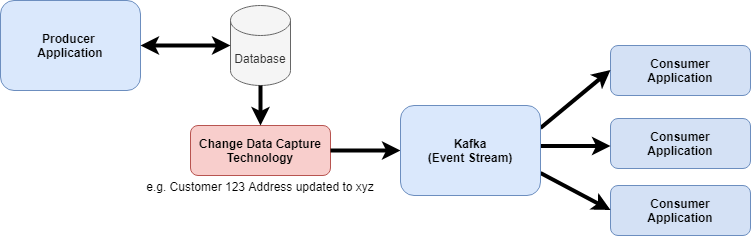
Example flow of CDC
As the transactions are streamed out onto an Event Stream, they are considered Events. This follows a Reactive Architecture style, meaning the consumer applications/microservices can be pre-programmed to react to particular events and are decoupled from the producer. Before service-oriented architecture (SOA) was fully adopted in the tech industry, a common anti-pattern was consumer applications connected directly to the producer application database. This often caused performance issues for the producer, as the consumer ran costly queries against the producers operational database. Additionally, it tightly coupled the consumer to the producer’s data model. Whenever the producer made a change, the consumer had to change otherwise they broke. This also resulted in a lack of transparency of how the producer’s data was being consumed. With the SOA and Microservice architectural styles, we always want to decouple the producer and consumer by leveraging an interface with a contract to provide a degree of abstraction. In the example illustration above, the abstraction is Kafka, but it could just as easily be an API.
What is Event Sourcing?
As mentioned earlier, CDC technologies are a way for producers to publish individual data transactions as they occur to their database as events. We can apply the Event Sourcing pattern to get further benefits. Per Martin Fowler’s definition, Event Sourcing is storing all changes to application state as a sequence of events. This sequence of events can then be replayed to get the current state. Events are immutable meaning they cannot be changed. If their state needs to change then a new event is added. Kafka is a great choice for Event Sourcing implementations as it is persistent. When a message is read from Kafka, it is not destroyed. Rather, it stays within Kafka based on the configured retention policy. This makes it possible to do event replay.
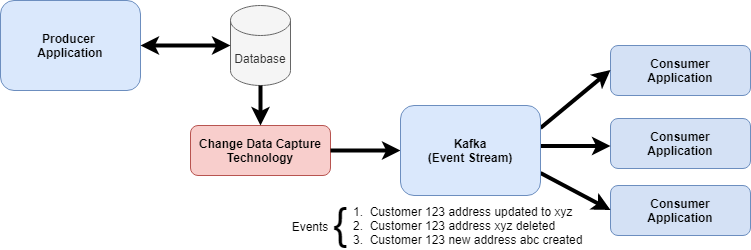
Example of Event Sourcing
The concept of Event Sourcing has been around for centuries in different forms. Legal contracts are a common example. Contracts are not re-written rather they are amended. Another Event Sourcing example is the game of chess. With Event Sourcing, we record each move a player makes. At any point in time you can replay all of their moves to get the current state of the board. It is a great pattern for use cases where auditability of individual changes to state is a requirement. Once a certain number of events are produced, we will want to produce a snapshot event record . This provides a current state view and saves consumers time when replaying events. Imagine if you had billions of events in an Event Stream. You would not want to replay every event, every time to get the current state. Rather, you would want to work back from the latest snapshot.
In summary, CDC is a way to generate state changes as events from a database, while Event Sourcing is a pattern that captures individual events that can be replayed to get current state.
Guidance on when to use CDC
In some cases using CDC is an anti-pattern. For example, if building a new application, I would not use CDC. Rather, I would design the microservices and the data by bounded context using Domain Driven Design/Event Storming. Each microservice would publish its events to a stream, in addition to storing certain data elements to its data store (if needed). Instead of having the database publish the events via CDC, the microservice would publish the events. The advantage with this approach is the microservice can translate the event into a more readable business event. CDC events that are reading the database from a commercial off-the-shelf product often require interpretation. Yes, you can have a process read the CDC event off of the stream, translate it and publish it back, but that is an extra processing hop. Why not have the producer own that translation and publish it from the beginning. Additionally, there can be a small latency with CDC from the time a database update occurs until when the CDC event is published into the event stream. This can depend on the database update happening and the number of hops to get to the event stream.
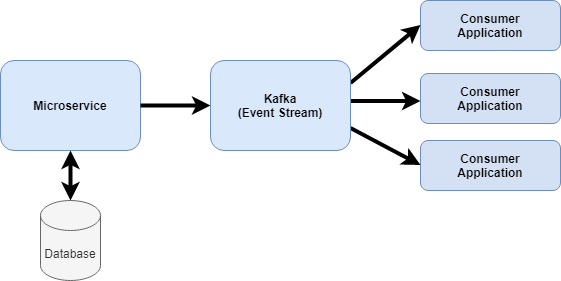
Example of a microservice publishing events to Kafka
I have found CDC is a better fit for existing applications, where transforming a monolith into microservices is either further down the road or the application is a custom off the shelf product that can’t be modified. It also enables a parallel adoption approach where consumers can migrate to the new pattern at their own pace. In these scenarios, there are several factors to consider to determine if CDC is a fit.
- Consumers desire incremental data updates. If consumers only need current state and not the detailed updates, then CDC isn’t needed.
- Consumers desire real-time data updates. This one may be obvious, but if consumers only need the data once a day or less frequent, then CDC isn’t needed. It’s like paying for that monthly magazine subscription that you never read.
- Data Producers can adapt to CDC. If the source of your data is on a data producer that is out of your control, such as a 3rd party vendor, they have to be willing to adopt CDC. Streaming events from daily batch files will achieve data decomposability, however the events will be stale. The goal is to stream the events as soon as they occur to enable microservices to react to them in real-time.
- Consumers are OK with replaying events to get the current state. It’s very important that consumers understand that to get the current state they will have to replay events. If some consumers are OK with this and others are not, one approach is to have a separate service that generates and publishes the current state based off of the CDC events.
These are some of the key reasons for when you’d use CDC. Next, we will compare and contrast several common CDC technologies.
Comparison of commonly used CDC technologies
In this section, we will compare two common CDC technologies in the industry: Debezium and Amazon (AWS) Data Migration Service (DMS). We will compare them across these dimensions:
- Operating model (e.g. Open Source, Cloud Based Managed Service)
- Maturity
- Databases supported
- Native Stream integration
AWS Data Migration Service
Let’s start with AWS DMS, which is a Cloud Based Managed Service on AWS. AWS DMS is primarily known for its data migration capability that enables migrating a database to AWS. In June 2018, AWS DMS launched support for CDC, and AWS continues to improve it every year. The way it works is by reading the database transaction log via APIs. This transaction log records all changes made to the database. It uses the Event Sourcing pattern we discussed earlier. As of early 2021, it supports a number of databases including Oracle, SQL Server, MySQL, and Amazon Aurora. One of its unique capabilities is it can switch over from database replication to CDC at a particular point in time. This can be valuable if you need a one time sync from another source before switching over to CDC. From a native stream integration standpoint, Kinesis Data Streams is a supported target for AWS DMS. This means AWS DMS can send CDC events directly to Kinesis. Originally, AWS DMS required a lambda to integrate with Kinesis, however this was later enhanced to support direct integration with Kinesis. Below is an illustration from Amazon that shows the integration possibilities:
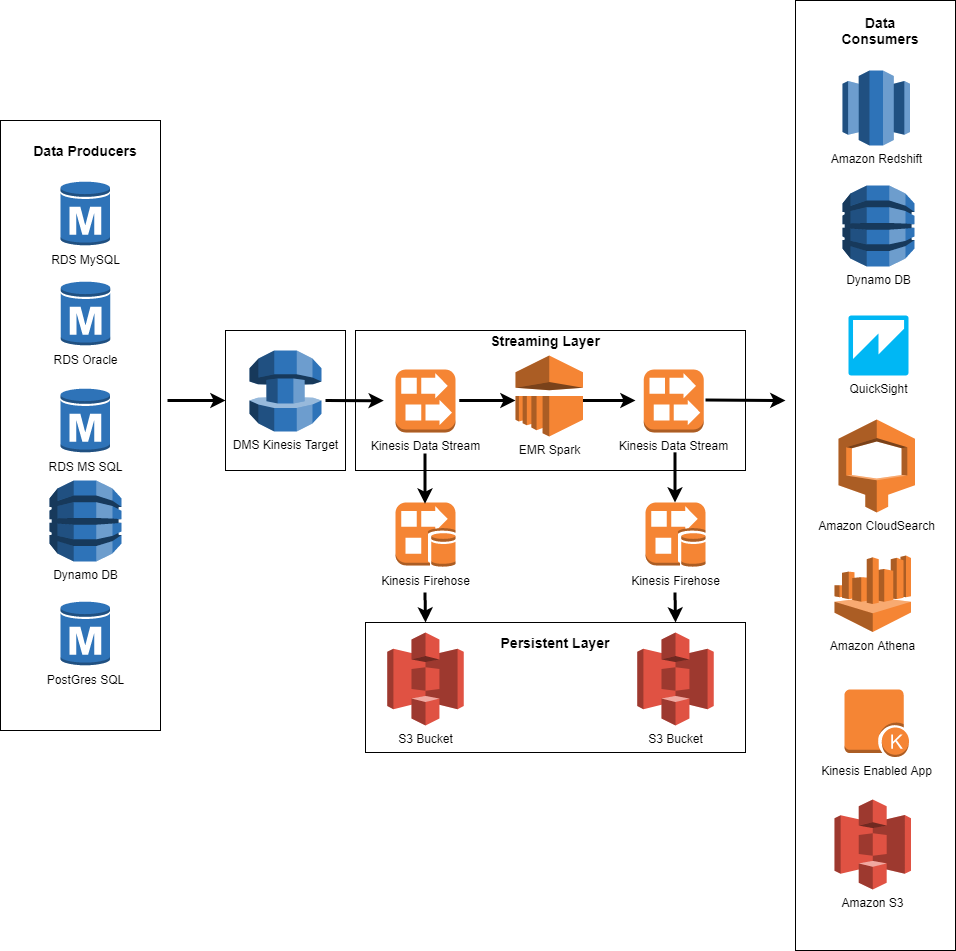
Example integration options with AWS DMS
Debezium
Now let’s take a look at another CDC technology in the industry, Debezium. Debezium is an open source (Apache 2.0) technology specifically created for CDC. Its first release was May 2019 and as of early 2021 has a highly active open source community, with over 266 contributors. Similar to AWS DMS, it reads the database transaction logs to get the changes. However, it’s different in that it provides two high level options for reading the data.
Option #1
One is to use the built in Kafka Connect capability that enables source connectors such as Kafka and sink connectors that read events from Kafka topics and send them to other systems. Kafka is an open source distributed streaming product known for its high performance, fault tolerance, scalability, and reliability and comes as part of this deployment option. Applications can subscribe to the CDC events via Kafka topics (usually one topic per database table).

Example (https://debezium.io/documentation/reference/architecture.html) of using Debezium with Kafka Connect. Copyright Debezium Community. Licensed under the Apache 2.0 License.
Option #2
The second option is for applications to leverage the Debezium embedded connector engine in their application. This approach does not leverage Kafka or Kafka Connect, rather enables the application to receive the real-time database updates in-memory. This approach may provide better performance, but couples the producer with the consumer whereas leveraging the former Kafka approach provides a layer of abstraction that decouples the producer and consumer. Similar to AWS DMS, Debezium supports a number of databases including MySQL, MongoDB, PostgreSQL, and SQL Server.
When to use AWS DMS vs. Debezium
Now that we’ve done a very high level comparison of these two technologies, when would you use one over the other? If the operating models of both are a valid option for your environment, then ultimately it depends on your use case. I recommend evaluating if your database is supported and if you have a preference on native stream integration (e.g. Kinesis or Kafka). Determine if you need to do a full database replication prior to switching over to CDC. Also, assess if the Debezium embedded connector engine is a fit. It is a simpler solution, but be aware of the trade off in coupling. If you are still undecided at that point I’d recommended evaluating the features to see if there are any differentiators for your use case. Below is a side by side feature comparison based on high level feature comparison between Debezium and AWS DMS.
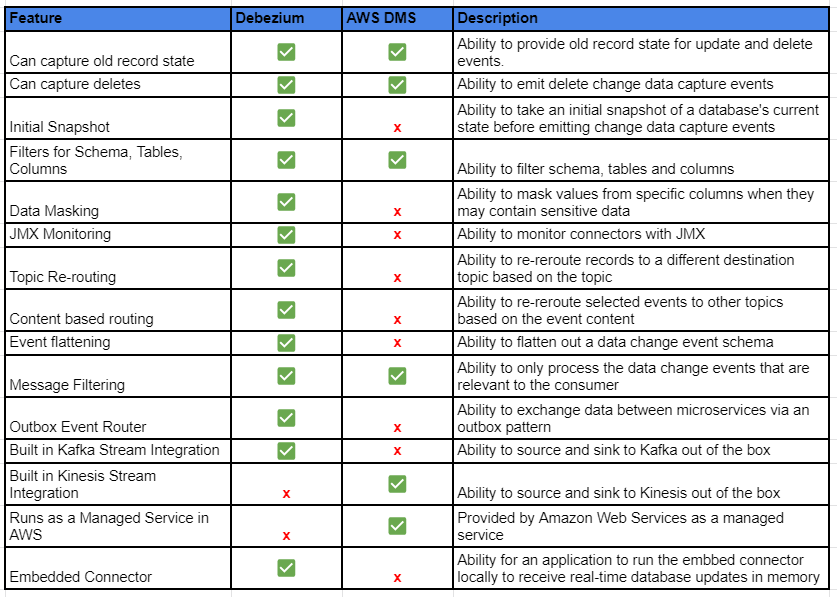
Summary
CDC is a powerful technique that can transform the batch data of a monolithic application into real-time events, moving you forward in your journey to microservices. When used to solve the right problem, it is very powerful. I hope you found this article informative and best of luck in converting your monolith from batch to real-time!



